Spark原始码系列(五)分布式缓存
问题导读:spark缓存是如何实现的?BlockManager与BlockManagerMaster的关系是什么?

这个persist方法是在RDD里面的,所以我们直接打开RDD这个类。
def persist(newLevel: StorageLevel): this.type = {
// StorageLevel不能随意更改
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel) {
throw new UnsupportedOperationException("Cannot change storage level of an RDD after it was already assigned a level")
}
sc.persistRDD(this)
// Register the RDD with the ContextCleaner for automatic GC-based cleanup
// 注册清理方法
sc.cleaner.foreach(_.registerRDDForCleanup(this))
storageLevel = newLevel
this
}
它调用SparkContext去缓存这个RDD,追杀下去。
private[spark] def persistRDD(rdd: RDD[_]) {
persistentRdds(rdd.id) = rdd
}
它居然是用一个HashMap来存的,具体看这个地图的类型是TimeStampedWeakValueHashMap [Int,RDD [_]]类型。把存进去的值都隐式转换成WeakReference,然后加到一个内部的一个ConcurrentHashMap里面。这里貌似也没干干啥,这是有个鸟蛋用。。大神莫喷,知道干啥用的人希望告诉我一下。
1、 CacheManager
现在并没有保存,等到真正运行Task运行的时候才会去缓存起来。入口在Task的runTask方法里面,具体的我们可以看ResultTask,它调用了RDD的iterator方法。
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
computeOrReadCheckpoint(split, context)
}
}
一旦设置了StorageLevel,就要从SparkEnv的cacheManager取数据。
def getOrCompute[T](rdd: RDD[T], split: Partition, context: TaskContext, storageLevel: StorageLevel): Iterator[T] = {
val key = RDDBlockId(rdd.id, split.index)
blockManager.get(key) match {
case Some(values) =>
// 已经有了,直接返回就可以了
new InterruptibleIterator(context, values.asInstanceOf[Iterator[T]])
case None =>
// loading包含这个key表示已经有人在加载了,等到loading被释放了,就可以去blockManager里面取到了
loading.synchronized {
if (loading.contains(key)) {
while (loading.contains(key)) {
try {
loading.wait()
} catch {
case e: Exception =>
logWarning(s"Got an exception while waiting for another thread to load $key", e)
}
}
// 别人成功拿到了,我们直接取结果就是了,如果别人取失败了,我们再来取一次
blockManager.get(key) match {
case Some(values) =>
return new InterruptibleIterator(context, values.asInstanceOf[Iterator[T]])
case None =>
loading.add(key)
}
} else {
loading.add(key)
}
}
try {
// 通过rdd自身的compute方法去计算得到结果,回去看看RDD那文章,自己看看源码就清楚了
val computedValues = rdd.computeOrReadCheckpoint(split, context)
// 如果是本地运行的,就没必要缓存了,直接返回即可
if (context.runningLocally) {
return computedValues
}
// 跟踪blocks的更新状态
var updatedBlocks = Seq[(BlockId, BlockStatus)]()
val returnValue: Iterator[T] = {
if (storageLevel.useDisk && !storageLevel.useMemory) {
/* 这是RDD采用DISK_ONLY的情况,直接扔给blockManager
* 然后把结果直接返回,它不需要把结果一下子全部加载进内存
* 这同样适用于MEMORY_ONLY_SER,但是我们需要在启用它之前确认blocks没被block store给丢弃 */
updatedBlocks = blockManager.put(key, computedValues, storageLevel, tellMaster = true)
blockManager.get(key) match {
case Some(values) =>
values.asInstanceOf[Iterator[T]]
case None =>
throw new Exception("Block manager failed to return persisted valued")
}
} else {
// 先存到一个ArrayBuffer,然后一次返回,在blockManager里也存一份
val elements = new ArrayBuffer[Any]
elements ++= computedValues
updatedBlocks = blockManager.put(key, elements, storageLevel, tellMaster = true)
elements.iterator.asInstanceOf[Iterator[T]]
}
}
// 更新task的监控参数
val metrics = context.taskMetrics
metrics.updatedBlocks = Some(updatedBlocks)
new InterruptibleIterator(context, returnValue)
} finally {
// 改完了,释放锁
loading.synchronized {
loading.remove(key)
loading.notifyAll()
}
}
}
}
1,如果blockManager当中有,直接从blockManager当中取。
2,如果blockManager没有,就先用RDD的compute函数得到一个一个Iterable接口。
3,如果StorageLevel是只保存在硬盘的话,就把值存在blockManager当中,然后从blockManager当中取,这样的好处是不会一次把数据全部加载进内存。
4,如果StorageLevel是需要使用内存的情况,就把结果添加到一个ArrayBuffer其中一次返回,另外在blockManager存上一个,再次直接从blockManager取。
对StorageLevel说明一下吧,贴一下它的源码。
class StorageLevel private(
private var useDisk_ : Boolean,
private var useMemory_ : Boolean,
private var useOffHeap_ : Boolean,
private var deserialized_ : Boolean,
private var replication_ : Int = 1)
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false)
大家注意看它那几个参数,useDisk,useMemory,useOffHeap,deserialized,replication_在具体的类型的时候是传的什么值。
下面我们的目标要放到blockManager。
2、 BlockManager
BlockManager这个类比较大,我们从两方面开始看吧,putBytes和get方法。先从putBytes说起,之前说过任务运行结束之后,结果超过10M的话,会用BlockManager缓存起来。
env.blockManager.putBytes(blockId,serializedDirectResult,StorageLevel.MEMORY_AND_DISK_SER)
putBytes内部又掉了另外一个方法doPut,方法很大呀,先折叠起来。
private def doPut(
blockId: BlockId,
data: Values,
level: StorageLevel,
tellMaster: Boolean = true): Seq[(BlockId, BlockStatus)] = {// Return value
val updatedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]
// 记录它的StorageLevel,以便我们可以在它加载进内存之后,可以按需写入硬盘。
// 此外,在我们把调用BlockInfo的markReay方法之前,都没法通过get方法获得该部分内容
val putBlockInfo = {
val tinfo = new BlockInfo(level, tellMaster)
// 如果不存在,就添加到blockInfo里面
val oldBlockOpt = blockInfo.putIfAbsent(blockId, tinfo)
if (oldBlockOpt.isDefined) {
// 如果已经存在了,就不需要重复添加了
if (oldBlockOpt.get.waitForReady()) {return updatedBlocks
}
// 存在于blockInfo当中->但是上一次保存失败了,拿出旧的信息,再试一遍
oldBlockOpt.get
} else {
tinfo
}
}
val startTimeMs = System.currentTimeMillis
// 当我们需要存储数据,并且要复制数据到别的机器,我们需要访问它的值,但是因为我们的put操作会读取整个iterator,
// 这就不会有任何的值留下。在我们保存序列化的数据的场景,我们可以记住这些bytes,但在其他场景,比如反序列化存储的
// 时候,我们就必须依赖返回一个Iterator
var valuesAfterPut: Iterator[Any] = null
// Ditto for the bytes after the put
var bytesAfterPut: ByteBuffer = null
// Size of the block in bytes
var size = 0L
// 在保存数据之前,我们要实例化,在数据已经序列化并且准备好发送的情况下,这个过程是很快的
val replicationFuture = if (data.isInstanceOf[ByteBufferValues] && level.replication > 1) {
// duplicate并不是复制这些数据,只是做了一个包装
val bufferView = data.asInstanceOf[ByteBufferValues].buffer.duplicate()
Future {
// 把block复制到别的机器上去
replicate(blockId, bufferView, level)
}
} else {
null
}
putBlockInfo.synchronized {
var marked = false
try {
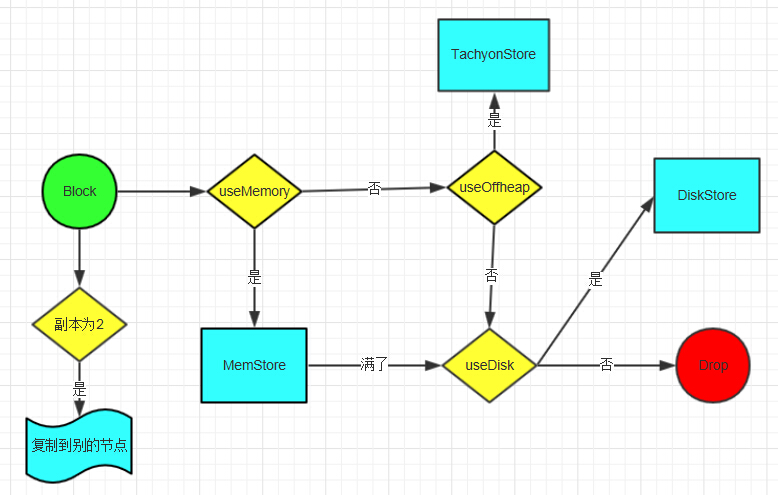
if (level.useMemory) {
// 首先是保存到内存里面,尽管它也使用硬盘,等内存不够的时候,才会写入硬盘
// 下面分了三种情况,但是Task的结果是ByteBufferValues这种情况,具体看putBytes方法
val res = data match {
case IteratorValues(iterator) =>
memoryStore.putValues(blockId, iterator, level, true)
case ArrayBufferValues(array) =>
memoryStore.putValues(blockId, array, level, true)
case ByteBufferValues(bytes) =>
bytes.rewind()
memoryStore.putBytes(blockId, bytes, level)
}
size = res.size
// 这里写得那么恶心,是跟data的类型有关系的,data: Either[Iterator[_], ByteBuffer],Left是Iterator,Right是ByteBuffer
res.data match {
case Right(newBytes) => bytesAfterPut = newBytes
case Left(newIterator) => valuesAfterPut = newIterator
}
// 把被置换到硬盘的blocks记录到updatedBlocks上
res.droppedBlocks.foreach { block => updatedBlocks += block }
} else if (level.useOffHeap) {
// 保存到Tachyon上.
val res = data match {
case IteratorValues(iterator) =>
tachyonStore.putValues(blockId, iterator, level, false)
case ArrayBufferValues(array) =>
tachyonStore.putValues(blockId, array, level, false)
case ByteBufferValues(bytes) =>
bytes.rewind()
tachyonStore.putBytes(blockId, bytes, level)
}
size = res.size
res.data match {
case Right(newBytes) => bytesAfterPut = newBytes
case _ =>
}
} else {
// 直接保存到硬盘,不要复制到其它节点的就别返回数据了.
val askForBytes = level.replication > 1
val res = data match {
case IteratorValues(iterator) =>
diskStore.putValues(blockId, iterator, level, askForBytes)
case ArrayBufferValues(array) =>
diskStore.putValues(blockId, array, level, askForBytes)
case ByteBufferValues(bytes) =>
bytes.rewind()
diskStore.putBytes(blockId, bytes, level)
}
size = res.size
res.data match {
case Right(newBytes) => bytesAfterPut = newBytes
case _ =>
}
}
// 通过blockId获得当前的block状态
val putBlockStatus = getCurrentBlockStatus(blockId, putBlockInfo)
if (putBlockStatus.storageLevel != StorageLevel.NONE) {
// 成功了,把该block标记为ready,通知BlockManagerMaster
marked = true
putBlockInfo.markReady(size)
if (tellMaster) {
reportBlockStatus(blockId, putBlockInfo, putBlockStatus)
}
updatedBlocks += ((blockId, putBlockStatus))
}
} finally {
// 如果没有标记成功,就把该block信息清除
if (!marked) {
blockInfo.remove(blockId)
putBlockInfo.markFailure()
}
}
}
// 把数据发送到别的节点做备份
if (level.replication > 1) {
data match {
case ByteBufferValues(bytes) => Await.ready(replicationFuture, Duration.Inf)
case _ => {
val remoteStartTime = System.currentTimeMillis
// 把Iterator里面的数据序列化之后,发送到别的节点
if (bytesAfterPut == null) {
if (valuesAfterPut == null) {
throw new SparkException("Underlying put returned neither an Iterator nor bytes! This shouldn't happen.")
}
bytesAfterPut = dataSerialize(blockId, valuesAfterPut)
}
replicate(blockId, bytesAfterPut, level)
}
}
}
// 销毁bytesAfterPut
BlockManager.dispose(bytesAfterPut)
updatedBlocks
}
从上面的来看:
1,存储的时候按照不同的存储级别分了3种情况来处理:存在内存当中(包括MEMORY字样的),存在tachyon上(OFF_HEAP),只存在硬盘上(DISK_ONLY)。
2,存储完成之后会根据存储级别决定是否发送到别的例程,在名字上最后带2字的都是这种,2表示一个块会在两个例程上保存。
3,存储完毕之后,会向BlockManagerMaster汇报块的情况。
4,此处面的序列化实际上是先压缩后序列化,替代使用的是LZF压缩,可以通过spark.io.compression.codec设置为snappy或者lzo,序列化方式通过spark.serializer设置,只能是JavaSerializer 。
接下来我们再看get的情况。
val local = getLocal(blockId)
if (local.isDefined) return local
val remote = getRemote(blockId)
if (remote.isDefined) return remote
None
先从本地取,本地没有再去别的例程取,都没有,返回None。从本地取就不说了,怎么进怎么出。讲一下怎么从别的例程去,它们是一个某种子的关系?
我们先看getRemote方法
private def doGetRemote(blockId: BlockId, asValues: Boolean): Option[Any] = {
val locations = Random.shuffle(master.getLocations(blockId))
for (loc <- locations) {
val data = BlockManagerWorker.syncGetBlock(GetBlock(blockId), ConnectionManagerId(loc.host, loc.port))
if (data != null) {
if (asValues) {
return Some(dataDeserialize(blockId, data))
} else {
return Some(data)
}
}
}
None
}
这个方法包括两个步骤:
1,用blockId通过master的getLocations方法找到它的位置。
2,通过BlockManagerWorker.syncGetBlock到指定的例程获取数据。
ok,下面就重点讲BlockManager和BlockManagerMaster之间的关系,以及BlockManager之间是如何相互传输数据。
3、BlockManager与BlockManagerMaster的关系
BlockManager我们使用的时候是从SparkEnv.get获得的,我们观察了一下SparkEnv,发现它包含了我们运行时候常用的那些东东。在SparkEnv的创建方法里面会实例化一个BlockManager和BlockManagerMaster。这里我们需要注意看BlockManagerMaster的实例化方法,里面调用了registerOrLookup方法。
def registerOrLookup(name: String, newActor: => Actor): ActorRef = {
if (isDriver) {
actorSystem.actorOf(Props(newActor), name = name)
} else {
val driverHost: String = conf.get("spark.driver.host", "localhost")
val driverPort: Int = conf.getInt("spark.driver.port", 7077)
Utils.checkHost(driverHost, "Expected hostname")
val url = s"akka.tcp://spark@$driverHost:$driverPort/user/$name"
val timeout = AkkaUtils.lookupTimeout(conf)
Await.result(actorSystem.actorSelection(url).resolveOne(timeout), timeout)
}
}
所以从这里可以抛光来,除了Driver之后的actor都是,都是持有的Driver的引用ActorRef。梳理一下,我们可以进行以下替换:
1,SparkContext持有一个BlockManager和BlockManagerMaster。
2,每一个执行人都持有一个BlockManager和BlockManagerMaster。
3,执行器和SparkContext的BlockManagerMaster通过BlockManagerMasterActor来通信。
接下来,我们看看BlockManagerMasterActor里的三组映射关系。
// 1、BlockManagerId和BlockManagerInfo的映射关系
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
// 2、Executor ID 和 Block manager ID的映射关系
private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
// 3、BlockId和保存它的BlockManagerId的映射关系
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
看到这三组关系,前面的getLocations方法不用看它的实现,我们都应该知道是怎么找了。
4、BlockManager相互传输数据
BlockManager之间发送数据和接受数据是通过BlockManagerWorker的syncPutBlock和syncGetBlock方法来实现。看BlockManagerWorker的注释,说是BlockManager的网络接口,采用的是事件驱动模型。
再仔细看这两个方法,它传输的数据包装成BlockMessage之后,通过ConnectionManager的sendMessageReliablySync方法来传输。
接下来的故事就是nio之间的发送和接收了,就简单说几点吧:
1,ConnectionManager内部实例化一个选择器线程线程来接收消息,具体请看运行方法。
2,Connection发送数据的时候,是一次把消息本身的消息全部发送,不是一个消息发送,具体看SendConnection的写方法,与之对应的接收看ReceivingConnection的读方法。
3,read完了之后,调用初始化函数ConnectionManager的receiveMessage方法,它又调用了handleMessage方法,handleMessage又调用了BlockManagerWorker的onBlockMessageReceive方法。传说中的事件驱动又出现了。
def processBlockMessage(blockMessage: BlockMessage): Option[BlockMessage] = {
blockMessage.getType match {
case BlockMessage.TYPE_PUT_BLOCK => {
val pB = PutBlock(blockMessage.getId, blockMessage.getData, blockMessage.getLevel)
putBlock(pB.id, pB.data, pB.level)
None
}
case BlockMessage.TYPE_GET_BLOCK => {
val gB = new GetBlock(blockMessage.getId)
val buffer = getBlock(gB.id)
Some(BlockMessage.fromGotBlock(GotBlock(gB.id, buffer)))
}
case _ => None
}
}
根据BlockMessage的类型进行处理,输入类型就保存数据,getType就从本地把块重定向来给给它。

注:BlockManagerMasterActor是存在于BlockManagerMaster内部,在外面只是因为它在通信的时候起了关键的作用的,执行程序上持有的BlockManagerMasterActor是驱动程序的那些演员的引用。
5、广播变量
先回顾一下怎么使用广播变量:
scala> val broadcastVar = sc.broadcast(Array(1、2、3))
broadcastVar:spark.Broadcast [Array [Int]] = spark.Broadcast(b5c40191-a864-4c7d-b9bf-d87e1a4e787c)
scala> broadcastVar.value
res0:Array [Int] = Array(1、2、3)
看了一下实现调用的是broadcastFactory的newBroadcast方法。
def newBroadcast [T:ClassTag](value_:T,isLocal:Boolean)= {
broadcastFactory.newBroadcast [T](value_,isLocal,nextBroadcastId.getAndIncrement())
}
默认的broadcastFactory是HttpBroadcastFactory,内部还有另外一个实现TorrentBroadcastFactory,先说HttpBroadcastFactory的newBroadcast方法。
它直接新了一个HttpBroadcast。
HttpBroadcast.synchronized {
SparkEnv.get.blockManager.putSingle(blockId,value_,StorageLevel.MEMORY_AND_DISK,tellMaster = false)
}
if(!isLocal){
HttpBroadcast.write(id,value_)
}
它的内部既两个操作,把数据保存到驱动程序端的BlockManager和写入到硬盘。
TorrentBroadcast和HttpBroadcast都把数据存进了BlockManager做备份,但是TorrentBroadcast接着并没有把数据写入文件,或者采用了以下这种方式:
def sendBroadcast(){
//把数据给切分了,每4M一个分片
val tInfo = TorrentBroadcast.blockifyObject(value_)
totalBlocks = tInfo.totalBlocks
totalBytes = tInfo.totalBytes
hasBlocks = tInfo.totalBlocks
//把分片的信息存到BlockManager,并通知Master
val metaId = BroadcastBlockId(id,“ meta”)
val metaInfo = TorrentInfo(null,totalBlocks,totalBytes)
TorrentBroadcast.synchronized {
SparkEnv.get.blockManager.putSingle(
metaId,metaInfo,StorageLevel.MEMORY_AND_DISK,tellMaster = true)
}
//遍历所有分片,存到BlockManager上面,并通知Master
为(i <-0直到totalBlocks){
val pieceId = BroadcastBlockId(id,“ piece” + i)
TorrentBroadcast.synchronized {
SparkEnv.get.blockManager.putSingle(
pieceId,tInfo.arrayOfBlocks(i),StorageLevel.MEMORY_AND_DISK,tellMaster = true)
}
}
}
1,把数据序列化之后,每4M切分一下。
2,切分完了之后,把所有分片写入BlockManager。
但是发现它们是怎么传播的??
未完待续!
6、相关参数
// BlockManager的最大内存
spark.storage.memoryFraction默认值0.6
//文件保存的位置
spark.local.dir默认为系统变量java.io.tmpdir的值
// tachyon保存的地址
spark.tachyonStore.url默认值tachyon:// localhost:19998
//默认不启用netty来传输shuffle的数据
spark.shuffle.use.netty默认值是false
spark.shuffle.sender.port默认值是0
//一个减少抓取映射中间结果的最大的同时抓取数量大小(以避免过度分配用于接收随机输出的内存)
spark.reducer.maxMbInFlight默认值是48 * 1024 * 1024
// TorrentBroadcast切分数据块的分片大小
spark.broadcast.blockSize默认为4096
//广播变量的工厂类
spark.broadcast.factory默认为org.apache.spark.broadcast.HttpBroadcastFactory,也可以设置为org.apache.spark.broadcast.TorrentBroadcastFactory
//压缩格式
spark.io.compression.codec默认为LZF,可以设置成Snappy或者Lzo
Spark原始码系列(五)分布式缓存的更多相关文章
- Spark原始码系列(六)Shuffle的过程解析
问题导读: 1.shuffle过程的划分? 2.shuffle的中间结果如何存储? 3.shuffle的数据如何拉取过来? Shuffle过程的划分 Spark的操作模型是基于RDD的,当调用RD ...
- Spark源码系列:RDD repartition、coalesce 对比
在上一篇文章中 Spark源码系列:DataFrame repartition.coalesce 对比 对DataFrame的repartition.coalesce进行了对比,在这篇文章中,将会对R ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Spark源码系列(五)分布式缓存
这一章想讲一下Spark的缓存是如何实现的.这个persist方法是在RDD里面的,所以我们直接打开RDD这个类. def persist(newLevel: StorageLevel): this. ...
- Spark源码系列(一)spark-submit提交作业过程
前言 折腾了很久,终于开始学习Spark的源码了,第一篇我打算讲一下Spark作业的提交过程. 这个是Spark的App运行图,它通过一个Driver来和集群通信,集群负责作业的分配.今天我要讲的是如 ...
- Spark源码系列(九)Spark SQL初体验之解析过程详解
好久没更新博客了,之前学了一些R语言和机器学习的内容,做了一些笔记,之后也会放到博客上面来给大家共享.一个月前就打算更新Spark Sql的内容了,因为一些别的事情耽误了,今天就简单写点,Spark1 ...
- Spark源码系列(二)RDD详解
1.什么是RDD? 上一章讲了Spark提交作业的过程,这一章我们要讲RDD.简单的讲,RDD就是Spark的input,知道input是啥吧,就是输入的数据. RDD的全名是Resilient Di ...
- Spark源码系列:DataFrame repartition、coalesce 对比
在Spark开发中,有时为了更好的效率,特别是涉及到关联操作的时候,对数据进行重新分区操作可以提高程序运行效率(很多时候效率的提升远远高于重新分区的消耗,所以进行重新分区还是很有价值的).在Spark ...
- Spark SQL概念学习系列之分布式SQL引擎
不多说,直接上干货! parkSQL作为分布式查询引擎:两种方式 除了在Spark程序里使用Spark SQL,我们也可以把Spark SQL当作一个分布式查询引擎来使用,有以下两种使用方式: 1.T ...
随机推荐
- B. Sleepy Game 博弈搜索
题意:给一个有向图和起点,然后只有一名选手,这名选手可以随意挪动棋子,最终不能动的时候走过的边为奇数边为Win并输出路径,否则如果有环输出Draw,否则输出Lose; 题目链接 知道状态数最多只有n* ...
- HDU3829 Cat VS Dog
题目链接:https://vjudge.net/problem/HDU-3829 题目大意: 有\(P\)个小孩,\(N\)只猫,\(M\)只狗.每个小孩都有自己喜欢的某一只宠物和讨厌的某一只宠物(其 ...
- 基于Unity实现像素化风格的着色器
Shader "MyShaderTest/SimplePixelationShader" { Properties { _MainTex ("Base (RGB)&quo ...
- ubuntu 安装 swftoos
一:下载依赖: freetype下载地址 : http://ftp.twaren.net/Unix/NonGNU/freetype/ jpegsrc:下载地址 http://www.ijg.org/f ...
- 实验四:Linux系统C语言开发环境学习
项目 内容 这个作业属于哪个课程 班级课程主页链接 这个作业的要求在哪里 作业要求 学号-姓名 17043133-木腾飞 作业学习要求 1.学习Linux系统中如何查看帮助文档:2.在Linux系统中 ...
- js解析MarkDown语法
1.问题描述: 我们使用MarkDown编辑器之后,比如我们写的MarkDown的语法是: # 一级标题 ## 二级标题 ### 三级标题 这种语法我们最终要转换成HTML的格式最终要存入数据库 ...
- eatwhatApp开发实战(十三)
这次内容,我们就项目中添加商店名称的EditText进行修改,让添加按钮随着edittext的内容而改变. 上代码,首先是xml文件上对两个控件的修改: <RelativeLayout andr ...
- [JavaWeb基础] 004.用JSP + SERVLET 进行简单的增加删除修改
上一次的文章,我们讲解了如何用JAVA访问MySql数据库,对数据进行增加删除修改查询.那么这次我们把具体的页面的数据库操作结合在一起,进行一次简单的学生信息操作案例. 首先我们创建一个专门用于学生管 ...
- JAVASE(十七) 多线程:程序、进程、线程与线程的生命周期、死锁、单例、同步锁
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.程序.进程.线程的理解 1.1 概念 程序(program)是为完成特定任务.用某种语言编写的一组指 ...
- Java实现蓝桥杯 算法提高 盾神与积木游戏
题目描述 最近的m天盾神都去幼儿园陪小朋友们玩去了~ 每个小朋友都拿到了一些积木,他们各自需要不同数量的积木来拼一些他们想要的东西.但是有的小朋友拿得多,有的小朋友拿得少,有些小朋友需要拿到其他 小朋 ...