Python Download Image (python + requests + BeautifulSoup)
环境准备
1 python + requests + BeautifulSoup
页面准备
主页面:
http://www.netbian.com/dongman/
图片伪地址:
http://www.netbian.com/desk/22371.htm
图片真实地址:
http://img.netbian.com/file/2019/1221/36eb674ba0633d185da078804a3638e6.jpg
步骤
1 导入库
import requestsfrom bs4 import BeautifulSoupimport re
2 更改请求头
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"# "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",# "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",# "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",# "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",# "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",# "Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
3 获取主页面的内容
response = requests.get(url, headers={'User-Agent': ua})html = response.textsoup = BeautifulSoup(html, 'html.parser')
4 我们要的是main里的list中的li标签中的a标签的href,而不是a标签里的img标签的src,若时获取img里的地址其大小为 800*450
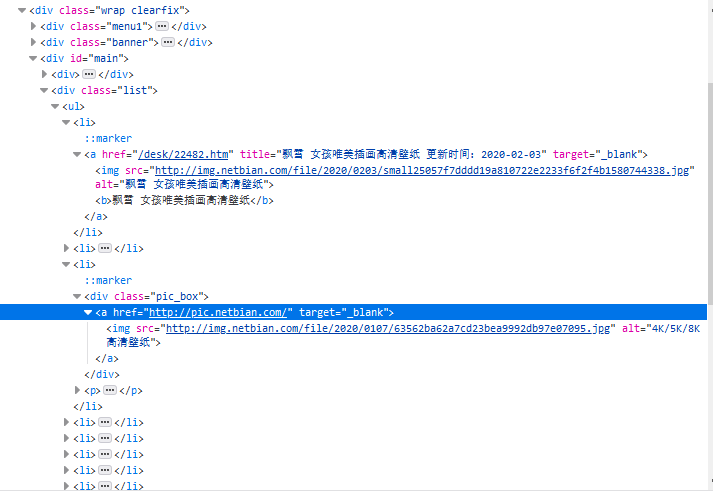
list = soup.find(name='div', attrs='list')for li in list.find_all('li'):# print(img.attrs['src'])for a in li.children:if a.name == 'a':src = 'http://www.netbian.com' + a.attrs['href']
5 截取连接里的数字作为图片的名称(这里可以自己想怎么弄就怎么弄)
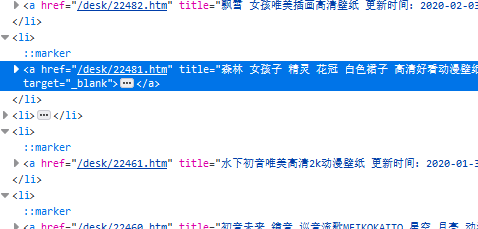
n = re.search(r'\d+', a.attrs['href'])[0] # 这里是\d+,而不是\d{5},是为了避免万一只出现4个数字,则会报错
6 到达真实图片地址
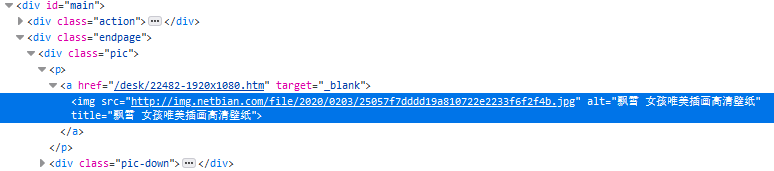
res = requests.get(src, headers={'User-Agent': ua})s = BeautifulSoup(res.text, 'html.parser')p = s.find(name='p')# print(p)img = p.img.attrs['src']# print(img)# 判断地址是否为空if not img:continue
7 下载
with requests.get(img, headers={'User-Agent': ua}) as resp:# print(resp.status_code)resp.raise_for_status()resp.encoding = res.apparent_encoding# 将图片内容写入with open('E://paper//{}.jpg'.format(n), 'wb') as f:f.write(resp.content)f.close()
8 若要下载所有的图片

# 页数循环for i in range(1, 139):if i == 1:url = 'http://www.netbian.com/dongman/index.htm'else:url = 'http://www.netbian.com/dongman/index_{}.htm'.format(i)# print(url)
9 结果

注:
若会Xpath的话,用Xpath会比BeautifulSoup要简单点,我自己是懒得改过去了。
Python Download Image (python + requests + BeautifulSoup)的更多相关文章
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 一个超实用的python爬虫功能使用 requests BeautifulSoup
一个简单的数据爬取的示例 import os,re import requests import random import time from bs4 import BeautifulSoup us ...
- Python 爬虫—— requests BeautifulSoup
本文记录下用来爬虫主要使用的两个库.第一个是requests,用这个库能很方便的下载网页,不用标准库里面各种urllib:第二个BeautifulSoup用来解析网页,不然自己用正则的话很烦. req ...
- python库:bs4,BeautifulSoup库、Requests库
Beautiful Soup https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ Beautiful Soup 4.2.0 文档 htt ...
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python 爬虫(一) requests+BeautifulSoup 爬取简单网页代码示例
以前搞偷偷摸摸的事,不对,是搞爬虫都是用urllib,不过真的是很麻烦,下面就使用requests + BeautifulSoup 爬爬简单的网页. 详细介绍都在代码中注释了,大家可以参阅. # -* ...
- [python] 网络数据采集 操作清单 BeautifulSoup、Selenium、Tesseract、CSV等
Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesseract.CSV等 Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesse ...
随机推荐
- day46_Webservice学习笔记_02
一.回顾昨天所学 什么是webservice? 什么是远程调用技术?答:系统和系统之间的调用,从远程系统当中获取业务数据. Webservice是web服务,他是用http传输SOAP协议 ...
- 201771010135杨蓉庆《面向对象程序设计(java)》第四周学习总结
学习目标 1.掌握类与对象的基础概念,理解类与对象的关系: 2.掌握对象与对象变量的关系: 3.掌握预定义类的基本使用方法,熟悉Math类.String类.math类.Scanner类.LocalDa ...
- 样式计算的几种方式与兼容写法:getComputedStyle¤tStyle&style
window.getComputedStyle(element,[string]) 1参为需要获取样式的元素,2参指定伪元素字符串(如“::after”,不需要则为null),设置2参可获取eleme ...
- java程序设计课期中考试——数据库的增删改查和简单的js界面
首先是设计思路,对于数据库的增删改查,我们借助Ecilipse来进行前端和后端的编写.Ecilipse是可以进行java web项目的操作的. 前端,我们选择用使用jsp,所谓的jsp就是可以嵌入其他 ...
- Android Studio 配置Gradle
一, 问题:①换个新电脑安装完Android Sutdio第一次打开一个工程巨慢怎么办?② 手动配置Gradle Home为什么总是无效?③ 明明已经下载了Gradle,配置了gradle home, ...
- MySQL高级 InnoDB 和 MyISAM 的区别
InnoDB:支持事务处理等不加锁读取支持外键支持行锁不支持FULLTEXT类型的索引不保存表的具体行数,扫描表来计算有多少行DELETE 表时,是一行一行的删除InnoDB 把数据和索引存放在表空间 ...
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 记数问题(0)<P2013_1>
记数问题 (count.cpp/c/pas) [问题描述] 试计算在区间1到n的所有整数中,数字x(0≤x≤9)共出现了多少次?例如,在1到11中,即在1.2.3.4.5.6.7.8.9.10.11 ...
- Java基础知识笔记第六章:接口
接口 /* 使用关键字interface来定义一个接口.接口的定义和类的定义很相似,分为接口声明和接口体 */ interface Printable{ final int max=100; void ...
- nginx 与上游服务器建立连接的相关设置
向上游服务建立联系 Syntax: proxy_connect_timeout time; #设置TCP三次握手超时时间,默认60秒:默认超时后报502错误 Default: proxy_connec ...