【转】分布式架构的演进(JavaWeb)
作者:李小翀
链接:https://www.zhihu.com/question/22764869/answer/31277656
来源:知乎
1.初始
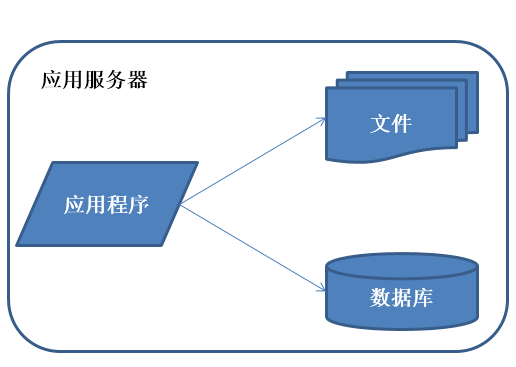
初始阶段 的小型系统 应用程序、数据库、文件等所有的资源都在一台服务器上通俗称为LAMP特征:应用程序、数据库、文件等所有的资源都在一台服务器上。描述:通常服务器操作系统使用linux,应用程序使用JSP/PHP/ASP开发,然后部署在Apache上,数据库使用Mysql,汇集各种免费开源软件以及一台廉价服务器就可以开始系统的发展之路了。
特征:
应用程序、数据库、文件等所有的资源都在一台服务器上。
描述:
通常服务器操作系统使用linux,应用程序使用PHP开发,然后部署在Apache上,数据库使用Mysql,汇集各种免费开源软件以及一台廉价服务器就可以开始系统的发展之路了
2.应用服务和数据服务分离
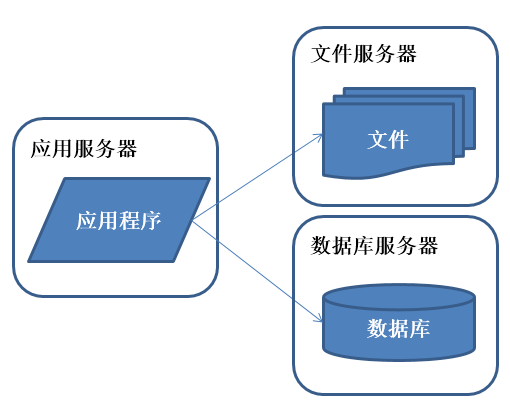
好景不长,发现随着系统访问量的再度增加,webserver机器的压力在高峰期会上升到比较高,这个时候开始考虑增加一台webserver
特征:
应用程序、数据库、文件分别部署在独立的资源上。
描述:
数据量增加,单台服务器性能及存储空间不足,需要将应用和数据分离,并发处理能力和数据存储空间得到了很大改善。
3.使用缓存提高性能
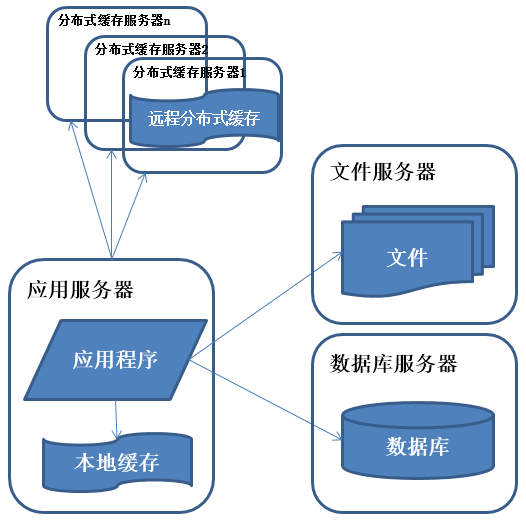
特征:
数据库中访问较集中的一小部分数据存储在缓存服务器中,减少数据库的访问次数,降低数据库的访问压力。
描述:
系统访问特点遵循二八定律,即80%的业务访问集中在20%的数据上。
缓存分为本地缓存和远程分布式缓存,本地缓存访问速度更快但缓存数据量有限,同时存在与应用程序争用内存的情况。
4.应用服务器集群
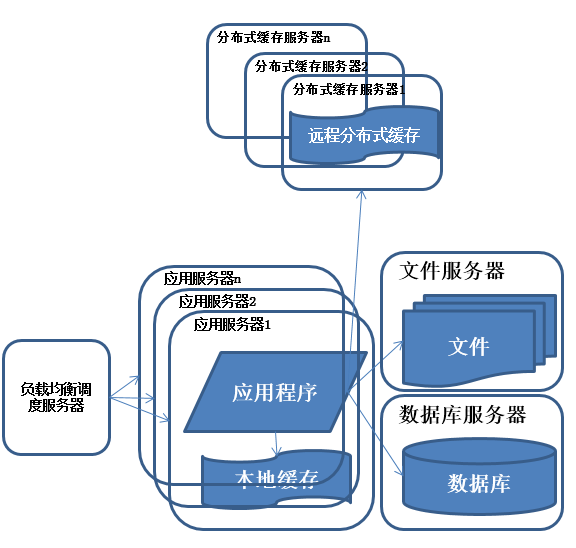
在做完分库分表这些工作后,数据库上的压力已经降到比较低了,又开始过着每天看着访问量暴增的幸福生活了,突然有一天,发现系统的访问又开始有变慢的趋势了,这个时候首先查看数据库,压力一切正常,之后查看webserver,发现apache阻塞了很多的请求,而应用服务器对每个请求也是比较快的,看来 是请求数太高导致需要排队等待,响应速度变慢
特征:
多台服务器通过负载均衡同时向外部提供服务,解决单台服务器处理能力和存储空间上限的问题。
描述:
使用集群是系统解决高并发、海量数据问题的常用手段。通过向集群中追加资源,提升系统的并发处理能力,使得服务器的负载压力不再成为整个系统的瓶颈。
5.数据库读写分离
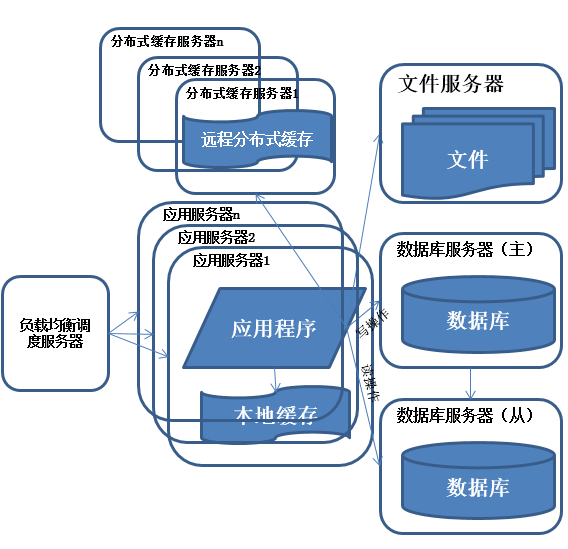
享受了一段时间的系统访问量高速增长的幸福后,发现系统又开始变慢了,这次又是什么状况呢,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的资源竞争非常激烈,导致了系统变慢
特征:
多台服务器通过负载均衡同时向外部提供服务,解决单台服务器处理能力和存储空间上限的问题。
描述:
使用集群是系统解决高并发、海量数据问题的常用手段。通过向集群中追加资源,使得服务器的负载压力不在成为整个系统的瓶颈。
6.反向代理和CDN加速
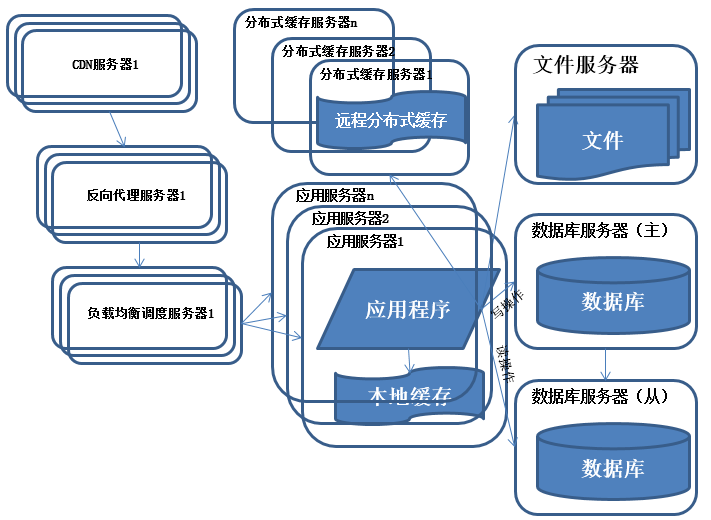
特征:
采用CDN和反向代理加快系统的 访问速度。
描述:
为了应付复杂的网络环境和不同地区用户的访问,通过CDN和反向代理加快用户访问的速度,同时减轻后端服务器的负载压力。CDN与反向代理的基本原理都是缓存。
7.分布式文件系统和分布式数据库
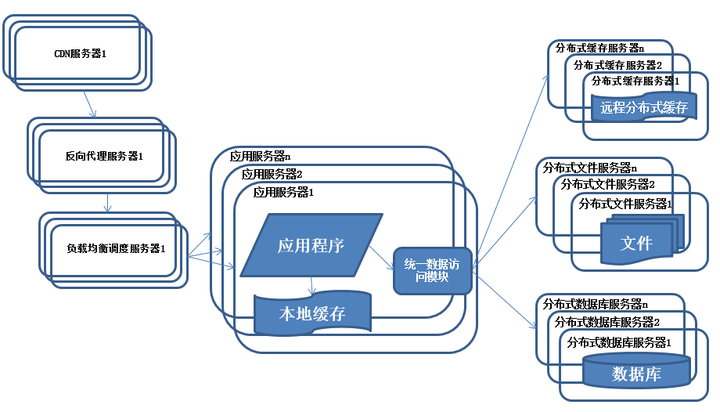
随着系统的不断运行,数据量开始大幅度增长,这个时候发现分库后查询仍然会有些慢,于是按照分库的思想开始做分表的工作
特征:
数据库采用分布式数据库,文件系统采用分布式文件系统。
描述:
任何强大的单一服务器都满足不了大型系统持续增长的业务需求,数据库读写分离随着业务的发展最终也将无法满足需求,需要使用分布式数据库及分布式文件系统来支撑。
分布式数据库是系统数据库拆分的最后方法,只有在单表数据规模非常庞大的时候才使用,更常用的数据库拆分手段是业务分库,将不同的业务数据库部署在不同的物理服务器上。
8.使用NoSQL和搜索引擎
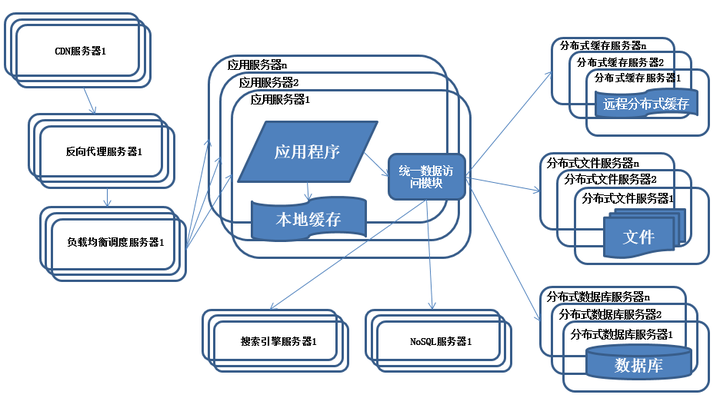
特征:
系统引入NoSQL数据库及搜索引擎。
描述:
随着业务越来越复杂,对数据存储和检索的需求也越来越复杂,系统需要采用一些非关系型数据库如NoSQL和分数据库查询技术如搜索引擎。应用服务器通过统一数据访问模块访问各种数据,减轻应用程序管理诸多数据源的麻烦。
9.业务拆分
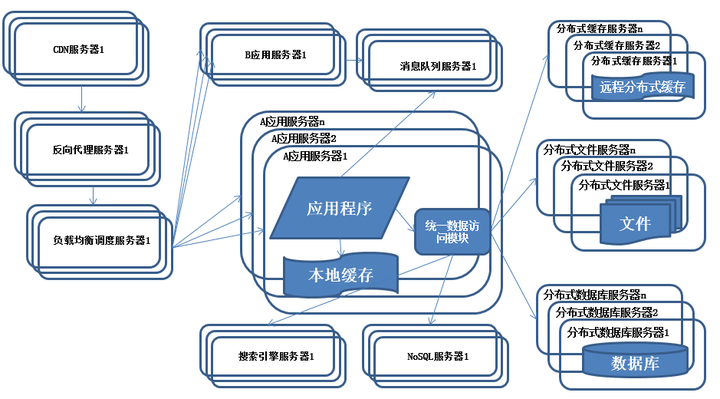
特征:
系统上按照业务进行拆分改造,应用服务器按照业务区分进行分别部署。
描述:
为了应对日益复杂的业务场景,通常使用分而治之的手段将整个系统业务分成不同的产品线,应用之间通过超链接建立关系,也可以通过消息队列进行数据分发,当然更多的还是通过访问同一个数据存储系统来构成一个关联的完整系统。
纵向拆分:
将一个大应用拆分为多个小应用,如果新业务较为独立,那么就直接将其设计部署为一个独立的Web应用系统
纵向拆分相对较为简单,通过梳理业务,将较少相关的业务剥离即可。
横向拆分:
将复用的业务拆分出来,独立部署为分布式服务,新增业务只需要调用这些分布式服务
横向拆分需要识别可复用的业务,设计服务接口,规范服务依赖关系。
10.分布式服务
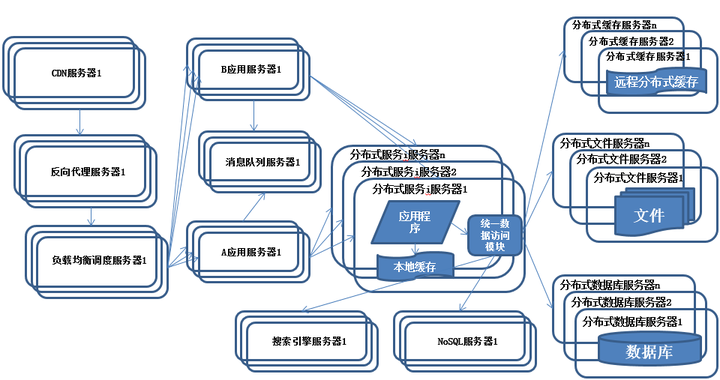
特征:
公共的应用模块被提取出来,部署在分布式服务器上供应用服务器调用。
描述:
随着业务越拆越小,应用系统整体复杂程度呈指数级上升,由于所有应用要和所有数据库系统连接,最终导致数据库连接资源不足,拒绝服务。
【转】分布式架构的演进(JavaWeb)的更多相关文章
- JAVA分布式架构的演进
系统架构演化历程-初始阶段架构 初始阶段 的小型系统 应用程序.数据库.文件等所有的资源都在一台服务器上通俗称为LAMP 特征:应用程序.数据库.文件等所有的资源都在一台服务器上. 描述:通常服务器操 ...
- 大型Java web项目分布式架构演进-分布式部署
http://blog.csdn.net/binyao02123202/article/details/32340283/ 知乎相关文章https://www.zhihu.com/question/2 ...
- 深入理解java:5. Java分布式架构
什么是分布式架构 分布式系统(distributed system)是建立在网络之上的软件系统. 内聚性是指每一个数据库分布节点高度自治,有本地的数据库管理系统. 透明性是指每一个数据库分布节点对用户 ...
- (五):C++分布式实时应用框架——微服务架构的演进
C++分布式实时应用框架--微服务架构的演进 上一篇:(四):C++分布式实时应用框架--状态中心模块 版权声明:本文版权及所用技术归属smartguys团队所有,对于抄袭,非经同意转载等行为保留法律 ...
- 资深P7架构师详解淘宝服务端高并发分布式架构演进之路
1. 概述 本文以淘宝作为例子,介绍从一百个并发到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让大家对架构的演进有一个整体的认知,文章最后汇总了一些架构设计的原则. ...
- 服务端高并发分布式架构演进之路 转载,原文地址:https://segmentfault.com/a/1190000018626163
1. 概述 本文以淘宝作为例子,介绍从一百个到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让大家对架构的演进有一个整体的认知,文章最后汇总了一些架构设计的原则. 特 ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_2_01传统架构演进到分布式架构
笔记 第二章 架构演进和分布式系统基础知识 1.传统架构演进到分布式架构 简介:讲解单机应用和分布式应用架构演进基础知识 (画图) 高可用 LVS+keepalive :负载均衡的知识点 1. ...
- 阿里P8架构师深度概述分布式架构
简介 作为一名架构师,我们要专业,要能看懂代码,及时光着臂膀去机房,也能独挡一面!及时同事搞不定问题,或者撂挑子,你也能给老大一个坚定的眼神:不怕,有我在!还能在会议室上滔滔不绝,如若无人,让不懂技术 ...
- OceanBase迁移服务:向分布式架构升级的直接路径
2019年1月4日,OceanBase迁移服务解决方案在ATEC城市峰会中正式发布.蚂蚁金服资深技术专家师文汇和技术专家韩谷悦共同分享了OceanBase迁移服务的重要特性和业务实践. 蚂蚁数据库架构 ...
随机推荐
- 国产ROM纷争升级 能否诞生终结者?
能否诞生终结者?" title="国产ROM纷争升级 能否诞生终结者?"> 相比iOS系统的低硬件高流畅,安卓系统就显得"逼格"低了许多.先不说 ...
- URL与URI与URN的区别与联系
1.什么是URL? 统一资源定位符(或称统一资源定位器/定位地址.URL地址等[1],英语:Uniform Resource Locator,常缩写为URL),有时也被俗称为网页地址(网址).如同在网 ...
- 吴裕雄--天生自然KITTEN编程:躲迷藏
- python基础函数、方法
python的函数和方法,通过def 定义: 函数的特性: 减少重复代码 使程序变的可扩展 使程序变得易维护 函数和方法的区别:函数有返回值.方法没有 语法定义: def sayhi():#函数名 p ...
- iOS多线程开发之GCD(中级篇)
前文回顾: 上篇博客讲到GCD的实现是由队列和任务两部分组成,其中获取队列的方式有两种,第一种是通过GCD的API的dispatch_queue_create函数生成Dispatch Queue:第二 ...
- Linux下多线程复制文件(C)
Linux下实现多线程文件复制,使用<pthread.h>提供的函数: int pthread_create(pthread_t *thread,const pthread_attr_t ...
- LeetCode 31:递归、回溯、八皇后、全排列一篇文章全讲清楚
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天我们讲的是LeetCode的31题,这是一道非常经典的问题,经常会在面试当中遇到.在今天的文章当中除了关于题目的分析和解答之外,我们还会 ...
- 我去,你写的 switch 语句也太老土了吧
昨天早上通过远程的方式 review 了两名新来同事的代码,大部分代码都写得很漂亮,严谨的同时注释也很到位,这令我非常满意.但当我看到他们当中有一个人写的 switch 语句时,还是忍不住破口大骂:& ...
- 强大的java工作流引擎,可视化开发工作流
我们先来看看什么是工作流? 所谓工作流引擎是指workflow作为应用系统的一部分,并为之提供对各应用系统有决定作用的根据角色.分工和条件的不同决定信息传递路由.内容等级等核心解决方案.工作流引擎包括 ...
- web前端 关于浏览器兼容的一些知识和问题解决
浏览器兼容 为什么产生浏览器兼容,浏览器兼容问题什么是浏览器兼容: 所谓的浏览器兼容性问题,是指因为不同的浏览器对同一段代码有不同的解析,造成页面显示效果不统一的情况. 浏览器兼容产生的原因: 因为不 ...