机器学习——十大数据挖掘之一的决策树CART算法
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是机器学习专题的第23篇文章,我们今天分享的内容是十大数据挖掘算法之一的CART算法。
CART算法全称是Classification and regression tree,也就是分类回归树的意思。和之前介绍的ID3和C4.5一样,CART算法同样是决策树模型的一种经典的实现。决策树这个模型一共有三种实现方式,前面我们已经介绍了ID3和C4.5两种,今天刚好补齐这最后一种。
算法特点
CART称为分类回归树,从名字上我们也看得出来,它既能支持分类又可以支持回归。的确如此,决策树的确支持回归操作,但是我们一般不会用决策树来进行回归。这里面的原因很多,除了树模型拟合能力有限效果不一定好之外,还与特征的模式有关系,树回归模型受到特征的影响非常大。这个部分我们不做太多深入,之后会在回归树的文章当中详细探讨。
正因为回归树模型效果表现都不太理想,所以CART算法实现决策树基本都是用来做分类问题。那么在分类问题上,它与之前的ID3算法和C4.5算法又有什么不同呢?
主要细究起来大约有两点,第一点是CART算法使用Gini指数而不是信息增益来作为划分子树的依据,第二点是CART算法每次在划分数据的时候,固定将整份数据拆分成两个部分,而不是多个部分。由于CART每次将数据拆分成两个部分,所以它对于拆分的次数没有限制,而C4.5算法对特征进行了限制,限制了每个特征最多只能使用一次。因为这一点,同样CART对于剪枝的要求更高,因为不剪枝的话很有可能导致树过度膨胀,以至于过拟合。
Gini指数
在ID3和C4.5算法当中,在拆分数据的时候用的是信息增益和信息增益比,这两者都是基于信息熵模型。信息熵模型本身并没有问题,也是非常常用的模型。唯一的问题是,在计算熵的时候需要涉及到log运算,相比于四则运算来说,计算log要多耗时很多。
Gini指数本质上也是基于信息熵模型,只是我们在计算的时候做了一些转化,从而避免了使用log进行计算,加速了计算的过程。两者的内在逻辑是一样的。那怎么实现的加速计算呢?这里用到了高等数学当中的泰勒展开,我们将log运算通过泰勒公式展开,转化成多项式的计算,从而加速信息熵的计算。
我们来做一个简单的推导:
\ln(x) \approx \ln(x_0) + (x-x_0)\ln'(x_0) + o(x)
\end{aligned}
\]
我们把\(x_0 =1\)代入,可以得到:\(\ln(x)=x - 1 + o(x)\),其中o(x)是关于x的高阶无穷小。我们把这个式子套入信息熵的公式当中:
H(x) &= -\sum_{i=1}^k p_i\ln p_i \\
&\approx \sum_{i=1}^k p_i(1-p_i)
\end{aligned}
\]
这个就是Gini指数的计算公式,这里的pi表示类别i的概率,其实就是类别i的样本占全体样本的比例。那么上面的式子也可以看成是从数据集当中抽取两条样本,它们类别不一致的概率。
因此Gini指数越小,说明数据集越集中,也就是纯度越高。它的概念等价于信息熵,熵越小说明信息越集中,两者的概念是非常近似的。所以当我们使用Gini指数来作为划分依据的时候,选择的是切分之后Gini指数尽量小的切分方法,而不是尽量大的。
从上面的公式当中,我们可以发现相比于信息熵的log运算,Gini指数只需要简单地计算比例和基础运算就可以得到结果了,显然运算速度要快得多。并且由于是通过泰勒展开逼近的,整体的性能也并不差,我们可以看下下面这张经典的图感受一下:
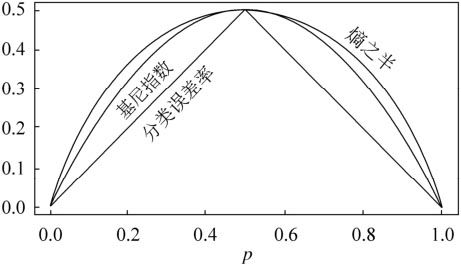
从上图当中可以看出来,Gini指数和信息熵的效果非常接近,一样可以非常好地反应数据划分的纯度。
拆分与剪枝
刚才我们介绍CART算法特性的时候提到过,CART算法每次拆分数据都是二分的,这点和C4.5处理连续性特征的逻辑很像。但有两点不同,第一点是CART对于离散型和连续性特征都如此操作,另外一点是,CART算法当中一个特征可以重复使用。
举个例子,在之前的算法当中,比如说西瓜的直径是一个特征。那么当我们判断过西瓜的直径小于10cm之后,西瓜的直径这个特征就会从数据当中移除,之后再也不会用到。但是在CART算法当中不是如此,比如当我们先后根据西瓜的直径以及西瓜是否有藤这两个特征对数据进行拆分之后,对于ID3和C4.5算法来说,西瓜的直径这个特征已经不可以再用来作为划分的依据了,但是CART算法当中可以,我们仍然可以继续使用之前已经用过的特征。
我们用一张图来展示,大概是下面这个样子:

我们观察一下最左侧的子树,直径这个特征出现了不止一次,这其实是很合理的。然而这也会有一个问题,就是由于没有了特征只能用一次这个限制,这样会导致这棵树无限膨胀,尤其是在连续性特征很多的情况下,很容易陷入过拟合。为了放置过拟合,增加模型的泛化能力,我们需要对生成的这棵树进行剪枝。
剪枝的方案主流的有两种,一种是预剪枝,一种是后剪枝。所谓的预剪枝,即是在生成树的时候就对树的生长进行限制,防止过度拟合。而后剪枝则是在树已经生成之后,对过拟合的部分进行修剪。其中预剪枝比较容易理解,比如我们可以限制决策树在训练的时候每个节点的数据只有在达到一定数量的情况下才会进行分裂,否则就成为叶子节点保留。或者我们可以限制数据的比例,当节点中某个类别的占比超过阈值的时候,也可以停止生长。
后剪枝相对来说复杂一些,需要我们在生成树之后通过一些机制寻找可以剪枝的部分,对整棵树进行修剪。比如在CART算法当中常用的剪枝策略是CCP,它的英文全写是Cost-Complexity Pruning,即代价复杂度剪枝。这个策略设计了一个指标来衡量一棵子树的复杂度代价,我们可以对这个代价设置阈值来进行剪枝。
这个策略的精髓在于下面这个式子:
\]
这个式子当中的c就是指的剪枝带来的代价,t代表剪枝之后的子树,\(T_t\)表示剪枝之前的子树。R(t)表示剪枝之后的误差代价,\(R(T_t)\)表示剪枝之前的误差代价。其中误差代价的定义是:\(R(t) = r(t) * p(t)\),r(t)是节点t的误差率,p(t)是t上数据占所有数据的比例。
我们来看个例子:

假设我们知道所有数据一共有100条,那么我们代入公式算一下,可以得到\(R(t) = r(t) * p(t) = \frac{11}{23} * \frac{23}{100} = \frac{11}{100}\)
子树的误差代价是:
\]
所以可以得到\(c=\frac{11/100 - 4/100}{3 - 1}=\frac{7}{200}\)
c越大说明剪枝带来的偏差越大,也就是说越不能剪,相反c很小说明偏差不大,可以减掉。我们只需要设置阈值,然后计算每一棵子树的c来判断是否能够剪枝即可。
代码实现
我们之前已经实现过了C4.5算法,再来实现CART可以说是非常简单了,因为它相比于C4.5还少了离散类型这种情况,可以全部当做是连续型类型来处理。
我们只需要把之前的信息增益比改成Gini指数即可:
from collections import Counter
def gini_index(dataset):
dataset = np.array(dataset)
n = dataset.shape[0]
if n == 0:
return 0
# sigma p(1-p) = 1 - sigma p^2
counter = Counter(dataset[:, -1])
ret = 1.0
for k, v in counter.items():
ret -= (v / n) ** 2
return ret
def split_gini(dataset, idx, threshold):
left, right = [], []
n = dataset.shape[0]
# 根据阈值拆分,拆分之后计算新的Gini指数
for data in dataset:
if data[idx] < threshold:
left.append(data)
else:
right.append(data)
left, right = np.array(left), np.array(right)
# 拆分成两半之后,乘上所占的比例
return left.shape[0] / n * gini_index(left) + right.shape[0] / n * gini_index(right)
然后选择拆分的函数稍微调整一下,因为Gini指数越小越好,之前的信息增益和信息增益比都是越大越好。代码的框架基本上也没有变动,只是做了一些微调:
def choose_feature_to_split(dataset):
n = len(dataset[0])-1
m = len(dataset)
# 记录最佳Gini,特征和阈值
bestGini = 1.0
feature = -1
thred = None
for i in range(n):
threds = get_thresholds(dataset, i)
for t in threds:
# 遍历所有的阈值,计算每个阈值的信息增益比
ratio = split_gini(dataset, i, t)
if ratio < bestGini:
bestGini, feature, thred = ratio, i, t
return feature, thred
建树和预测的部分都和之前C4.5算法基本一致,只需要去掉离散类型的判断即可,大家可以参考一下之前文章当中的代码。
总结
到这里,我们关于决策树模型的内容就算是结束了,我们从基本的决策树原理,再到ID3、C4.5以及CART算法,都已经囊括了。这些知识储备足以应对面试当中关于决策树模型的问题了。
虽然在实际的生产过程当中,我们已经用不到决策树了,还不是基本用不到,几乎是完全用不到。但是它的思想非常重要,是后续很多模型的基础,比如随机森林、GBDT等模型,都是在决策树的基础上建立起来的。所以我们深入理解决策树的原理对于我们后续的进阶学习非常重要。
最后, 我把完整的代码发在了paste.ubuntu上,需要的同学可以在公众号后台回复“决策树”获取。
如果喜欢本文,可以的话,请点个关注,给我一点鼓励,也方便获取更多文章。
机器学习——十大数据挖掘之一的决策树CART算法的更多相关文章
- 机器学习十大算法之KNN(K最近邻,k-NearestNeighbor)算法
机器学习十大算法之KNN算法 前段时间一直在搞tkinter,机器学习荒废了一阵子.如今想重新写一个,发现遇到不少问题,不过最终还是解决了.希望与大家共同进步. 闲话少说,进入正题. KNN算法也称最 ...
- 机器学习十大算法 之 kNN(一)
机器学习十大算法 之 kNN(一) 最近在学习机器学习领域的十大经典算法,先从kNN开始吧. 简介 kNN是一种有监督学习方法,它的思想很简单,对于一个未分类的样本来说,通过距离它最近的k个" ...
- 02-23 决策树CART算法
目录 决策树CART算法 一.决策树CART算法学习目标 二.决策树CART算法详解 2.1 基尼指数和熵 2.2 CART算法对连续值特征的处理 2.3 CART算法对离散值特征的处理 2.4 CA ...
- 03机器学习实战之决策树CART算法
CART生成 CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支.这样的决策树等价于递归地二分每个特征,将输入空间即特征空间划分为有 ...
- 【机器学习实战 第九章】树回归 CART算法的原理与实现 - python3
本文来自<机器学习实战>(Peter Harrington)第九章"树回归"部分,代码使用python3.5,并在jupyter notebook环境中测试通过,推荐c ...
- 决策树-Cart算法二
本文结构: CART算法有两步 回归树的生成 分类树的生成 剪枝 CART - Classification and Regression Trees 分类与回归树,是二叉树,可以用于分类,也可以用于 ...
- 机器学习十大算法总览(含Python3.X和R语言代码)
引言 一监督学习 二无监督学习 三强化学习 四通用机器学习算法列表 线性回归Linear Regression 逻辑回归Logistic Regression 决策树Decision Tree 支持向 ...
- 李航统计学习方法(第二版)(十):决策树CART算法
1 简介 1.1 介绍 1.2 生成步骤 CART树算法由以下两步组成:(1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;(2)决策树剪枝:用验证数据集对己生成的树进行剪枝并选择最优子 ...
- GJM : 数据结构 - 轻松看懂机器学习十大常用算法 [转载]
转载请联系原文作者 需要获得授权,非法转载 原文作者将享受侵权诉讼 文/不会停的蜗牛(简书作者)原文链接:http://www.jianshu.com/p/55a67c12d3e9 通过本篇文章可以 ...
随机推荐
- 神奇的'license': 'AGPL 3.0'标签报错
在__minifest__.py中,放了license标签,然后整个模块就报错了. 注释掉这个标签就好了.
- HttpPoolUtils 连接池管理的GET POST请求
package com.nextjoy.projects.usercenter.util.http; import org.apache.http.Consts; import org.apache. ...
- 数据结构----二叉树Tree和排序二叉树
二叉树 节点定义 class Node(object): def __init__(self, item): self.item = item self.left = None self.right ...
- 从无到有Springboot整合Spring-data-jpa实现简单应用
本文介绍Springboot整合Spring-data-jpa实现简单应用 Spring-data-jpa是什么?这不由得我们思考一番,其实通俗来说Spring-data-jpa默认使用hiberna ...
- 201771010128王玉兰《面向对象程序设计(Java)》第十六周学习总结
第一部分:理论基础 1.线程的概念 进程:进程是程序的一次动态执行,它对应了从代码加 载.执行至执行完毕的一个完整过程. 多线程:多线程是进程执行过程中产生的多条执行线索. 线程:线程是比进程执行 ...
- eclipse——Error exists in required project Proceed with launch?
运行java文件时报错: Error exists in required project Proceed with launch? 报错截图: 问题参生原因:开始Buildpath了一个jar ...
- 解决mysql:ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO/YES)
一.问题 有时候我们登录Mysql输入密码的时候,会出现这种情况 mysql -u root -p Enter Password > '密码' 错误:ERROR 1045 (28000): Ac ...
- unicode 的中文字符串,调用 isalnum()返回的是 True ?
描述 Python isalnum() 方法检测字符串是否由字母和数字组成. 语法 isalnum()方法语法: str.isalnum() 返回值 如果 string 至少有一个字符并且所有字符都是 ...
- [Objective-C] 012_数据持久化_XML属性列表,NSUserDefaults
在日常开发中经常要对NSString.NSDictionary.NSArray.NSData.NSNumber这些基本类的数据进行持久化,我们可以用XML属性列表持久化到.plist 文件中,也可以用 ...
- 使用Burpsuite对手机抓包的配置
之前使用dSploit的时候就一直在想怎么对手机进行抓包分析,前两天使用了Burpsuite神器,发现通过简单的配置就可以抓手机app的数据包了,进而分析手机app的流量. 配置环境: 1.win7下 ...