Spark2.4.5集群安装与本地开发
下载
官网地址:https://www.apache.org/dyn/closer.lua/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
验证Java是否安装
java -verison
解压安装
tar -zxvf jdk-14.0.1_linux-x64_bin.tar.gz
mv jdk-14.0.1 /usr/local/java
验证Scala是否安装
scala -verison
wget https://downloads.lightbend.com/scala/2.13.1/scala-2.13.1.tgz
tar xvf scala-2.13.1.tgz
mv scala-2.13.1 /usr/local/
- 设置jdk与scala的环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/java
export SPARK_HOME=/usr/local/spark
export CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH:$SPARK_HOME/bin
source /etc/profile
- 再次验证一下是否安装成功
scala -version
java -verison
安装spark
- 解压并移动到相应的目录
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz
mv spark-2.4.5-bin-hadoop2.7 /usr/local/spark
- 设置spark环境变量
vi /etc/profile
export PATH=$PATH:/usr/local/spark/bin
保存,刷新
source /etc/profile
- 验证一下spark shell
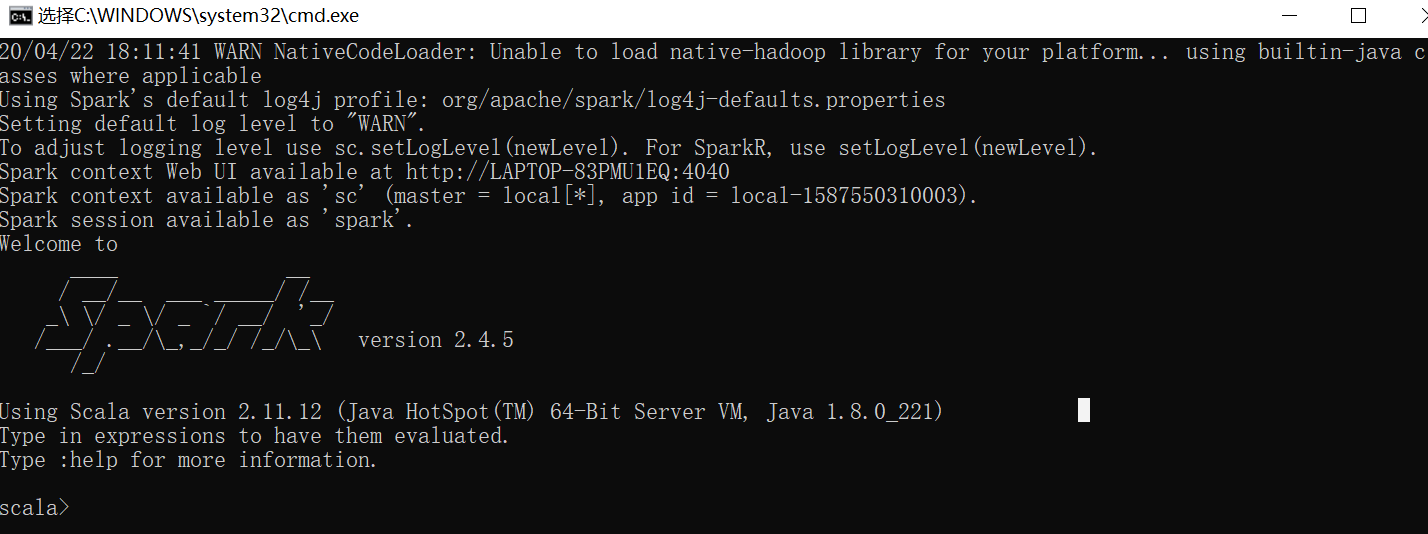
spark-shell
出现以下信息,即成功

设置Spark主结点
spark配置都提供了相应的模板配置,我们复制一份出来
cd /usr/local/spark/conf/
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
- 设置主结点Master的IP
SPARK_MASTER_HOST='192.168.56.109'
JAVA_HOME=/usr/local/java
- 如果是单机启动
./sbin/start-master.sh
- 打开 http://192.168.56.109:8080/
出现以下界面即成功:

- 停止
./sbin/stop-master.sh
- 设置hosts
192.168.56.109 master
192.168.56.110 slave01
192.168.56.111 slave02
免密登录
Master上执行
ssh-keygen -t rsa -P ""
生成三个文件

将id_rsa.pub复制到slave,注意authorized_keys就是id_rsa.pub,在slave机器上名为authorized_keys,操作
scp -r id_rsa.pub root@192.168.56.110:/root/.ssh/authorized_keys
scp -r id_rsa.pub root@192.168.56.111:/root/.ssh/authorized_keys
cp id_rsa.pub authorized_keys
到slava机器上
chmod 700 .ssh
- 检查一下是否可以免密登录到slave01,slave02
ssh slave01
ssh slave02
Master与Slave配置worker结点
cd /usr/local/spark/conf
cp slaves.template slaves
加入两个slave,注意:slaves文件中不要加master,不然master也成为一个slave结点
vi slaves
slave01
slave02
Master结点启动
cd /usr/local/spark
./sbin/start-all.sh
如果出现 JAVA_HOME is not set 错误,则需要在slave结点的配置目录中的spark-env.sh中加入JAVA_HOME=/usr/local/java
如果启动成功访问:http://192.168.56.109:8080/,会出现两个worker
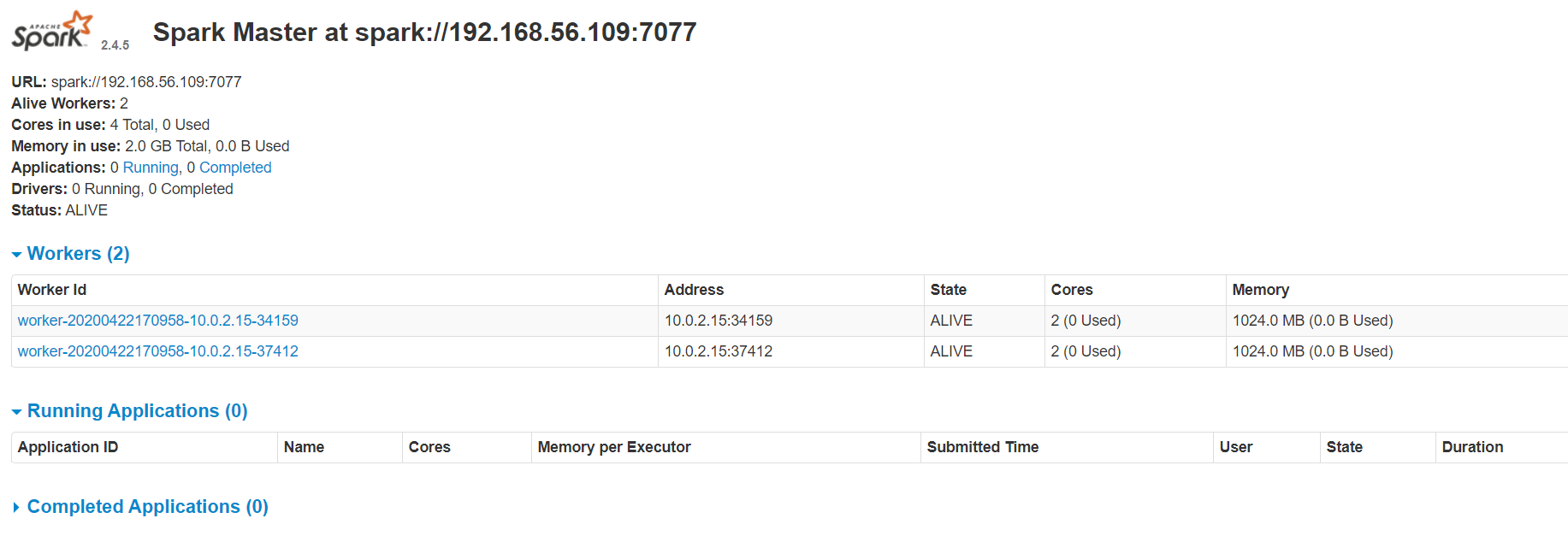
本地开发
将上面spark-2.4.5-bin-hadoop2.7解压到本地,到bin目录双击spark-shell.cmd,不出意外应该会报错
Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
错误原因是因为没有下载Hadoop windows可执行文件。因为我们本地没有hadoop环境,这里可以用winutils来模拟,并不需要我们真的去搭建hadoop
可以到这里下载,如果要下载其它版本的可以自行选择
- 设置本机环境变量

再次重启,可以看到如下信息即成功
idea里Run/Debug配置里加入以下环境变量

idea里还需要加入scala插件,后面可以愉快的用data.show()查看表格了


请关注,后续有更精彩的文章分享

> 本文由博客一文多发平台 [OpenWrite](https://openwrite.cn?from=article_bottom) 发布!
Spark2.4.5集群安装与本地开发的更多相关文章
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- Spark2.1集群安装(standalone模式)
机器部署 准备三台Linux服务器,安装好JDK1.7 下载Spark安装包 上传spark-2.1.0-bin-hadoop2.6.tgz安装包到Linux(intsmaze-131)上 解压安装包 ...
- linux安装spark-2.3.0集群
(安装spark集群的前提是服务器已经配置了jdk并且安装hadoop集群(主要是hdfs)并正常启动,hadoop集群安装可参考<hadoop集群搭建(hdfs)>) 1.配置scala ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- spark集群安装并集成到hadoop集群
前言 最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置 本篇博客主要说明,如果搭建spark集群并集 ...
- CentOS7.5搭建spark2.3.1集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
- 3 Spark 集群安装
第3章 Spark集群安装 3.1 Spark安装地址 1.官网地址 http://spark.apache.org/ 2.文档查看地址 https://spark.apache.org/docs/2 ...
- CentOS下Hadoop-2.2.0集群安装配置
对于一个刚开始学习Spark的人来说,当然首先需要把环境搭建好,再跑几个例子,目前比较流行的部署是Spark On Yarn,作为新手,我觉得有必要走一遍Hadoop的集群安装配置,而不仅仅停留在本地 ...
- Hadoop多节点集群安装配置
目录: 1.集群部署介绍 1.1 Hadoop简介 1.2 环境说明 1.3 环境配置 1.4 所需软件 2.SSH无密码验证配置 2.1 SSH基本原理和用法 2.2 配置Master无密码登录所有 ...
随机推荐
- file_put_contens小trick
file_put_contents tricks 0x01 trick1 来自于P神的实例: <?php $text = $_GET['text']; if(preg_match('[<& ...
- 图解Knative核心组件Serving基础设计
最近闲下来,打算把Knative的核心组件Serving给学习下,会继续采用k8s源码学习的方式,管中窥豹以小击大,学习serving的主要目标: 可观测性基础设施.自动伸缩.流量管理等核心组件的设计 ...
- MVC-基础02
MVC是Model(模型).View(视图)和Controller(控制). 1)最上面的一层,是直接面向最终用户的"视图层"(View).它是提供给用户的操作界面,是程序的外壳. ...
- ES6中的let关键字,有什么用呢?
来吧,开始本节的学习! ES6 给开发者带来很多令人激动的特性,其中let关键字就是其中之一. 那么,let关键字是什么东西? let 的用途 我们回想一下,我们平时在写代码的时候,用var来声明一个 ...
- metaspliot(一)
来自山丘安全实验室 陈毅 https://www.cnblogs.com/sec875/articles/12243725.html linux下载与更新 apt-get update apt-get ...
- urlencode()和rawurlencode()区别
urlencode和rawurlencode两个方法在处理字母数字,特殊符号,中文的时候结果都是一样的 ,唯一的不同是对空格的处理, urlencode处理成“+”, rawurlencod ...
- php---算法和数据结构
<?php header("content-type:text/html;charset=utf-8"); $arr = array(3,5,8,4,9,6,1,7,2); ...
- SQLI-LABS学习笔记(三)
第十一关 这一关是POST注入 先利用bp抓包抓到post传输的参数数据 抓到传递的表单为 uname=admin&passwd=admin&submit=Subm ...
- Python 删除含有只读文件(夹)的文件夹
def rm_read_only(fn, tmp, info): if os.path.isfile(tmp): os.chmod(tmp, stat.S_IWRITE) os.remove(tmp) ...
- QT 无法抓住异常
出处:https://stackoverflow.com/questions/40980171/qt5core-dll-crashing I've found that enabling /EHa ( ...