sparkRDD:第3节 RDD常用的算子操作
4. RDD编程API
4.1 RDD的算子分类
Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD;例如:一个rdd进行map操作后生了一个新的rdd。
Action(动作):对rdd结果计算后返回一个数值value给驱动程序,或者把结果存储到外部存储系统(例如HDFS)中;
例如:collect算子将数据集的所有元素收集完成返回给驱动程序。
4.2 Transformation
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作或者将结果写入到外存储中,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
常用的Transformation:
|
转换 |
含义 |
|
map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
|
mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
|
union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
|
intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
|
distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
|
groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
|
sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
|
cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
|
coalesce(numPartitions) |
减少 RDD 的分区数到指定值。 |
|
repartition(numPartitions) |
重新给 RDD 分区 |
|
repartitionAndSortWithinPartitions(partitioner)
|
重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
4.3 Action
|
动作 |
含义 |
|
reduce(func) |
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
|
collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
|
count() |
返回RDD的元素个数 |
|
first() |
返回RDD的第一个元素(类似于take(1)) |
|
take(n) |
返回一个由数据集的前n个元素组成的数组 |
|
takeOrdered(n, [ordering]) |
返回自然顺序或者自定义顺序的前 n 个元素 |
|
saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
|
saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
|
saveAsObjectFile(path) |
将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
|
countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
|
foreach(func) |
在数据集的每一个元素上,运行函数func |
|
foreachPartition(func) |
在数据集的每一个分区上,运行函数func |
5. RDD常用的算子操作
Spark Rdd的所有算子操作,请见《sparkRDD函数详解.docx》
启动spark-shell 进行测试:
spark-shell --master spark://node1:7077
练习1:map、filter
//通过并行化生成rdd
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
//对rdd1里的每一个元素乘2然后排序
val rdd2 = rdd1.map(_ * 2).sortBy(x => x, true)
//过滤出大于等于5的元素
val rdd3 = rdd2.filter(_ >= 5)
//将元素以数组的方式在客户端显示
rdd3.collect
练习2:flatMap
val rdd1 = sc.parallelize(Array("a b c", "d e f", "h i j"))
//将rdd1里面的每一个元素先切分在压平
val rdd2 = rdd1.flatMap(_.split(" "))
rdd2.collect
练习3:交集、并集
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
//求并集
val rdd3 = rdd1.union(rdd2)
//求交集
val rdd4 = rdd1.intersection(rdd2)
//去重
rdd3.distinct.collect
rdd4.collect
练习4:join、groupByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//求join
val rdd3 = rdd1.join(rdd2)
rdd3.collect
//求并集
val rdd4 = rdd1.union(rdd2)
rdd4.collect
//按key进行分组
val rdd5=rdd4.groupByKey
rdd5.collect
练习5:cogroup
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("jim", 2)))
//cogroup
val rdd3 = rdd1.cogroup(rdd2)
//注意cogroup与groupByKey的区别
rdd3.collect
练习6:reduce
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))
//reduce聚合
val rdd2 = rdd1.reduce(_ + _)
rdd2.collect
练习7:reduceByKey、sortByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
//按key进行聚合
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect
//按value的降序排序
val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1))
rdd5.collect
练习8:repartition、coalesce
val rdd1 = sc.parallelize(1 to 10,3)
//利用repartition改变rdd1分区数
//减少分区 结果为2
rdd1.repartition(2).partitions.length 或 rdd1.repartition(2).partitions.size
//增加分区 结果为4
rdd1.repartition(4).partitions.size
//利用coalesce改变rdd1分区数
//减少分区 结果为2
rdd1.coalesce(2).partitions.size
//减少分区 结果为3,不会增加到4
rdd1.coalesce(4).partitions.size
注意:repartition可以增加和减少rdd中的分区数,coalesce只能减少rdd分区数,增加rdd分区数不会生效。
repartition实际上调用了coalesce方法,等价于coalesce(num,true), coalesce方法的第2个参数默认为false。
RDD编程实战:
一、 通过spark实现点击流日志分析案例
详见代码。
一、 通过Spark实现ip地址查询
1. 需求分析
在互联网中,我们经常会见到城市热点图这样的报表数据,例如在百度统计中,会统计今年的热门旅游城市、热门报考学校等,会将这样的信息显示在热点图中。
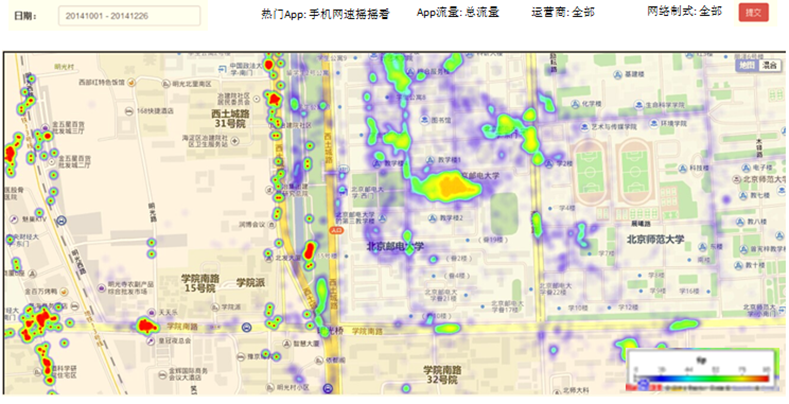
因此,我们需要通过日志信息(运行商或者网站自己生成)和城市ip段信息来判断用户的ip段,统计热点经纬度。
2. 技术调研
因为我们的需求是完成一张报表信息,所以对程序的实时性没有要求,所以可以选择内存计算spark来实现上述功能。
3. 架构设计
搭建spark集群
4. 开发流程
4.1. 数据准备
4.2. ip日志信息
在ip日志信息中,我们只需要关心ip这一个维度就可以了,其他的不做介绍

4.3. 城市ip段信息

5. 代码开发
5.1. 思路
1、加载城市ip段信息,获取ip起始数字和结束数字,经度,维度
2、加载日志数据,获取ip信息,然后转换为数字,和ip段比较
3、比较的时候采用二分法查找,找到对应的经度和维度

4、然后对经度和维度做单词计数
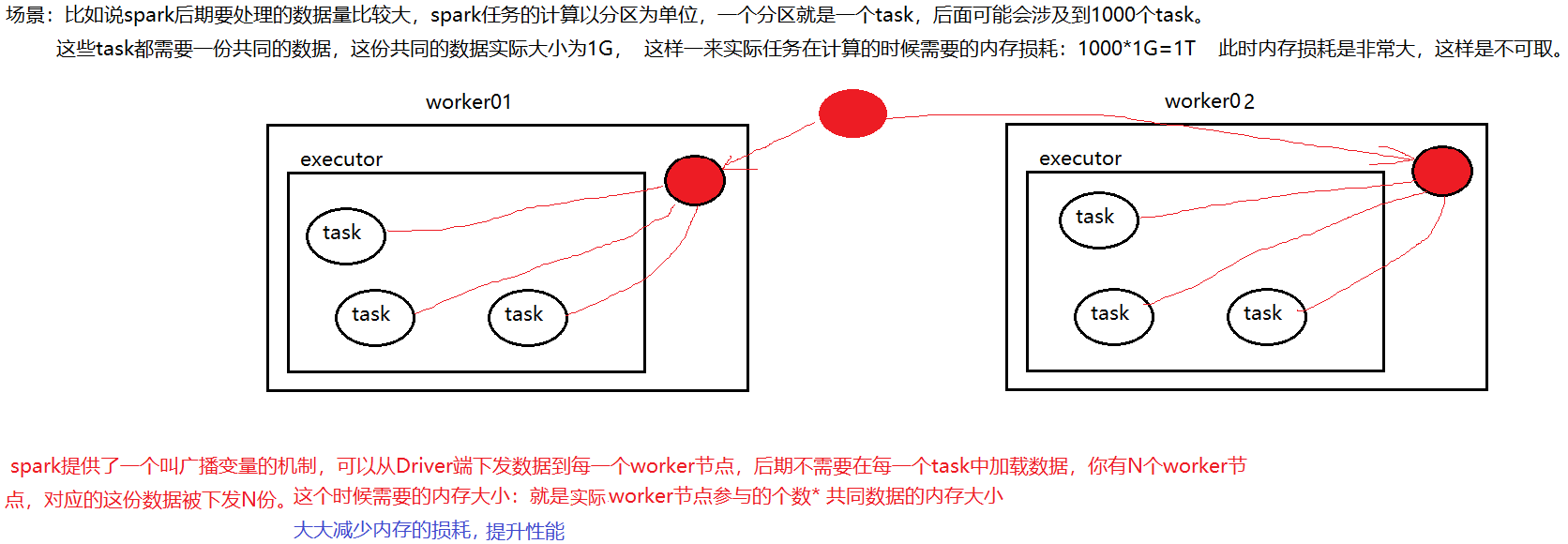
------------------------------------
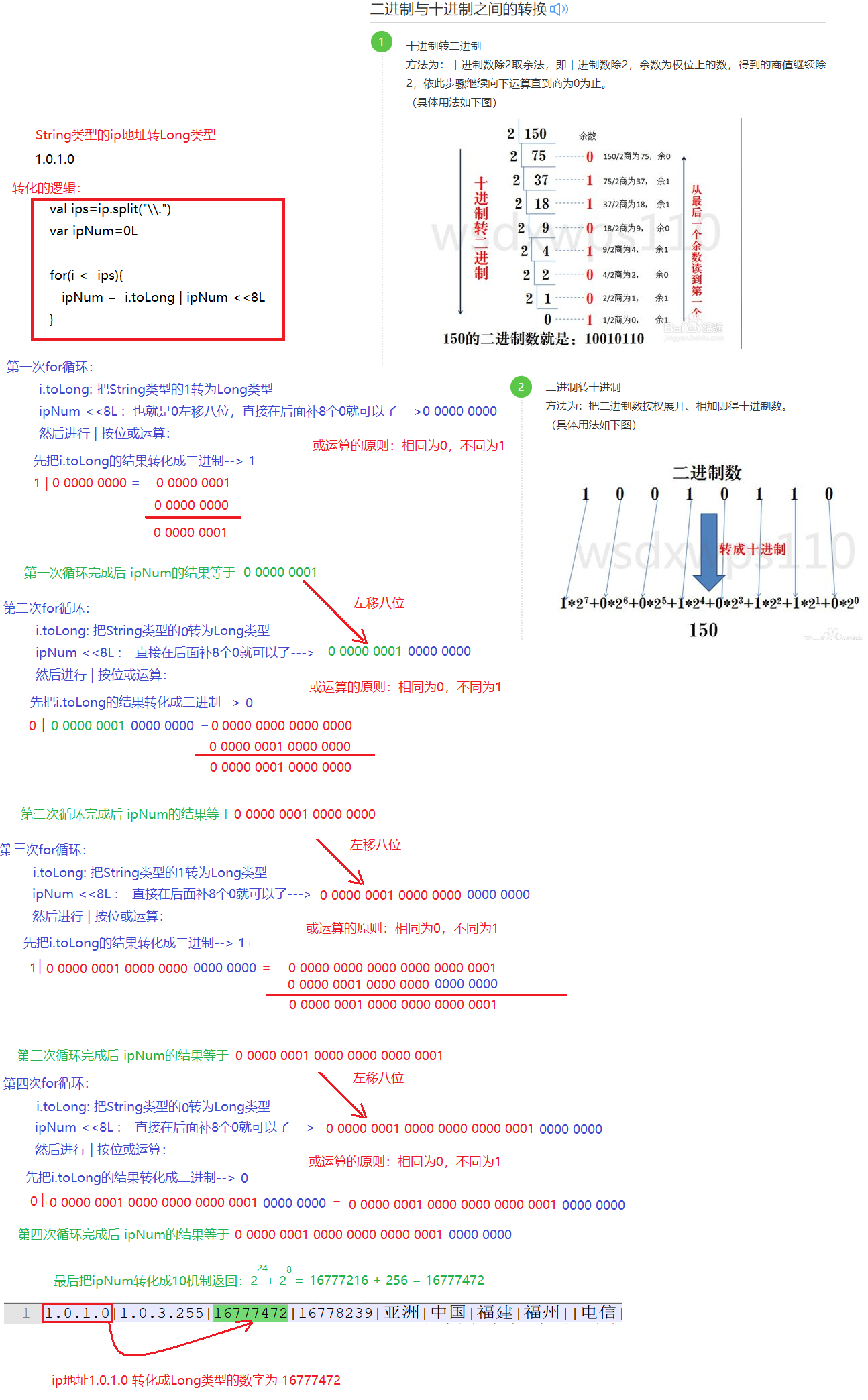
5.2. 代码
详见代码。
sparkRDD:第3节 RDD常用的算子操作的更多相关文章
- Spark Core核心----RDD常用算子编程
1.RDD常用操作2.Transformations算子3.Actions算子4.SparkRDD案例实战 1.Transformations算子(lazy) 含义:create a new data ...
- Spark—RDD编程常用转换算子代码实例
Spark-RDD编程常用转换算子代码实例 Spark rdd 常用 Transformation 实例: 1.def map[U: ClassTag](f: T => U): RDD[U] ...
- 常用Actoin算子 与 内存管理 、共享变量、内存机制
一.常用Actoin算子 (reduce .collect .count .take .saveAsTextFile . countByKey .foreach ) collect:从集群中将所有的计 ...
- 常用Transformation算子
map 产生的键值对是tupple, split分隔出来的是数组 一.常用Transformation算子 (map .flatMap .filter .groupByKey .reduc ...
- 关于spark RDD trans action算子、lineage、宽窄依赖详解
这篇文章想从spark当初设计时为何提出RDD概念,相对于hadoop,RDD真的能给spark带来何等优势.之前本想开篇是想总体介绍spark,以及环境搭建过程,但个人感觉RDD更为重要 铺垫 在h ...
- spark——详解rdd常用的转化和行动操作
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark第三篇文章,我们继续来看RDD的一些操作. 我们前文说道在spark当中RDD的操作可以分为两种,一种是转化操作(trans ...
- 【Spark篇】---SparkStreaming算子操作transform和updateStateByKey
一.前述 今天分享一篇SparkStreaming常用的算子transform和updateStateByKey. 可以通过transform算子,对Dstream做RDD到RDD的任意操作.其实就是 ...
- SparkStreaming算子操作,Output操作
SparkStreaming练习之StreamingTest,UpdateStateByKey,WindowOperator 一.SparkStreaming算子操作 1.1 foreachRDD 1 ...
- 第一百二十六节,JavaScript,XPath操作xml节点
第一百二十六节,JavaScript,XPath操作xml节点 学习要点: 1.IE中的XPath 2.W3C中的XPath 3.XPath跨浏览器兼容 XPath是一种节点查找手段,对比之前使用标准 ...
随机推荐
- python 处理form/data文件上传
处理multipart/form-data 的java serverlet请求接口通过python实现 记住不要在头加:"Content-Type":"multipart ...
- document删除元素(节点)
不需要获取父id:document.getElementById("id").parentNode.removeChild(document.getElementById(&quo ...
- SDNU_ACM_ICPC_2020_Winter_Practice_4th
H - Triangle 思路:用了斐波那契数列,因为数列中的任意三数都无法组成三角形,所以将1,2,3,,,n变成斐波那契数列就符合条件: #include <iostream> u ...
- HTML+CSS—背景图片、图片定位
设置背景图片格式: background-image: url(img/ic.jpg); 注意点: 如果父容器面积大于背景图片,默认显示该图片整面平铺 设置是否需要平铺属性: background-r ...
- 【Struts 分派Action】DispatchAction
LoginAction package k.action; import k.form.UserForm; import org.apache.struts.action.ActionForm; im ...
- 关于React Native init 项目时候速度太慢的解决方法
因为init项目的时候需要下载资源,但又因为react native的网站被墙所以下载很慢,解决方法就是换成淘宝的NPM镜像 我是直接使用了命令去替换了NPM $ npm install -g cnp ...
- mcast_set_loop函数
#include <errno.h> #include <sys/socket.h> #include <net/if.h> #include <netine ...
- KK音标
目录 KK音标 参考 音标发音 音标口诀 五个规则 KK音标
- 嵌入式大赛PPT
题目:基于SLAM的移动机器人设计 嵌入式PPT应具有的几个部分 1.有哪些硬件 1)小车 2)STM32F429开发板 3)树莓派3b+开发板 4)4g通信模块 5)GPS模块 6)Kinect摄像 ...
- DVWA实验之Brute Force(暴力破解)- Medium
DVWA实验之Brute Force(暴力破解)- Medium 有关DVWA环境搭建的教程请参考: https://www.cnblogs.com/0yst3r-2046/p/10928380. ...