2-10 就业课(2.0)-oozie:11、hadoop的federation(联邦机制,了解一下)
====================================================
Hadoop Federation
背景概述
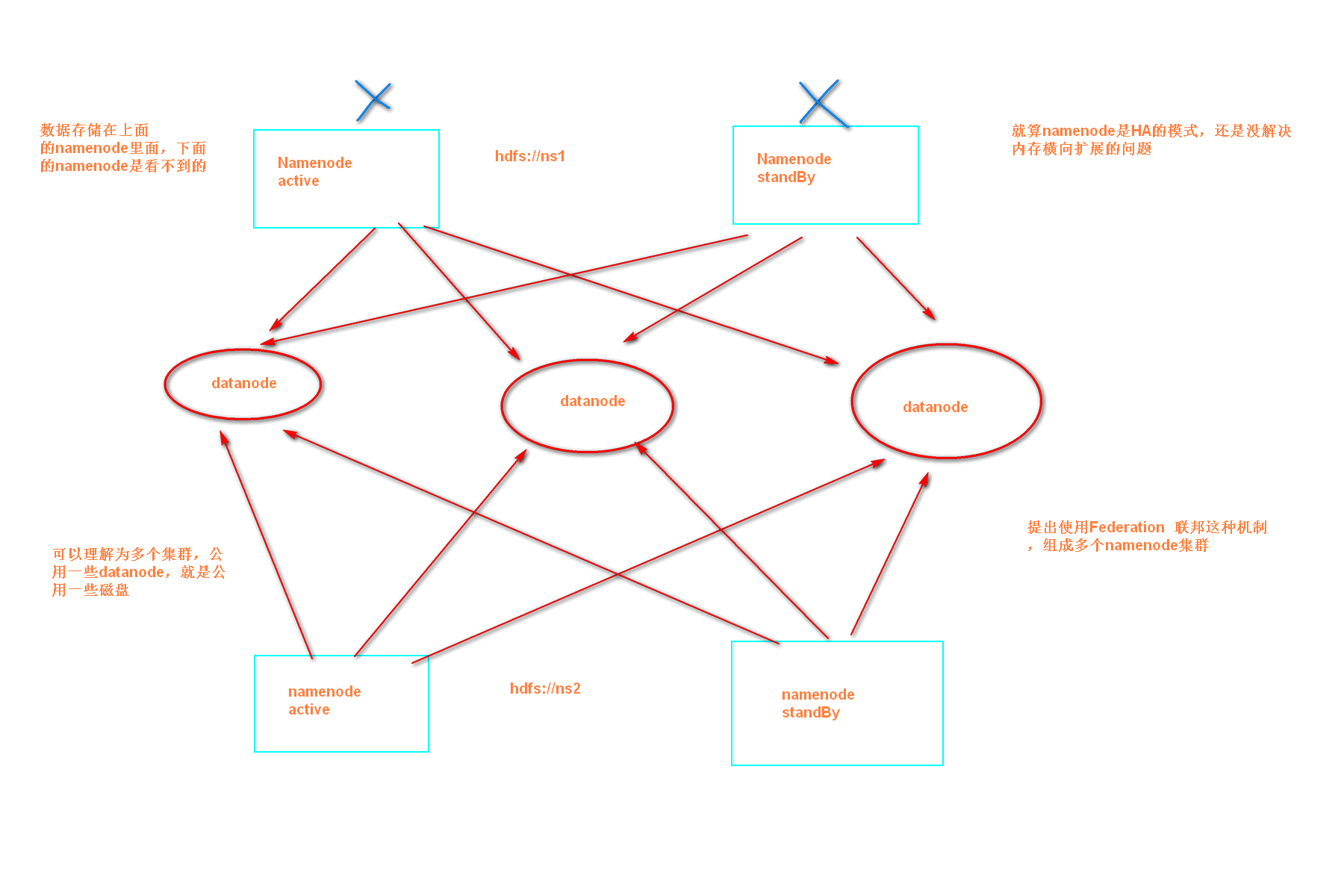
单NameNode的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode成为了性能的瓶颈。因而提出了namenode水平扩展方案-- Federation。
Federation中文意思为联邦,联盟,是NameNode的Federation,也就是会有多个NameNode。多个NameNode的情况意味着有多个namespace(命名空间),区别于HA模式下的多NameNode,它们是拥有着同一个namespace。既然说到了NameNode的命名空间的概念,这里就看一下现有的HDFS数据管理架构,如下图所示:
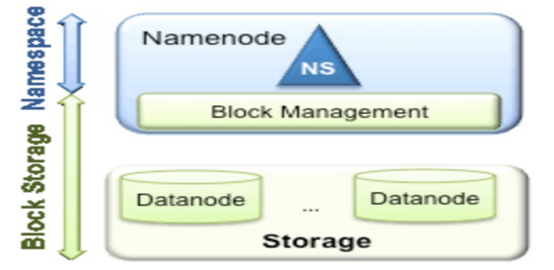
从上图中,我们可以很明显地看出现有的HDFS数据管理,数据存储2层分层的结构.也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下.而这些隶属于同一个NameNode所管理的数据都是在同一个命名空间下的.而一个namespace对应一个block pool。Block Pool是同一个namespace下的block的集合.当然这是我们最常见的单个namespace的情况,也就是一个NameNode管理集群中所有元数据信息的时候.如果我们遇到了之前提到的NameNode内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高NameNode的jvm大小绝对不是一个持久的办法.这时候就诞生了HDFS Federation的机制.
Federation架构设计
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。
Federation意味着在集群中将会有多个namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
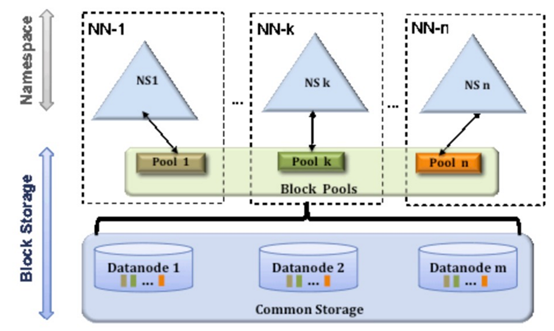
Federation一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的。
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的datadir所在目录里面查看BP-xx.xx.xx.xx打头的目录)。
概括起来:
多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务。
每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储。
DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况。
HDFS Federation不足
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
所以一般集群规模真的很大的时候,会采用HA+Federation的部署方案。也就是每个联合的namenodes都是ha的。
Federation示例配置
这是一个包含两个Namenode的Federation示例配置:
|
<configuration> <property> <name>dfs.nameservices</name> <value>ns1,ns2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1</name> <value>nn-host1:rpc-port</value> </property> <property> <name>dfs.namenode.http-address.ns1</name> <value>nn-host1:http-port</value> </property> <property> <name>dfs.namenode.secondaryhttp-address.ns1</name> <value>snn-host1:http-port</value> </property> <property> <name>dfs.namenode.rpc-address.ns2</name> <value>nn-host2:rpc-port</value> </property> <property> <name>dfs.namenode.http-address.ns2</name> <value>nn-host2:http-port</value> </property> <property> <name>dfs.namenode.secondaryhttp-address.ns2</name> <value>snn-host2:http-port</value> </property> .... Other common configuration ... </configuration> |
2-10 就业课(2.0)-oozie:11、hadoop的federation(联邦机制,了解一下)的更多相关文章
- 2-10 就业课(2.0)-oozie:10、伪分布式环境转换为HA集群环境
hadoop 的基础环境增强 HA模式 HA是为了保证我们的业务 系统 7 *24 的连续的高可用提出来的一种解决办法,现在hadoop当中的主节点,namenode以及resourceManager ...
- 2-10 就业课(2.0)-oozie:9、oozie与hue的整合,以及整合后执行MR任务
5.hue整合oozie 第一步:停止oozie与hue的进程 通过命令停止oozie与hue的进程,准备修改oozie与hue的配置文件 第二步:修改oozie的配置文件(老版本的bug,新版本已经 ...
- 2-10 就业课(2.0)-oozie:12、cm环境搭建的基础环境准备
8.clouderaManager5.14.0环境安装搭建 Cloudera Manager是cloudera公司提供的一种大数据的解决方案,可以通过ClouderaManager管理界面来对我们的集 ...
- 2-10 就业课(2.0)-oozie:8、定时任务的执行
4.5.oozie的任务调度,定时任务执行 在oozie当中,主要是通过Coordinator 来实现任务的定时调度,与我们的workflow类似的,Coordinator 这个模块也是主要通过xml ...
- 2-10 就业课(2.0)-oozie:5、通过oozie执行hive的任务
4.2.使用oozie调度我们的hive 第一步:拷贝hive的案例模板 cd /export/servers/oozie-4.1.0-cdh5.14.0 cp -ra examples/apps/h ...
- 2-10 就业课(2.0)-oozie:13、14、clouderaManager的服务搭建
3.clouderaManager安装资源下载 第一步:下载安装资源并上传到服务器 我们这里安装CM5.14.0这个版本,需要下载以下这些资源,一共是四个文件即可 下载cm5的压缩包 下载地址:htt ...
- 2-10 就业课(2.0)-oozie:7、job任务的串联
4.4.oozie的任务串联 在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个ac ...
- 2-10 就业课(2.0)-oozie:6、通过oozie执行mr任务,以及执行sqoop任务的解决思路
执行sqoop任务的解决思路(目前的问题是sqoop只安装在node03上,而oozie会随机分配一个节点来执行任务): ======================================= ...
- 2-10 就业课(2.0)-oozie:4、通过oozie执行shell脚本
oozie的配置文件job.properties:里面主要定义的是一些key,value对,定义了一些变量,这些变量往workflow.xml里面传递workflow.xml :workflow的配置 ...
随机推荐
- php 基础 PHP保留两位小数的几种方法
$num = 10.4567; //第一种:利用round()对浮点数进行四舍五入 echo round($num,2); //10.46 //第二种:利用sprintf格式化字符串 $format_ ...
- SpringBoot简要介绍
一 SpringBoot介绍 1.1 先从Spring谈起 我们知道Spring是重量级企业开发框架 Enterprise JavaBean(EJB) 的替代品,Spring为企业级Java开发提供了 ...
- 【LOJ3087】「GXOI / GZOI2019」旅行者
题意 给定一个 \(n\) 个点 \(m\) 条边的的有向图,给出 \(k\) 个关键点,求关键点两两最短路的最小值. \(n\le 10^5, m\le 5\cdot 10^5\). 题解 二进制分 ...
- 使用SQL语句还原数据库 2012.3.20
--返回由备份集内包含的数据库和日志文件列表组成的结果集. --主要获得逻辑文件名 USE master RESTORE FILELISTONLY FROM DISK = 'g:\back.Bak' ...
- Java基础 -3.5
我觉得上一篇不是很严谨啊 我认为这个逻辑还是正确的 原码.反码.补码: (1)在Java中,所有数据的表示方式都是以补码形式来表示 如果没有特别的说明,Java 中的数据类型默认为int,int数据类 ...
- Spring注解@Qualifier、@Autowired、@Primary
@Qualifier 1.当一个接口有多个实现类,且均已注入到Spring容器中了,使用@AutoWired是byType的,而这些实现类类型都相同,此时就需要使用@Qualifier明确指定使用那个 ...
- js 判断时间大小
//判断结束时间一定要大于开始时间 function comparativeTime(){ var isok=true; //早餐配送时间 var breakfastScanTimeMin = $(& ...
- SAVE 、BGSAVE和BGREWRITEAOF执行区别
rdbSave 会将数据库数据保存到 RDB 文件,并在保存完成之前阻塞调用者. save 命令直接调用 rdbSave ,阻塞 Redis 主进程:bgsave 用子进程调用 rdbSave ,主进 ...
- Py西游攻关之基础数据类型(六)-文件操作
Py西游攻关之基础数据类型 - Yuan先生 https://www.cnblogs.com/yuanchenqi/articles/5782764.html 九 文件操作 9.1 对文件操作流程 打 ...
- Java单例模式:为什么我强烈推荐你用枚举来实现单例模式
单例模式简介 单例模式是 Java 中最简单,也是最基础,最常用的设计模式之一.在运行期间,保证某个类只创建一个实例,保证一个类仅有一个实例,并提供一个访问它的全局访问点.下面就来讲讲Java中的N种 ...