存储系列之 Linux ext2 概述
引言:学习经典永不过时。
我们之前介绍过存储介质主要是磁盘,先介绍过物理的,后又介绍了虚拟的。保存在磁盘上的信息一般采用文件(file)为单位,磁盘上的文件必须是持久的,同时文件是通过操作系统管理的,其中包括文件的结构、文件的名称、文件的使用、文件的保护、文件的实现等等,所以在一个操作系统中,负责处理与文件相关的各种事情的部分,叫做文件系统(File System)。
如上所述,文件系统就是一种抽象。文件系统对于用户而言,关心的是文件的访问和操作;而对设计者或者相关开发者而言,更关心的是如何实现与之相关的内部结构和功能模块,例如文件系统的布局、空闲块的管理、数据块的大小、文件内容如何分配和查找等等。本文主要从开发者或者设计者角度出发,以linux经典的文件系统EXT2为例介绍文件系统是如何组织以及实现的。
一、文件系统的布局
Linux下每个分区上(LVM中对应逻辑卷LV)的文件系统是相互独立的, 也就是说每个分区都有自己的文件系统,mkfs格式化的时候可以设置,每个分区的文件系统可以不同,当然也可以相同。所以一个分区就代表了一个文件系统。下图的第二层和第三层对应了一个文件系统EXT2的的分布图。
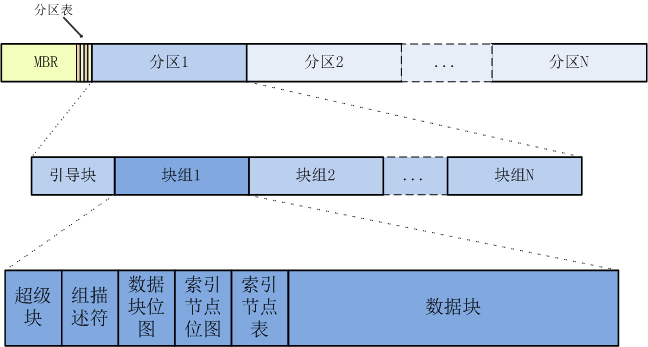
我们首先介绍上图中的第一层,这层表示计算机系统的整个磁盘空间,被划分出了若干个分区。磁盘的扇区0(LBA0)称为主引导记录(Master Boot Record,MBR),简称为主引导,它主要用来启动计算机。在MBR的末尾有一个分区表,里面记录了每一个分区的起始地址和结束地址。MBR长度固定,即一个扇区的长度512B,而分区表的长度是64B,所以主引导程序长度就是446B。每个分区信息的长度固定16B,所以MBR分区表只能保存4个分区,也被称为主分区,如果需要描述更多的分区,则需要将其中一个分区作为扩展分区,指向更多的逻辑分区组成的链表。所以一般一个多(N)分区系统实际显示的是三个主分区和N-3个逻辑分区。现在很多计算机系统采用新的分区方式GPT,没有主分区个数的限制,而且分区容量也没有2TB的限制。
MBR程序所做的第一件事情是确定活动分区,并读入它的第一个磁盘块,称为引导块(Boot Block),然后装入内存并执行它。引导块是操作系统的引导程序和文件。每个分区都保留了引导块,不管这个分区是否已经安装了操作系统。如果引导程序太长,一个块放不下,也可以指向其他块。在MBR分区的方式下,启动的分区必须是主分区,不能是逻辑分区,逻辑分区只能是被管理。
一个EXT2文件系统,除了引导块,其他由多个块组(Block Group)组成,如上图第二层所示。
每一个块组的内部结构是一样的,内容不同,如图中第三层。这一层就是本文的重点介绍对象。
二、ext2的结构和特性
首先我们介绍几个基础概念,然后再对上图中第三层的结构进行分解。
逻辑块((block)
block是在分区进行文件系统的格式化时所指定的"最小存储单位",这个最小存储单位以扇区的大小为基础,大小为扇区的 2ⁿ 倍。此时,磁头一次可以读取一个逻辑块。指定逻辑块的大小为 4KB(即由连续的 8 个扇区构成的一个块),那么,同样读取一个 10M 的文件,磁头要读取的次数则大幅下降为 2560 次,这样就大大提高了文件的读取效率。需要注意的是,逻辑块也并不是越大越好。因为一个逻辑块最多仅能容纳一个文件(这里指 Linux 的 ext2 文件系统)。这有什么问题呢?举例来说,假如逻辑块的大小为 4KB,有一个文件大小为 0.1KB,这个小文件将占用掉一个块的空间。也就是说,该块虽然可以容纳 4KB 的容量,然而由于文件只占用了 0.1KB,实际上剩下的 3.9KB 空间就不能再被使用了(完全浪费掉了)。所以好的方式是根据实际的使用场景来设置逻辑块的大小。
inode
Linux 操作系统的文件数据除了文件实际内容外,通常含有非常多的属性,例如文件权限(rwx)与文件属性(拥有者、群组、时间参数等)。文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到 inode 中,至于实际数据则放置到 Data Block 区块中。inode的大小和block大小不同,tune2fs 可以进行查看,如下所示。
[root@localhost lib]# tune2fs -l /dev/sda
tune2fs 1.42.9 (28-Dec-2013)
...........
Filesystem OS type: Linux
Inode count: 274661376
Block count: 2197291008
Reserved block count: 109864550
Free blocks: 842263996
Free inodes: 274643493
First block: 0
Block size: 4096
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 1000
...........
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 24d40b7a-1dca-40ee-bd4f-e52b65070d01
Journal backup: inode blocks
[root@localhost lib]#
block与inode的关系
实际记录文件的内容,若文件太大时,会占用多个 block。
每个文件都会占用一个 inode,inode 内则有文件数据放置的 block 号码。下面是 inode、block 数据存取的示意图(此图来自互联网):
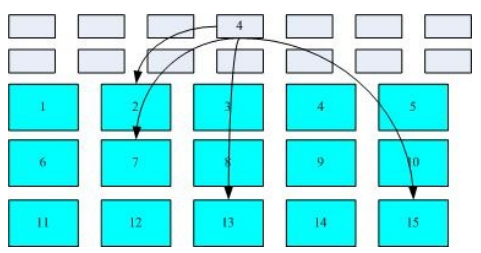
这种数据存取的方法我们称为索引式文件系统(indexed allocation)。
接下来我们再介绍文件系统EXT2的组织结构。
1、超级块:Super Block
每个文件系统开始位置的那个块就称为超级块。超级块会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。
也就是说,要使用一个分区(或文件系统)来进行数据访问时,第一个要经过的就是超级块。
其实上除了第一个 block group 内会含有 super block 之外,后续的 block group 一般都包含了 super block,即做为第一个 block group 内 super block 的备份。
所以,如果第一个超级块损坏了,则可以从后面的超级块复制过来。
super block 记录整个 filesystem 相关信息,主要信息有:
- block 与 inode 的总量
- 未使用与已使用的 inode/block 数量
- block 与 inode 的大小(block 为 1,2,4K,inode 为 128 Bytes 或 256 Bytes)
- filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等文件系统的相关信息
- 一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0,若未被挂载,则 valid bit 为 1
super block 的大小为 1024 Bytes,它非常重要,因为分区上重要的信息都在上面。如果所有保存的 super block 挂掉了,分区上的数据就很难恢复了。
2、组描述符:Group Description
Group Description 用来描述每个 group 的开始与结束位置的 block 号码,以及说明每个块(super block、bitmap、inode bitmap、data block) 分别介于哪一个 block 号码之间。
组描述符信息和超级块信息一样,复制到其他组块的开头。但是只有组块1中所包含的超级块和组描述符才由内核使用。实际中,系统启动时,修复工具e2fsck程序会对文件系统进行一致性检查,当发现组块1的超级块和组描述符无效时,系统管理员可以用e2fsck命令从后面的组块中的这两部分信息拷贝过来。
dumpe2fs命令显示device中文件系统的超级块和块组信息,如果添加选项 -h,则只输出 super block 中的信息。
3、数据块位图:Block Bitmap
在创建文件时需要为文件分配 block,文件系统需要选择空闲的 block ,如何查看 block 是否已经被使用了呢?借助于 block bitmap。通过 block bitmap 可以知道哪些 block 是空的,因此系统就能够很快地找到空闲空间来分配给文件。同样的,在删除某些文件时,文件原本占用的 block 号码就要释放出来,此时在 block bitmap 当中相对应到该 block 号码的标志就需要修改成"空闲"。这就是 block bitmap 的作用。
4、索引节点位图:Inode Bitmap
inode bitmap 与 block bitmap 的功能类似,只是 block bitmap 记录的是使用与未使用的 block 号,而 inode bitmap 则记录的是使用与未使用的 inode 号。
5、索引节点表:Inode Table
Inode table 中存放着一个个 inode,inode 的内容记录文件的属性以及该文件实际数据放置在哪些 block 内,inode 记录的主要的文件属性如下:
- 该文件的读写权限(rwx)
- 该文件的拥有者和所属组(owner/group)
- 该文件的容量
- 该文件的 ctime(创建时间)
- 该文件的 atime(最近一次的读取时间)
- 该文件的 mtime(最近修改的时间)
- 该文件的特殊标识,比如 SetUID 等
- 该文件真正内容的指向(pointer)
inode 的数量与大小也是在格式化时就已经固定了的,另外 inode 还有如下特点:
- 每个 inode 大小均固定为 128 Bytes(新的 ext4 为 256 Bytes)
- 每个文件都仅会占用一个 inode
- 文件系统能够创建的文件数量与 inode 的数量相关
- 系统读取文件时需要先找到 inode,并分析 inode 所记录的权限与使用者是否符合,若符合才能够开始读取 block 的内容
6、数据块:Data Block
Data Block 是用来存放文件内容的地方,ext2 文件系统有 1K、2K 和 4K 大小的 block。在格式化文件系统时 block 的大小就确定了,并且每个 block 都有编号。需要注意的是,由于 block 大小的差异,会导致文件系统能够支持的最大磁盘容量和最大单个文件的大小并不相同。下表描述了 block 大小与文件系统以及单个文件大小的关系:
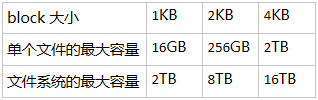
此外 Ext2 文件系统的 block 还有下面一些限制:
- block 的大小与数量在格式化后就不能再改变了(除非重新格式化)
- 每个 block 内最多只能够放置一个文件的数据
- 如果文件大于 block 的大小,那么一个文件会占用多个 block
- 若文件小于 block,则该 block 的剩余容量也不能再被使用了(磁盘空间被浪费)
三、其他
上述对ext2的结构组成基本介绍完成,再补充几个细节。
1、一个文件系统有多少个块组呢?
这取决于分区的大小和块的大小。其主要限制在块位图,因为块位图必须存放在一个单独的块中(inode bitmap一样),块位图用来标识一个组中块的占用和空闲状况。所以每组中至多有8*b个块,b是以字节为单位的块大小。因此,块组的总数大约是s/(8*b),这里s是分区所包含的总块数。
举例说明,让我们考虑一个32GB的ext2分区,块的大小为4KB。在这种情况下,每个4KB的块位图描述32K个数据块,即128MB。因此,最多需要256个块组。显然,块的大小越小,块组数越大。
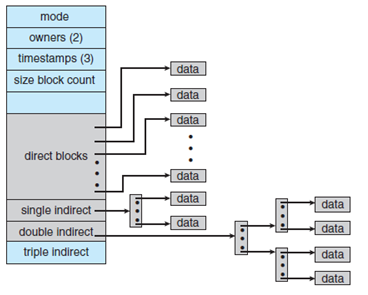
2、文件较大时,多个块是如何管理的?
从上面我们知道,文件的内容存在data block中,但是一个文件只对应一个inode,而一个inode除了包含文件的属性外只能指向15个磁盘块。如果文件的大小超过了这个限制,则把最后一个(地址)指向一个间接块,里面存放了更多的磁盘块地址。如果还不够的话,还可以使用二级间接块和三级间接块。如下图所示(https://www.cnblogs.com/linux-xin/p/8126999.html)。
3、目录
Unix/Linux系统中,目录(directory)也是一种文件,所以也存在对应的inode。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
目录只是将文件的名称和它的索引节点号结合在一起的一张表,目录中每一对文件名称和索引节点号称为一个连接。
目录中的“..”表示父目录索引节点的指针,以及“.”表当前目录索引节点的指针;这两种目录是隐藏文件,不能删除的。
对于一个文件来说有唯一的索引节点号与之对应,对于一个索引节点号,却可以有多个文件名与之对应。因此,在磁盘上的同一个文件可以通过不同的路径去访问它。后续文章再来讲述链接link。
不同层级的目录构成了目录树,根节点即根目录,Unix/Linux系统为“/”。
超级块中包含了inode节点所在的位置,而第一个inode节点指向的是根目录。这样就可以对目录树进行搜索,从而找到所需要的目录或文件。
注:文件名放在文件所在的目录项中,而不是该文件对应的inode节点中。
参考资料:
《深入理解LINUX内核》第三版。
《操作系统设计与实现》第三版 上册。
《鸟哥的Linux私房菜》基础篇 第四版。
https://www.cnblogs.com/sparkdev/p/11212734.html
https://www.jianshu.com/p/41e206a9880d (fsck tune2fs dumpe2fs)
存储系列之 Linux ext2 概述的更多相关文章
- 存储系列之 从ext2到ext3、ext4 的变化与区别
引言:ext3 和 ext4 对 ext2 进行了增强,但是其核心设计并没有发生变化.所以建议先查看上上篇的<存储系列之 Linux ext2 概述 >,有了ext2的基础,看这篇就是so ...
- Linux EXT2 文件系统
磁盘是用来储文件的,但是必须先把磁盘格式化为某种格式的文件系统,才能存储文件.文件系统的目的就是组织和管理磁盘中的文件.在 Linux 系统中,最长见的是 ext2 系列的文件系统.其早期版本为 ex ...
- linux ext2 文件系统学习
Linux ext2文件系统理解 硬盘组成: 硬盘由多个圆形硬盘片组成.按照硬盘片能够容纳的数据量分为单盘和多盘.硬盘的数据读取主要靠机械手臂上的磁头,在机械手臂上有多个磁头.机械手臂不动硬盘旋转一 ...
- Linux ext2/ext3文件系统详解
转载: Linux ext2/ext3文件系统使用索引节点来记录文件信息,作用像windows的文件分配表.索引节点是一个结构,它包含了一个文件的长度.创建及修改时间.权限.所属关系.磁盘中的位置等信 ...
- 顽石系列:Linux基础笔试
顽石系列:Linux基础笔试 系统操作 压缩文件 扩展名 压缩程序 *.Z compress *.zip zip *.gz gzip *.bz2 bzip2 *.xz xz *.tar tar 程序打 ...
- Spring5.0源码学习系列之事务管理概述
Spring5.0源码学习系列之事务管理概述(十一),在学习事务管理的源码之前,需要对事务的基本理论比较熟悉,所以本章节会对事务管理的基本理论进行描述 1.什么是事务? 事务就是一组原子性的SQL操作 ...
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
- 深入理解javascript函数系列第一篇——函数概述
× 目录 [1]定义 [2]返回值 [3]调用 前面的话 函数对任何一门语言来说都是一个核心的概念.通过函数可以封装任意多条语句,而且可以在任何地方.任何时候调用执行.在javascript里,函数即 ...
- Netty4.x中文教程系列(一) 目录及概述
Netty4.x中文教程系列(一)目录及概述 Netty 提供异步的.事件驱动的网络应用程序框架和工具,用以快速开发高性能.高可靠性的网络服务器和客户端程序. Netty是一个NIO客户端 服务端框架 ...
随机推荐
- JDK11的重要新特性
文章目录 JDK11发布啦 Oracle不再提供JRE和Server JRE下载 删除部署工具 JavaFX不再包含在JDK中 删除Java EE和CORBA模块 JDK11发布啦 JDK11 在20 ...
- HDU 4009 Transfer water(最小树形图)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4009 题意:给出一个村庄(x,y,z).每个村庄可以挖井或者修建水渠从其他村庄得到水.挖井有一个代价, ...
- Nakamori Akina
听过中森明菜的歌以后,一直想写点什么.恰好前段时间看过她的一个访谈https://b23.tv/av13810011,节目里已经39岁左右的她看着已经有些衰老,但是那份属于她的天真却保持的很好. 节目 ...
- Mac查看与修改系统默认shell
Mac查看与修改系统默认shell 查看所有shell cat /etc/shells 输出: # List of acceptable shells for chpass(1). # Ftpd wi ...
- 数学--数论--Hdu 5793 A Boring Question (打表+逆元)
There are an equation. ∑0≤k1,k2,⋯km≤n∏1⩽j<m(kj+1kj)%1000000007=? We define that (kj+1kj)=kj+1!kj! ...
- 数学--数论--HDU 2197 本原串 (推规律)
由0和1组成的串中,不能表示为由几个相同的较小的串连接成的串,称为本原串,有多少个长为n(n<=100000000)的本原串? 答案mod2008. 例如,100100不是本原串,因为他是由两个 ...
- mock-server 之 mock 接口测试
1.mock 介绍 mock 除了用在单元测试过程中,还有一个用途,当前端开发在开发页面的时候,需要服务端提供 API 接口,此时服务端没开发完成,或者说没搭建测试环境,这个时候前端开发会自己 moc ...
- Python爬虫(三)爬淘宝MM图片
直接上代码: # python2 # -*- coding: utf-8 -*- import urllib2 import re import string import os import shu ...
- 从0开始学自定义View -1
PS:好久没有写博客了,之前的东西有所忘记,百度一下竟然查到了自己的写过的博客,访问量还可以,一开始的写博客的初衷是把自己不会的记录下来,现在没想到也有博友会关注我,这就给了我动力,工作之余把零零碎碎 ...
- 解决json字符串转为对象时LocalDateTime异常问题
1 出现异常 这次的异常出现在前端向后端发送请求体里带了两个日期,在后端的实体类中,这两个日期的格式都是JDK8中的时间类LocalDateTime.默认情况下,LocalDateTime只能解析20 ...