intel关于spark gc的优化建议
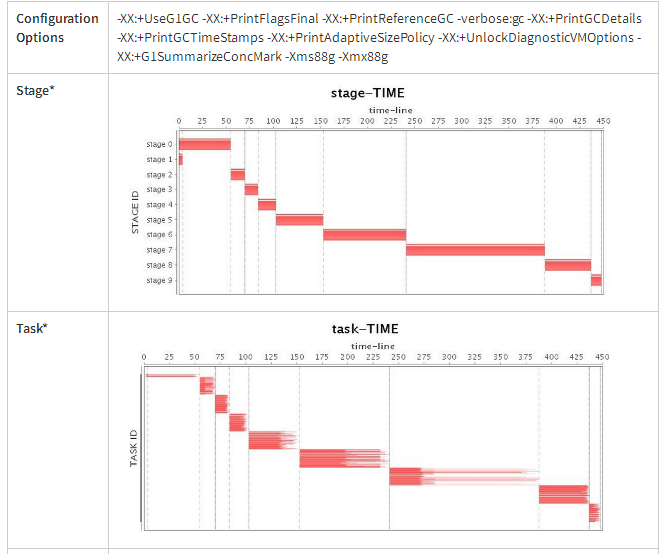



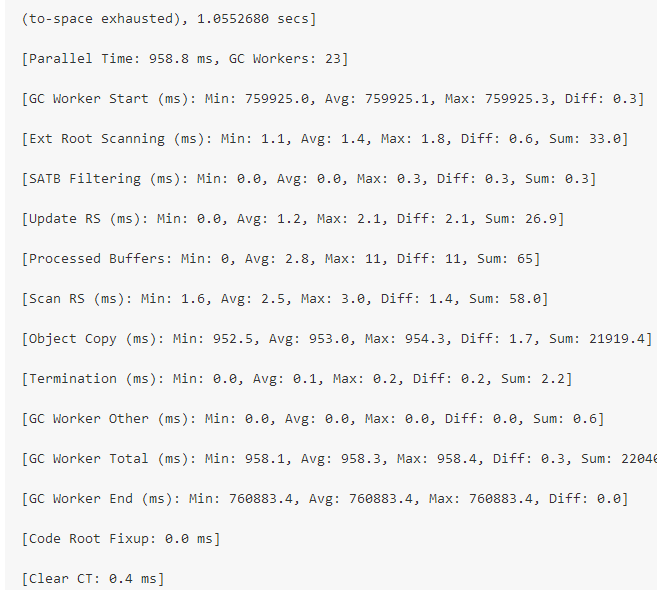
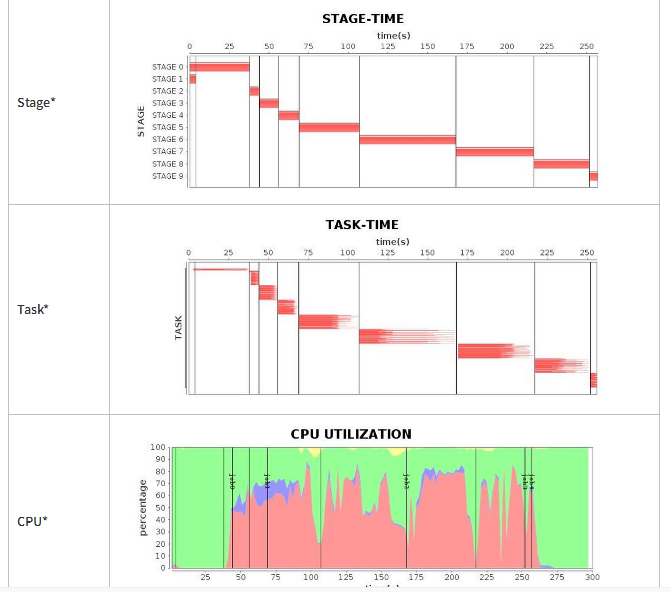
原文:
https://databricks.com/blog/2015/05/28/tuning-java-garbage-collection-for-spark-applications.html?from=timeline
intel关于spark gc的优化建议的更多相关文章
- SparkSQL的一些用法建议和Spark的性能优化
1.写在前面 Spark是专为大规模数据处理而设计的快速通用的计算引擎,在计算能力上优于MapReduce,被誉为第二代大数据计算框架引擎.Spark采用的是内存计算方式.Spark的四大核心是Spa ...
- .NET程序的性能要领和优化建议
前几天在老赵的博客上看到,Bill Chiles (Roslyn 编译器的Program Manager)写了一篇文章叫做<Essential Performance Facts and .NE ...
- Unity开发-你必须知道的优化建议
转自:http://blog.csdn.net/leonwei/article/details/18042603 最近研究U3D开发,个人认为,精通一种新的技术,最快最好的方法就是看它的documen ...
- unity优化建议
使用Profiler工具分析内存占用情况 System.ExecutableAndDlls:系统可执行程序和DLL,是只读的内存,用来执行所有的脚本和DLL引用.不同平台和不同硬件得到的值会不一样,可 ...
- OCM_第十四天课程:Section6 —》数据库性能调优_各类索引 /调优工具使用/SQL 优化建议
注:本文为原著(其内容来自 腾科教育培训课堂).阅读本文注意事项如下: 1:所有文章的转载请标注本文出处. 2:本文非本人不得用于商业用途.违者将承当相应法律责任. 3:该系列文章目录列表: 一:&l ...
- [转] - Spark排错与优化
Spark排错与优化 http://blog.csdn.net/lsshlsw/article/details/49155087 一. 运维 1. Master挂掉,standby重启也失效 Mast ...
- Unity 几种优化建议
转: http://user.qzone.qq.com/289422269/blog/1453815561?ptlang=2052 Unity 几种优化建议 最简单的优化建议: 1.PC平台的话保持场 ...
- mysql性能优化学习笔记-参数介绍及优化建议
MySQL服务器参数介绍 mysql参数介绍(客户端中执行),尽量只修改session级别的参数. 全局参数(新连接的session才会生效,原有已经连接的session不生效) set global ...
- Jquery学习笔记--性能优化建议
一.选择器性能优化建议 1. 总是从#id选择器来继承 这是jQuery选择器的一条黄金法则.jQuery选择一个元素最快的方法就是用ID来选择了. 1 $('#content').hide(); 或 ...
随机推荐
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- base64相关
1.base64指定的64个字符(包含52个大小写.10个数字和+./): abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 ...
- From scratch 资源
neural-network-from-scratch:https://github.com/pangolulu/neural-network-from-scratch rnn-from-scratc ...
- 计算机网络 - TCP/IP模型
图片来自网上资料
- 2.9 logistic回归中的梯度下降法(非常重要,一定要重点理解)
怎么样计算偏导数来实现logistic回归的梯度下降法 它的核心关键点是其中的几个重要公式用来实现logistic回归的梯度下降法 接下来开始学习logistic回归的梯度下降法 logistic回归 ...
- Nvidia发布更快、功耗更低的新一代图形加速卡
导读 不出意外的,Nvidia在其举行的Supercomputing 19大会上公布了很多新闻,这些我们将稍后提到.但被忽略的一条或许是其中最有趣的:一张更快.功耗更低的新一代图形加速卡. 多名与会者 ...
- 修改vue中的挂载页面(index.html)的路径
修改vue中的挂载页面(index.html)的路径 2019年03月30日 12:07:12 VegasLemon 阅读数 501 版权声明:本文为博主原创文章,未经博主允许不得转载. htt ...
- Linux centosVMware Tomcat介绍、安装jdk、安装Tomcat
一.Tomcat介绍 Tomcat是Apache软件基金会(Apache Software Foundation)的Jakarta项目中的一个核心项目,由Apache.Sun和其他一些公司及个人共同开 ...
- C++11 — lambda表达式(匿名函数)
C++11中lambda表达式的基本语法格式为: [capture](parameters) -> return_type { /* ... */ } 其中 [] 内为外部变量的传递方式: [] ...
- FFmpeg——命令笔记
1. 获取 dshow设备列表 ffmpeg -list_devices true -f dshow -i dummy 2. 通过UDP流推ts文件: ffmpeg.exe -re -i zhen.t ...