# 爬虫连载系列(1)--爬取猫眼电影Top100
前言
学习python有一段时间了,之前一直忙于学习数据分析,耽搁了原本计划的博客更新。趁着这段空闲时间,打算开始更新一个爬虫系列。内容大致包括:使用正则表达式、xpath、BeautifulSoup、Pyquery等几个爬虫解析库来爬取一些常见的网站。就当作是对自己这一段时间的学习成果的一个检验。好了,废话不多说,开始进入今天的正题。今天打算的是爬取猫眼电影的Top100榜单。
工具:jupyter notebook
使用的库:requests、re
准备抓取的内容:电影标题、主演、上映时间、评分、
思路分析:
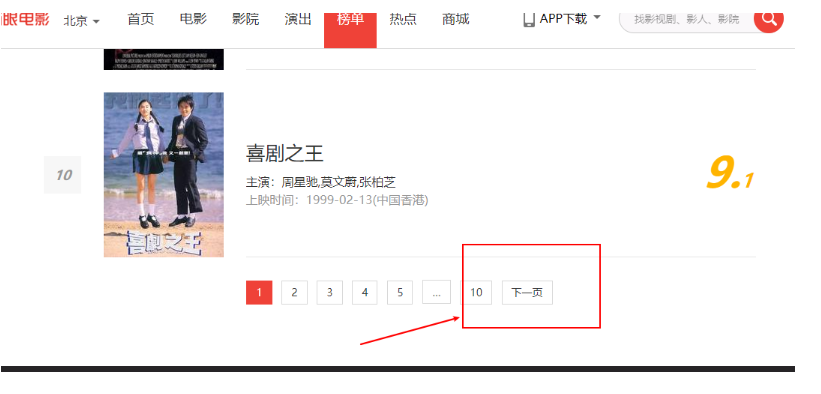
打开猫眼电影官网,找到TOP100榜单,发现有分页结构
按F12,调出开发者工具,选择Network,刷新
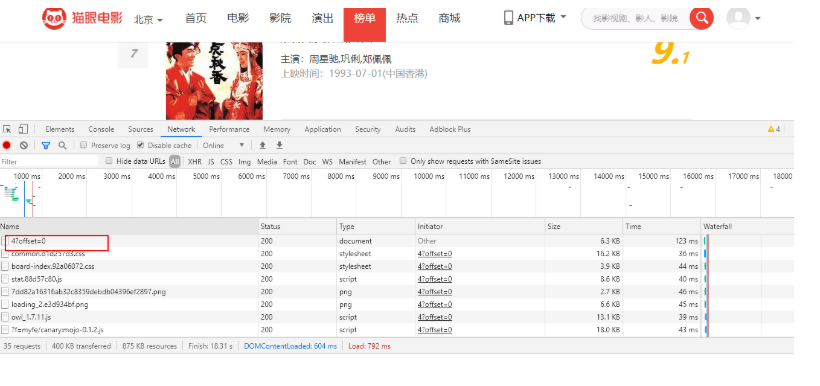
注意红框部分,我们再看下第二页的输出
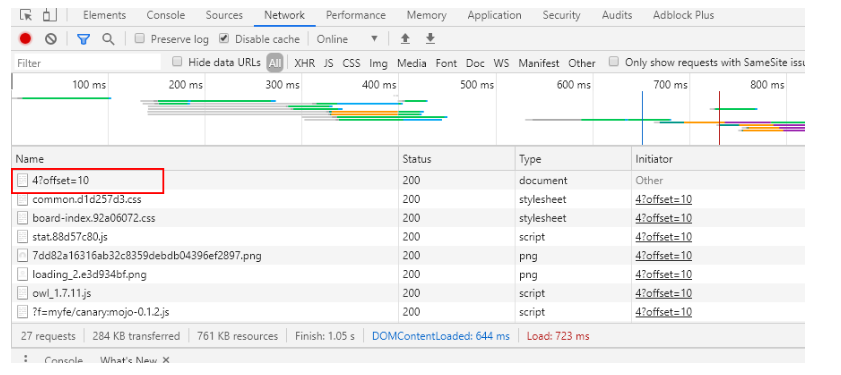
再细看一下内容,发现一页中刚好是10个电影,由此可以确定offset即是对应的每页电影数,这个也正是我们要找的东西。点进去看
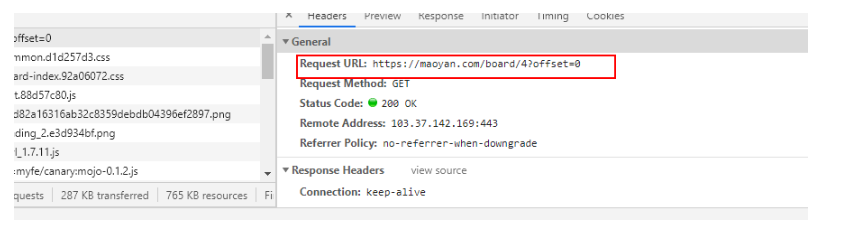
我们发现,在Response中,搜索第一个电影名字 霸王别姬,可以找到,说明这个不是动态获取的,可以直接使用,上面那个url就是我们想要获取的链接
接下来我们来看一下网页的结构,在 霸王别姬 标题上右键,检查
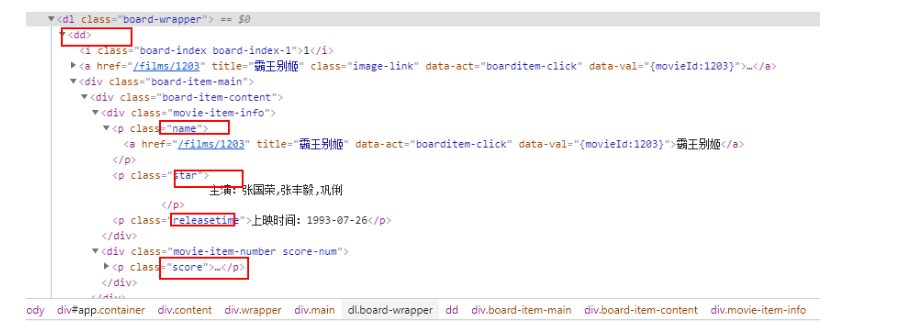
可以看出每一个 dd 标签 里面就是一个电影的信息,打开 dd 标签,发现我们要爬取的信息就在里面
开始写代码
接下来就是写代码的事了,代码比较简单,大概就60行左右,在爬取的过程中,为了模拟正常访问,设置成爬取一次休眠0.2s。直接上代码吧:
import requests
import re
import time
import csv
'''
获取页面
depth:爬取深度
'''
def get_page(depth):
base_url = 'https://maoyan.com/board/4?offset={}'
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36',
"Accept-Language": 'zh-CN,zh;q=0.9'
}
for page_num in range(depth):
start_url = base_url.format(10*page_num)
response = requests.get(url=start_url,headers=headers)
#print(response.content.decode('utf-8'))
items = parse_html(response.content.decode('utf-8'))
for item in items: #遍历迭代器
write_csv(item)
time.sleep(0.2)
#解析数据
def parse_html(html):
#使用正则表达式解析数据
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>'+
'.*?name">.*?>(.*?)</a>'+'.*?star">[\s]*(.*?)[\s]*</p>.*?releasetime">(.*?)</p>'+
'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S)
#print(re.findall(pattern,html))
#对数据进行处理
for one_list in re.findall(pattern,html):
yield{
'index':one_list[0],
'name':one_list[1],
'actor':one_list[2].split(':')[1], #注意: 此处为中问 :
'releasetime':one_list[3].split(':')[1].split('(')[0],
'country':get_erea(one_list[3]),
'score':one_list[4] + one_list[5]
}
#获取国家
def get_erea(data):
pattern = re.compile('.*\((.*?)\)')
country = pattern.search(data)
if country is None:
return "未知"
else:
return country.group(1) #group(1) 获取第一个括号 匹配的内容
#写入到csv文件中
def write_csv(item):
fieldnames = ['index','name','actor','releasetime','country','score'] #定义表头字段,标识写入顺序
with open('./MoviesTop100.csv','a',newline='',encoding= 'utf-8-sig') as f:
writer = csv.DictWriter(f,fieldnames=fieldnames) #以字典方式写入
writer.writerow(item)
def main():
get_page(11) #共爬取10页,即100条数据
if __name__ == "__main__":
main()
结果
接下来我们看一下我们爬取的效果吧
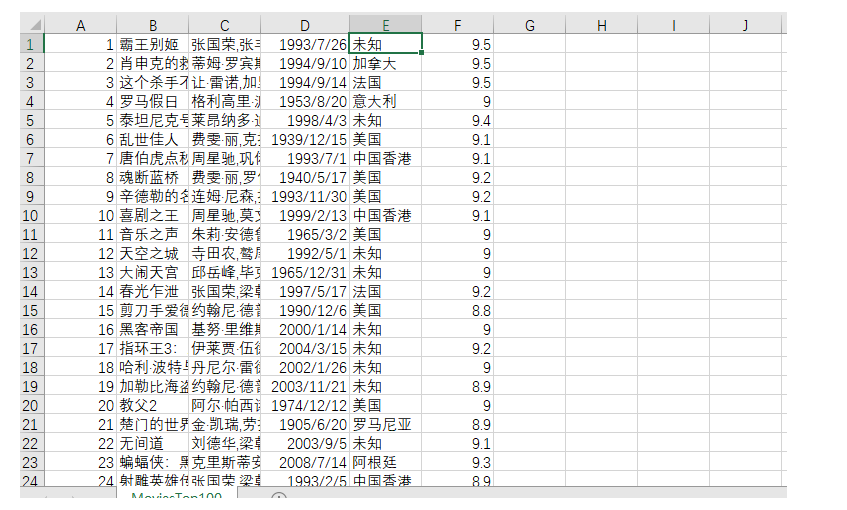
后面,打算用今天爬取的这个数据进行一下分析
# 爬虫连载系列(1)--爬取猫眼电影Top100的更多相关文章
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 爬虫练习之正则表达式爬取猫眼电影Top100
#猫眼电影Top100import requests,re,timedef get_one_page(url): headers={ 'User-Agent':'Mozilla/5.0 (Window ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 一起学爬虫——使用xpath库爬取猫眼电影国内票房榜
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜 XPATH语法 XPATH(XML Path Language)是一门用于从XML文件中 ...
随机推荐
- struts-dojo的使用
1.导入struts2-dojo-plugin-2.1.8.jar 2.在用使用dojo的页面引入 <span style="font-size:14px;">< ...
- redHat更新yum源
1. 网易镜像仓库查找相关rpm 包并下载 :http://mirrors.163.com/centos/6/os/x86_64/Packages/ wget http://mirrors.163.c ...
- mysql挖掘与探索--表操作命令 1
1.登录数据库>mysql -u root -p 数据库名称 2.查询所有数据表>show tables; 3.查询表的字段信息>desc 表名称; 4.1添加表字段 alter t ...
- 经典题型-打印小星星(python)
# * # * * # * * * # * * * * # * * * * * x = 0 while x < 5: x += 1 # 每次循环需要给y赋值0.清空y中存储的值 y = 0 wh ...
- POJ 2553 The Bottom of a Graph Tarjan找环缩点(题解解释输入)
Description We will use the following (standard) definitions from graph theory. Let V be a nonempty ...
- Java中的字符串比较
在C++中,两个字符串比较的代码可以为: (string1==string2) 但是在java中,这个代码即使在两个字符串完全相同的情况下也会返回 false ,Java中必须使用 string1.e ...
- Solr7.3.0入门教程,部署Solr到Tomcat,配置Solr中文分词器
solr 基本介绍 Apache Solr (读音: SOLer) 是一个开源的搜索服务器.Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现.Apache ...
- Linux中的一些点
前言 本文记录一些日常使用linux的一些点. 系统负载评估 理解Linux系统负荷 查看 ps -ef [root@deployer ~]# ps -ef UID PID PPID C STIME ...
- 复合文字(Compound Literals)
复合文字(Compound Literals) 阅读代码时发现了这行 1 setsockopt(sock,SOL_SOCKET,SO_REUSEADDR,&(int){1},sizeof(in ...
- Python-控制语句及函数
if-elif-else for while 函数 函数定义 空函数 pass 返回多个值 可变参数 * 关键字参数 ** 控制语句 if - elif - else 比如,输入用户年龄,根据年龄打印 ...