kubernetes pod的弹性伸缩———基于pod自定义custom metrics(容器的IO带宽)的HPA
背景
自Kubernetes 1.11版本起,K8s资源采集指标由Resource Metrics API(Metrics Server 实现)和Custom metrics api(Prometheus实现)两种API实现,传统Heapster监控被废弃。前者主要负责采集Node、Pod的核心资源数据,如内存、CPU等;而后者则主要负责自定义指标数据采集,如网卡流量,磁盘IOPS、HTTP请求数、数据库连接数等。
heapster被废弃以后,所有的指标数据都从API接口中获取,kubernetes将资源指标分为了两种:
Core metrics(核心指标):由metrics-server提供API,即 metrics.k8s.io,仅提供Node和Pod的CPU和内存使用情况。
Custom Metrics(自定义指标):由Prometheus Adapter提供API,即 custom.metrics.k8s.io,由此可支持任意Prometheus采集到的自定义指标。
想让k8s一些核心组件,比如HPA,获取核心指标以外的其它自定义指标,则必须部署一套prometheus监控系统,让prometheus采集其它各种指标,
但是prometheus采集到的metrics并不能直接给k8s用,因为两者数据格式不兼容,还需要另外一个组件(kube-state-metrics),将prometheus的metrics 数据格式转换成k8s API接口能识别的格式,转换以后,因为是自定义API,所以还需要用Kubernetes aggregator在主API服务器中注册,以便直接通过/apis/来访问。
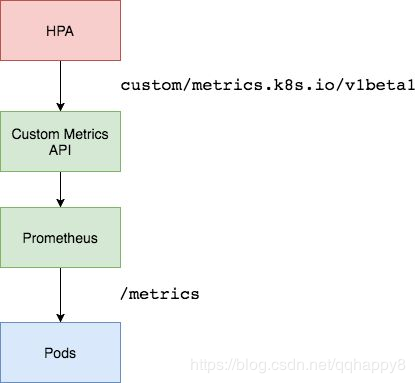
Horizontal Pod Autoscaler实现为一个控制循环,定期查询Resource Metrics API以获取CPU /内存等核心指标和针对特定应用程序指标的Custom Metrics API。
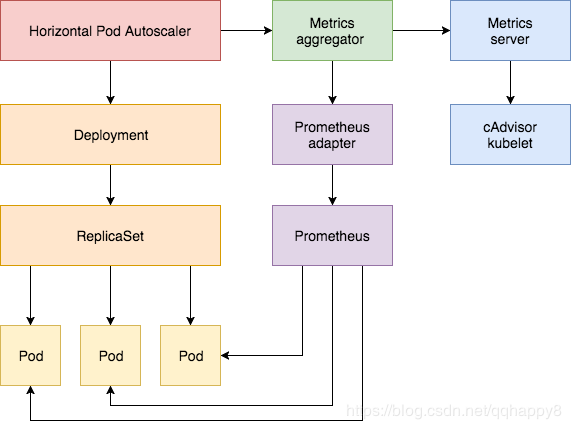
Custom Metrics组件介绍
- node-exporter:prometheus的agent端,收集Node级别的监控数据。
- prometheus:监控服务端,从node-exporter拉取数据并存储为时序数据。
- kube-state-metrics: 将prometheus中可以用PromQL查询到的指标数据转换成k8s对应的数据格式,即转换成Custerom Metrics API接口格式的数据,但是它不能聚合进apiserver中的功能。
- k8s-prometheus-adpater:聚合apiserver,即提供了一个apiserver(custom-metrics-api),自定义APIServer通常都要通过Kubernetes aggregator聚合到apiserver
部署步骤
1.部署好prometheus,node-exporter,kube-state-metrics,开启kube-apiserver的聚合功能,相关教程很多。
2.下载相关yaml文件 ,yaml文件clone于https://github.com/stefanprodan/k8s-prom-hpa,笔者内网环境,使用的为此git仓库的zip包。

如上图,部署custom-metrics的yaml文件位于./custom-metrics-api目录,其中核心yaml文件为custom-metrics-apiserver-deployment.yaml和custom-metrics-apiservice.yaml,为部署prometheus-adapter的pod,并注册custom-metrics的apiservice。
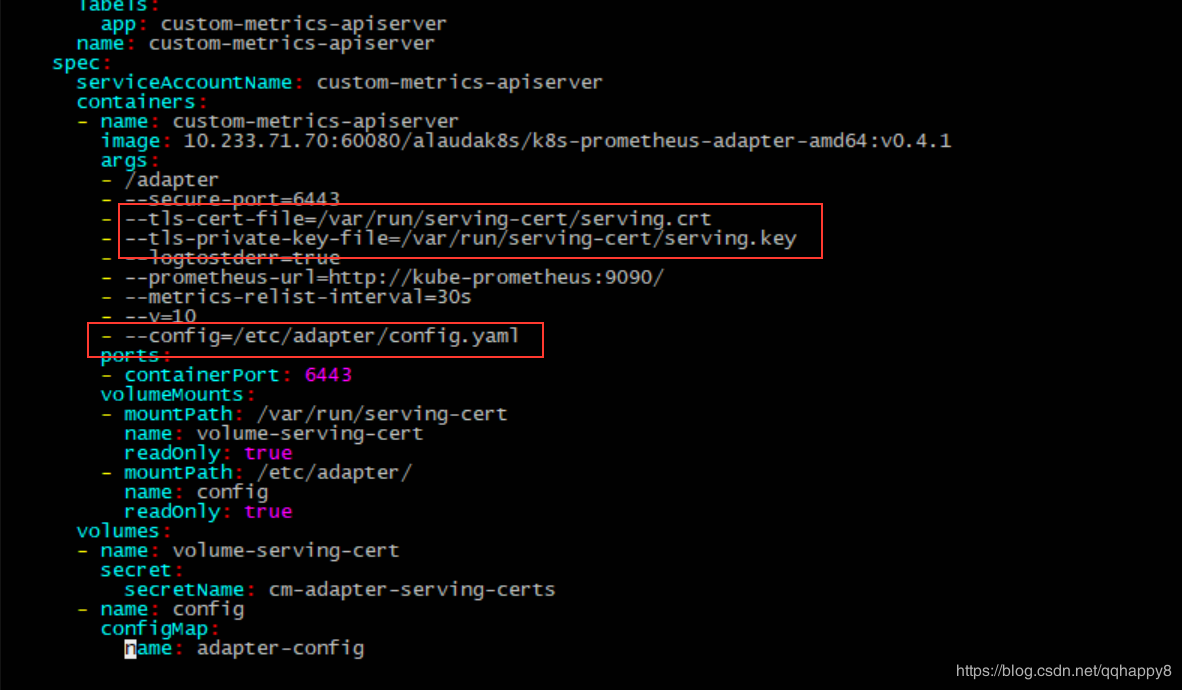
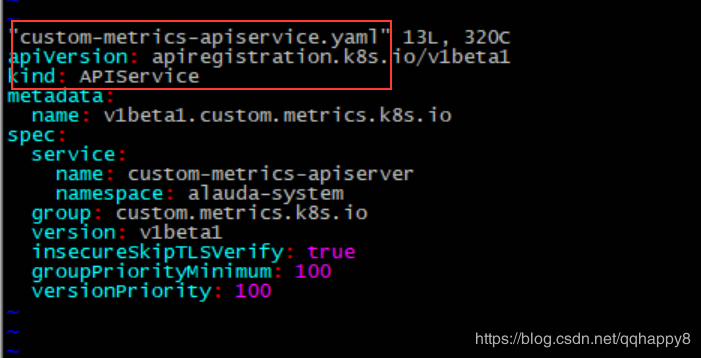
3.修改custom-metrics-api目录所有的yaml的namespace为alauda-system,因笔者prometheus部署在此namespace。
sed -i 's/namespace: monitoring/namespace: alauda-system/g' *.yaml
4.参照custom-metrics-apiserver-deployment.yaml里面的prometheus-adapter的启动配置,准备tls证书,笔者复用了master节点的证书。
kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=/etc/kubernetes/pki/apiserver.crt --from-file=serving.key=/etc/kubernetes/pki/apiserver.key -n alauda-system

5.按照./custom-metrics-api目录下的资源清单,部署相关资源对象。
kubectl create -f /home/cloudops/custom-metrics/k8s-prom-hpa-master/custom-metrics-api

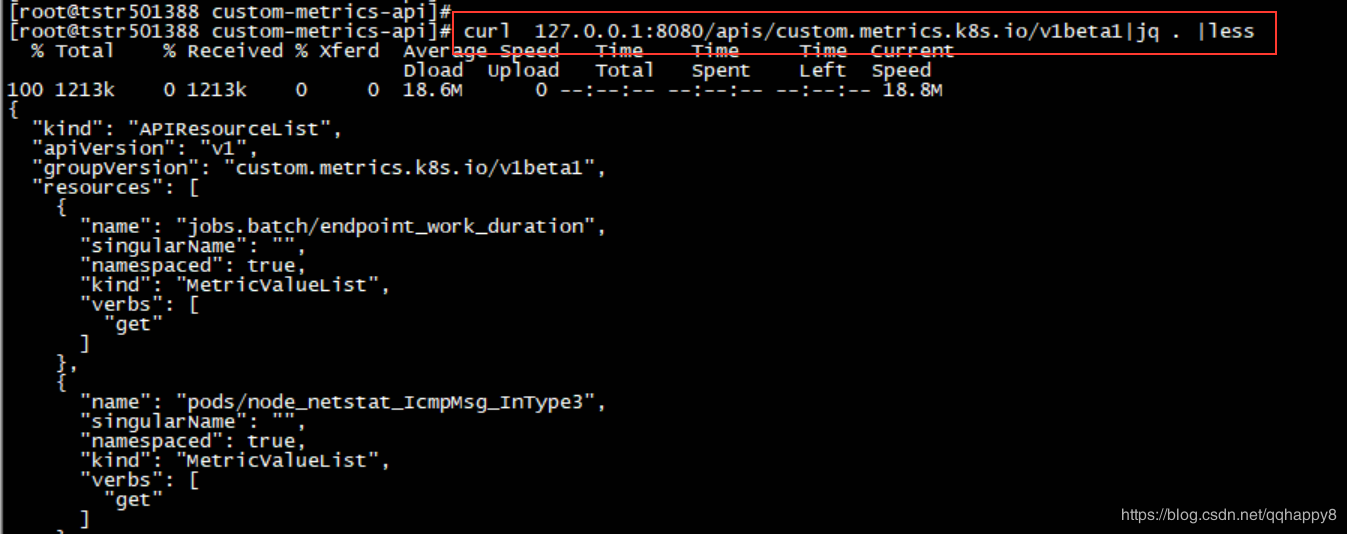
6.检查custom-metrics-apiserver的pod启动成功,custom-metrics-apiservice注册成功,curl此api路径正常返回。
curl 127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/ |jq .|less

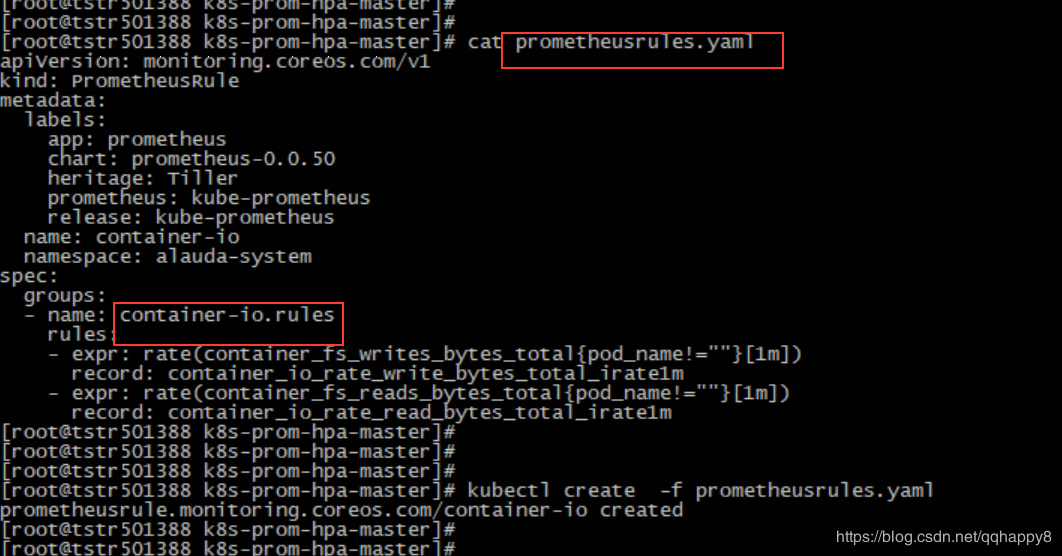
7.创建关于容器IO带宽的prometheusRule,确认rule的指标正常采集。
####cat prometheusrules.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: prometheus
chart: prometheus-0.0.50
heritage: Tiller
prometheus: kube-prometheus
release: kube-prometheus
name: container-io
namespace: alauda-system
spec:
groups:
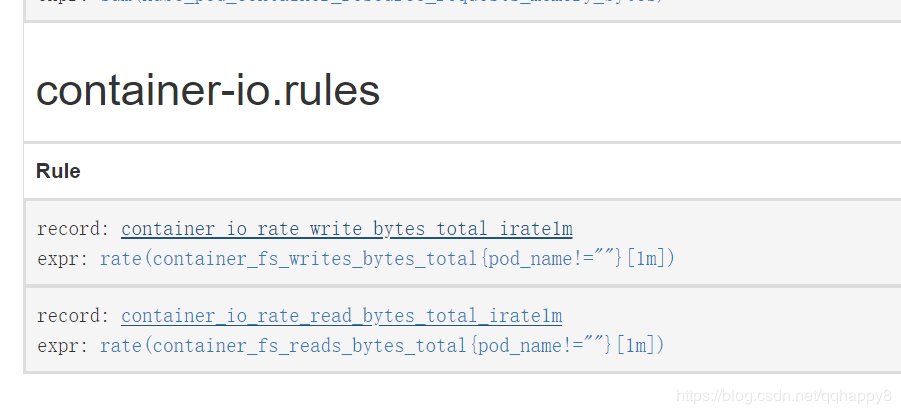
- name: container-io.rules
rules:
- expr: rate(container_fs_writes_bytes_total{pod_name!=""}[1m])
record: container_io_rate_write_bytes_total_irate1m
- expr: rate(container_fs_reads_bytes_total{pod_name!=""}[1m])
record: container_io_rate_read_bytes_total_irate1m
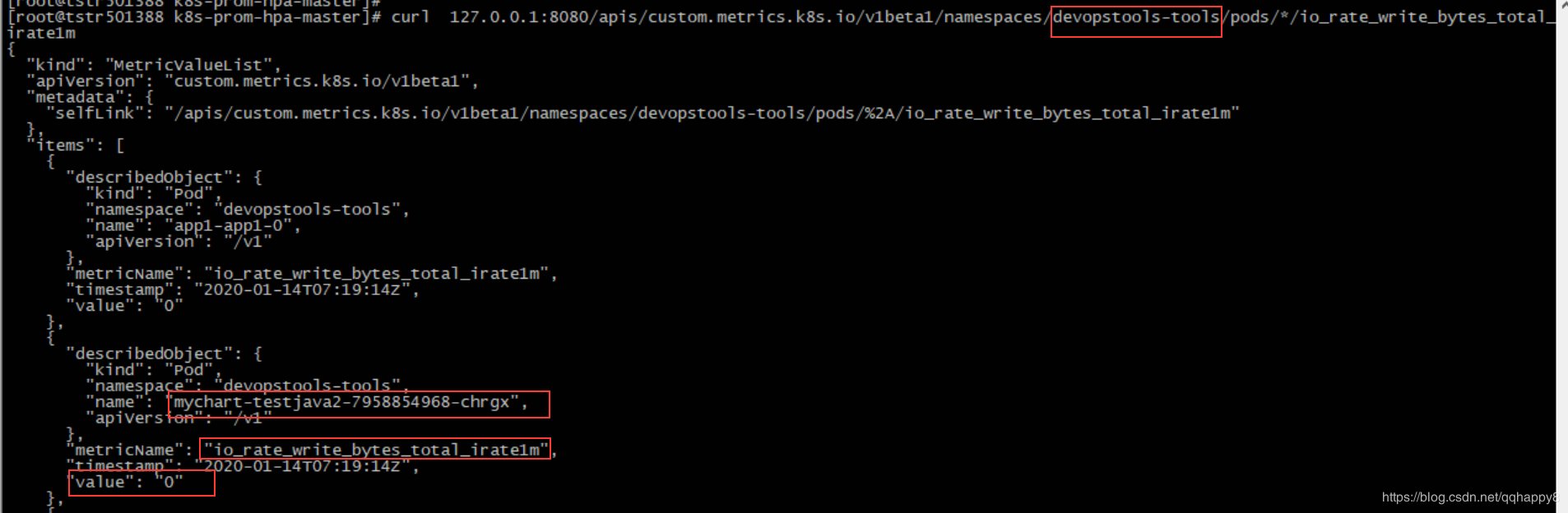
8.检查基于IO的custom-metrics通过kube-api能正常访问,注意替换namespace为本地环境。
curl 127.0.0.1:8080/apis/custom.metrics.k8s.io/v1beta1/namespaces/devopstools-tools/pods/*/io_rate_write_bytes_total_irate1m
9.创建一个基于IO带宽的HPA对象(基于pod的io写带宽,阈值为20M),笔者使用的为一个tomcat的pod。
####cat devopstools-tools-hpa-testjava.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: testjava-io
namespace: devopstools-tools
spec:
maxReplicas: 3
minReplicas: 1
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: mychart-testjava2
metrics:
- type: Pods
pods:
metricName: io_rate_write_bytes_total_irate1m
targetAverageValue: 20000000000m
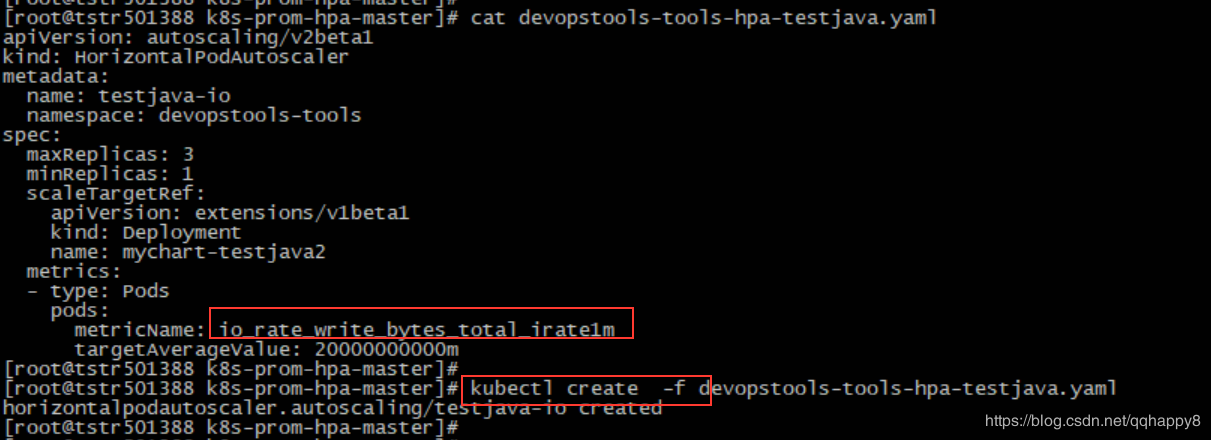
至此,基于IO写带宽的HPA创建完成
验证
1.在HPA的作用对象的容器pod里面,通过dd命令,加大此pod的IO带宽。

2.通过kubectl describe hpa检查HPA是否正常工作。
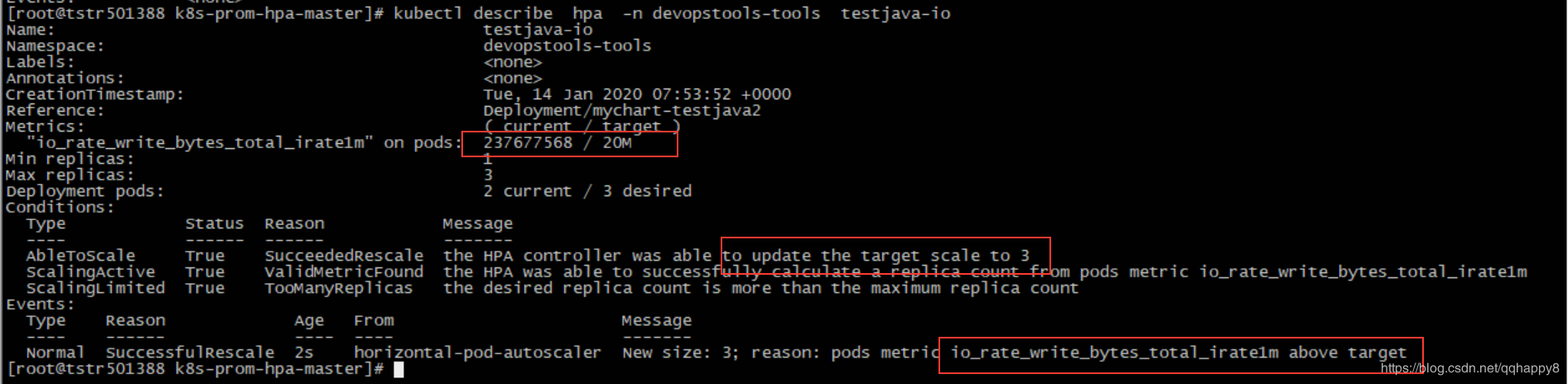
如上图,因为IO写带宽超过阈值(20M),deployment控制的pod副本数增加到3。
3.在prometheus端查询pod的IO带宽(下图显示io带宽40M以上),也表明HPA工作正常。

后记
1.基于IO带宽的HPA,和基于cpu和内存的HPA相比,生产实用性不一定很大,本文只是证明custom-metrics的可行性。
2.基于容器的IOPS的HPA暂未成功,原因为prometheus查询的容器iops(container_fs_io_current)始终为0,google到的原因为cadvisor的bug,待进一步调研。
参考 https://github.com/stefanprodan/k8s-prom-hpa
kubernetes pod的弹性伸缩———基于pod自定义custom metrics(容器的IO带宽)的HPA的更多相关文章
- Kubernetes 弹性伸缩全场景解析(三) - HPA 实践手册
在上一篇文章中,给大家介绍和剖析了 HPA 的实现原理以及演进的思路与历程.本文我们将会为大家讲解如何使用 HPA 以及一些需要注意的细节. autoscaling/v1 实践 v1 的模板可能是大家 ...
- Kubernetes 弹性伸缩全场景解读(二)- HPA 的原理与演进
前言 在上一篇文章 Kubernetes 弹性伸缩全场景解析 (一):概念延伸与组件布局中,我们介绍了在 Kubernetes 在处理弹性伸缩时的设计理念以及相关组件的布局,在今天这篇文章中,会为大家 ...
- 弹性伸缩布局-flex
弹性伸缩布局-flex 引言:本文主要参照阮一峰的网络日志 .郭锦荣的博客总结完成. 正文: 布局的传统解决方案,基于盒状模型,依赖 display 属性 + position属性 + float属性 ...
- CSS3弹性伸缩布局(二)——flex布局
上一篇博客<CSS3弹性伸缩布局(一)——box布局>介绍了旧版本的box布局,而这篇博客将主要介绍最新版本的flex布局的基础知识. 新版本简介 新版本的Flexbox模型是2012年9 ...
- Kubernetes 弹性伸缩HPA功能增强Advanced Horizontal Pod Autoscaler -介绍部署篇
背景 WHAT(做什么) Advanced Horizontal Pod Autoscaler(简称:AHPA)是kubernetes中HPA的功能增强. 在兼容原生HPA功能基础上,增加预测.执行模 ...
- Kubernetes Pod水平自动伸缩(HPA)
HPA简介 HAP,全称 Horizontal Pod Autoscaler, 可以基于 CPU 利用率自动扩缩 ReplicationController.Deployment 和 ReplicaS ...
- Kubernetes 弹性伸缩全场景解读(五) - 定时伸缩组件发布与开源
作者| 阿里云容器技术专家刘中巍(莫源) 导读:Kubernetes弹性伸缩系列文章为读者一一解析了各个弹性伸缩组件的相关原理和用法.本篇文章中,阿里云容器技术专家莫源将为你带来定时伸缩组件 kub ...
- Kubernetes使用metric-server让HPA弹性伸缩运行
监控架构概述 kubernetes监控指标大体可以分为两类:核心监控指标和自定义指标,核心监控指标是kubernetes内置稳定可靠监控指标,早期由heapster完成,现由metric-server ...
- Kubernetes 弹性伸缩全场景解析 (四)- 让核心组件充满弹性
前言 在本系列的前三篇中,我们介绍了弹性伸缩的整体布局以及HPA的一些原理,HPA的部分还遗留了一些内容需要进行详细解析.在准备这部分内容的期间,会穿插几篇弹性伸缩组件的最佳实践.今天我们要讲解的是 ...
随机推荐
- SVN部署(Centos7,Ubuntu)
SVN 简介 SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS.CVS,它采用了分支管理系统,它的设计目标就是取代CVS.互联网上很多版本控制服务已从CVS迁移到Sub ...
- 2019-2020-1 20199325《Linux内核原理与分析》第五周作业
第五周作业主要是选择一个系统调用(13号系统调用time除外),使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用,在实验楼Linux虚拟机环境下完成实验. 系统调用的列表参见 http ...
- 2019-2020-1 20199329《Linux内核原理与分析》第十三周作业
<Linux内核原理与分析>第十三周作业 一.本周内容概述 通过重现缓冲区溢出攻击来理解漏洞 二.本周学习内容 1.实验简介 注意:实验中命令在 xfce 终端中输入,前面有 $ 的内容为 ...
- Python不同版本打包程序为.exe文件
安装pyinstaller 测试用的python环境是3.6.2版本 下载地址 https://github.com/pyinstaller/pyinstaller/ 1.打开cmd,切到pyinst ...
- java并发中ExecutorService的使用
文章目录 创建ExecutorService 为ExecutorService分配Tasks 关闭ExecutorService Future ScheduledExecutorService Exe ...
- 热门云服务超87GB电子邮箱和密码泄露,黑客已验证大部分数据
热门云存储服务Mega被曝发现超87GB电子邮件地址和密码泄露(源数据目前已被删除,但已流传到个别黑客网站),其中包含近7.73亿电子邮件地址和2200万密码. 近日,国外一名安全研究人员Troy H ...
- Express 文档(常见问题)
常见问题 我该如何构建我的应用程序? 这个问题没有明确的答案,答案取决于你的应用程序规模和所涉及的团队,为了尽可能灵活,Express在结构方面没有做出任何假设. 在你喜欢的任何目录结构中,路由和其他 ...
- 10倍处理能力 阿里云推云上首个支持12层4K非编NAS产品
5月23日,阿里云在2017云栖大会·成都峰会上正式推出了云上首个支持广电级非编的文件存储产品------NAS Plus,作为阿里云文件存储NAS的升级款,NAS Plus提供高达200Gbps的吞 ...
- DeepWalk论文精读:(1)解决问题&相关工作
模块1 1. 研究背景 随着互联网的发展,社交网络逐渐复杂化.多元化.在一个社交网络中,充斥着不同类型的用户,用户间产生各式各样的互动联系,形成大小不一的社群.为了对社交网络进行研究分析,需要将网络中 ...
- 智能称体脂称实现(datasheet篇)
(本文均出于个人理解而写,仅用于学习和交流,某些过程可能不一定正确,希望各位提出意见进行交流,共同进步) TI的参考方案是采用AFE4300芯片 同时进行生物阻抗身体成分测量和体重测量,以MSP430 ...