### MySQL主从搭建Position
一、MySQL主从搭建
搭建主从架构的MySQL常用的有两种实现方式:
- 基于binlog的fileName + postion模式完成主从同步。
- 基于gtid完成主从同步搭建。
本篇就介绍如何使用第一种方式完成MySQL主从环境的搭建。
基于fileName和position去实现主从复制,所谓的fileName就是bin-log的name,position指的是slave需要从master的binlog的哪个位置开始同步数据。
这种模式同步数据方式麻烦的地方就是需要我们自己通过如下的命令去查找应该从哪个bin-log的哪个position去开始同步。
二、主库
2.1、确定主库的binlog是否开启
命令:show variables like 'bin-log'
原因:了解MySQL中常见的三个日志:
- 单机MySQL的undolog日志中记录着如何将现有的数据恢复成被修改前的旧数据。
- 单机MySQL的redolog. 中记录事物日志。
- 主从模式的MySQL通过bin-log日志同步数据。
2.2、骚气的命令
grant replication slave on *.* to MySQLsync@"127.0.0.1" identified by "MySQLsync123";
这条命令是在干什么呢?
捋一下思路:我们做主从同步,在主库这边我们其实会单独创建一个账号用于实现主从同步。下面的命令其实就会帮我们创建出 username=mysqlsync password=mysqlsync123的账户专门用户主从同步使用。
执行完上面的命令后,执行如下的命令查看上面的grant执行结果:
select user, host from mysql.user like '%mysqlsync%'
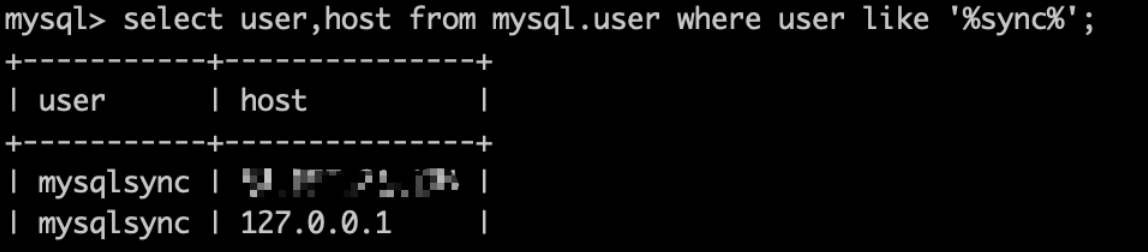
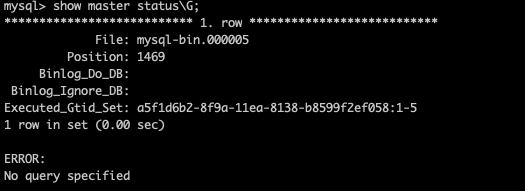
2.3、记录主库的master状态
注意主库的查看主库当前是第几个binlog,已经数据的position。
因为一会从库就是根据这两个信息知道自己该从主库的第几个binlog的什么positon开始同步。
三、从库
3.1、从库和主库保持同步
从库执行change语句,和主库保持同步
CHANGE MASTER TO
MASTER_HOST='10.157.23.158',
MASTER_USER='mysqlsync',
MASTER_PASSWORD='mysqlsync123',
MASTER_PORT=8882,
MASTER_LOG_FILE='mysql-bin.000008',
MASTER_LOG_POS=1013;
CHANGE MASTER TO
MASTER_HOST = '${new_master_ip}',
MASTER_USER = '${user}',
MASTER_PASSWORD = '${password}',
MASTER_PORT = ${new_master_port},
master_auto_position = 1;
CHANGE MASTER TO
MASTER_HOST = '10.157.23.123',
MASTER_USER = 'mysqlsync',
MASTER_PASSWORD = 'mysqlsync123',
MASTER_PORT = 8882,
master_auto_position = 1;
3.2、开启主从同步
start slave
show slave status \G
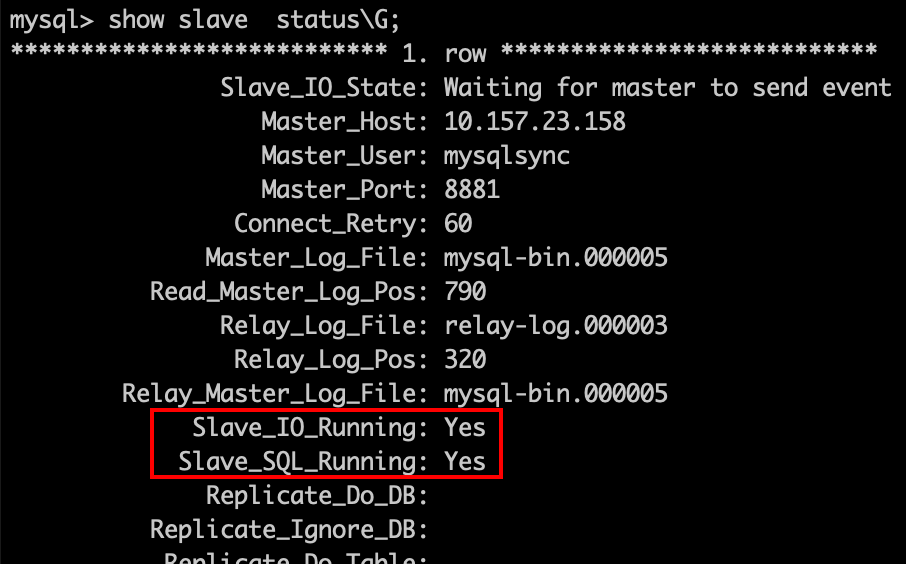
当我们可以看到 io线程和sql线程的状态都是yes时,说明此刻主从同步已经搭建完成了。
3.3、从库:如何断开主从
stop slave io_thread
stop slave sql_thread
3.4、主库:如何断开主从
把用于进行主从同步的账号删除就好了
drop user ${user}@${slave_ip}
四、中断处理
中断处理部分说的是,一开始我们搭建主从很可能并不是一番风顺的,就比如上面的Slave_IO_Running和Slave_SQL_Running很可能处于NO的状态。下面介绍一下常见的解决方式。
4.1、Slave_IO_Running异常
Slave_IO_Running:no/connecting
这说明从库连接不上主库,或者是一直处于正在连接的状态。
可能是主库没有对从库进行授权,如果已经授权了那么重启一下salve。
另一种原因就是master和slave的mysqld相关配置文件中,配置了相同server_id。
还有可能你在执行change master命令时,输入的主库相关的信息本来就是错误的。
4.2、Slave_Sql_Running异常
Slave_Sql_Running:no
一般这种情况是bin-log中的sql出问题了。
第一种情况:可能我们配置了slave只能读,但是却有写请求打过来了,导致slave不能继续往下执行。
第二种解决思路:让slave跳过有问题的这个事件,但是还是得把事件的原因查明白,不然不推荐直接跳过这个事件。
stop slave;
set global sql_slave_skip_counter=1;
start slave;
第三种思路:我们提前配置好错误号机制,当slave在同步的过程中,碰到我们配置的错误号采取自动跳过的机会而不再去默认的终止同步数据。
# 一般我们可以像下面这样,在my.cnf中的[MySQLd]的启动参数中添加如下内容
--slave-skip-errors=1062,1053
--slave-skip-errors=all
--slave-skip-errors=ddl_exist_errors
# 通过如下语句查看当前MySQL配置的变量
MySQL> show variables like 'slave_skip%';
# 通过如下命令可以查看到出现的errorno
show slave status; # 观察Last_Errno
# 常见的errorno
1007:数据库已存在,创建数据库失败
1008:数据库不存在,删除数据库失败
1050:数据表已存在,创建数据表失败
1051:数据表不存在,删除数据表失败
1054:字段不存在,或程序文件跟数据库有冲突
1060:字段重复,导致无法插入
1061:重复键名
1068:定义了多个主键
1094:位置线程ID
1146:数据表缺失,请恢复数据库
1053:复制过程中主服务器宕机
1062:主键冲突 Duplicate entry '%s' for key %d
第四种思路:手动给slave调整fileName和position的位置(如何允许放弃之前的一部分数据,而从当前最新的数据开始同步)
# 停掉slave
slave stop
# 进入master
# 停止master的写操作
# 查看master中当前bin-log和position
show master status;
# 切换回slave从新根据最新的position和bin-log进行同步
# 进入master,开启master的写操作
五、流程
通过fileName和position完成定位,从库会向主库发送命令,BINLOG_DUMP ,命令中包含有positon和fileName, 主库获取到这些信息之后,指定name到指定position往从库发送bin-log
六、可能会遇到的问题
6.1、问题一:
change master时报错了

报错说:ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
原因是我之前使用过gtid进行同步数据,当时将master_auto_position设置成了1,再想使用手动指定position的主从同步方式需要得像下面这样,change回去。
CHANGE MASTER TO
MASTER_AUTO_POSITION=0;
6.2、问题二:
如果我随便写了个position再搭建主从时,会发生什么?
下面的 MASTER_LOG_POS = 1003 就是我随便写的一个position,然后你可以看到两个现象
- Slave_IO_Running : No
- Last_IO_Error 位置报了个严重的错误
mysql> CHANGE MASTER TO
-> MASTER_HOST='10.157.23.xxx',
-> MASTER_USER='mysqlsync',
-> MASTER_PASSWORD='mysqlsync123',
-> MASTER_PORT=8882,
-> MASTER_LOG_FILE='mysql-bin.000008',
-> MASTER_LOG_POS=1003;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 10.157.23.158
Master_User: mysqlsync
Master_Port: 8882
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 1003
Relay_Log_File: relay-log.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table: mysql.%,test.%
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1003
Relay_Log_Space: 521
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'log event entry exceeded max_allowed_packet; Increase max_allowed_packet on master; the first event 'mysql-bin.000008' at 1003, the last event read from './mysql-bin.000008' at 123, the last byte read from './mysql-bin.000008' at 1022.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 2787871625
Master_UUID: a5f1d6b2-8f9a-11ea-8138-b8599f2ef058
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 200529 10:22:46
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 00c755a6-7a07-11ea-8701-b8599f2ef058:33-222,
40efcb1b-7a1f-11ea-84ac-b8599f229b38:1-20,
7e2dcb21-7d3b-11ea-aa0c-b8599f2ef058:1-18,
9e6027f2-7ae9-11ea-ac13-b8599f2ef058:1409-7176,
a5f1d6b2-8f9a-11ea-8138-b8599f2ef058:6-9:12-13:15,
e90fdd54-7e04-11ea-8b23-b8599f2ef058:1-11
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
6.3、问题三:
假设我们有这样的场景:
场景:现在主库有7条数据,从库有5条数据,搭建主从时如何让从库从第六条开始同步?
这种情况仅仅是我们在做这种小实验,为啥这样说呢?如果是为线上的业务搭建搭建主从MySQL的话,大概率我们会清空主库然后再做同步。如果数据很重要,我们会对主库中的数据进行一次全量拷贝到从库(拷贝var包)。再做主从同步。
在线上的环境中,主从的数据是会强一致的,从库只会接受业务方的读流量,也许网络环境很恶劣从库同步的速度明显比主库写入到速度低,但是只要从库没有说跳过了某个binlog而少同步了某条记录,我们都可以认为它们是正常的主从同步。不会出现主从中断的情况。
线上的环境中什么情况下会出现主从中断呢?比如说,从库同步数据时,从库同步binlog时丢了一条数据,这时业务上突然来了条update语句,要更新数据,然后从库美滋滋的回放在主库dump过来的binlog时发现,竟然自己没有需要更新的这条记录,就会报错,这时为了业务止损,我们要在第一时间下线从库,然后去分析哪里出现问题了。
针对这个实验我们这样去binlog中查看第5,6条数据的position,然后在从库中使用相应的position完成主从数据的同步。
进入主库,通过下面的命令查看binlog
mysqlbinlog --no-defaults -vv --base64-output=decode-rows ../var/mysql-bin.000008 | less
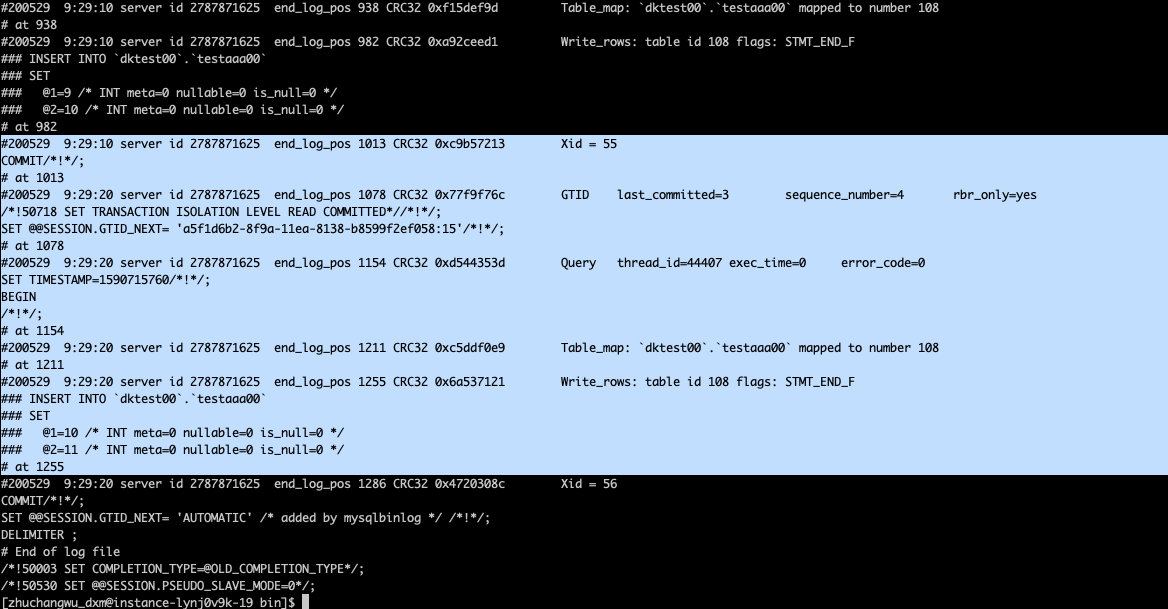
找到了指定的binlog和指定的end_log_pos
比如从库中没有第10,11条数据,我们就能通过end_log_pos = postion = 1013完成定位。
CHANGE MASTER TO
MASTER_HOST='10.157.23.158',
MASTER_USER='mysqlsync',
MASTER_PASSWORD='mysqlsync123',
MASTER_PORT=8882,
MASTER_LOG_FILE='mysql-bin.000008',
MASTER_LOG_POS=1013;
开启同步,并查看状态
start slave;
show slave status\G;
再去查看从库就能发现,从你指定的position开始往后和主库的数据保持同步的。
6.4、问题四:
问:主从接流量的情况是怎样的?业务的CRUD请求是如何被主从平分消费的?
答:默认这种架构下是读写分离,也就是说,仅读流量会打到从库中
问:那如果我们在从库所在的机器上本地登陆,然后手动执行删除的操作能成功吗?
答:是的,可以执行成功。
问:我可以简单粗暴的限制从库仅读吗?
答:可以的,像下面这样
mysql> show variables like '%read_only%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_read_only | OFF |
| read_only | OFF |
| super_read_only | OFF |
| transaction_read_only | OFF |
| tx_read_only | OFF |
+-----------------------+-------+
5 rows in set (0.00 sec)
set global read_only=0; #关闭只读,可以读写
set global read_only=1; #开始只读模式
6.5、问题五:
假设主库中有1~7 共7条数据,从库中有1~5五条数据。也就是说,主库从库中前五条数据一样,但是主库比从库多了两条新数据。
这时我们搭建主从同步时搞一搞事情,重复这个动作:在从库断开同步,然后查到主库第一个binlog中的数据的记录,确定我们要查找的position,再重新构建主从环境。观察一下从库这边数据的同步情况,以及会出现什么问题?从库这边的数据会成为double吗?
答:数据不会double的
6.6、问题六:
假设从库执行changemaster时,主库MASTER_HOST填错了:
在查看slave 状态时,我们可以看到Last_IO_Error列有报错提示: error connecting to master
mysql> CHANGE MASTER TO
-> MASTER_HOST='10.157.23.158',
-> MASTER_USER='mysqlsync',
-> MASTER_PASSWORD='mysqlsync123',
-> MASTER_PORT=8882,
-> MASTER_LOG_FILE='mysql-bin.000008',
-> MASTER_LOG_POS=1013;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Connecting to master
Master_Host: 10.157.23.123
Master_User: mysqlsync
Master_Port: 8882
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 1003
Relay_Log_File: relay-log.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table: mysql.%,test.%
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1003
Relay_Log_Space: 154
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 2003
Last_IO_Error: error connecting to master 'mysqlsync@10.157.23.123:8882' - retry-time: 60 retries: 1
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 0
Master_UUID:
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 200529 10:13:34
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 00c755a6-7a07-11ea-8701-b8599f2ef058:33-222,
40efcb1b-7a1f-11ea-84ac-b8599f229b38:1-20,
7e2dcb21-7d3b-11ea-aa0c-b8599f2ef058:1-18,
9e6027f2-7ae9-11ea-ac13-b8599f2ef058:1409-7176,
a5f1d6b2-8f9a-11ea-8138-b8599f2ef058:6-9:12-13:15,
e90fdd54-7e04-11ea-8b23-b8599f2ef058:1-11
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
6.7、问题七:
假设这种场景:假设主从现在的数据是一致的,然后你在从库所在的机器上本地登陆,然后手动删除一条,再从主库写入数据,那从库还能同步成功吗?
答:从库依然会同步成功,但是其实这时候已经算是事故了,主从数据不一致,万一业务打来一条sql刚好使用你删的数据,那就会报错。
如果觉得对你有帮助欢迎关注我,后面还会分享通过gtid搭建主从mysql以及其他相关的知识点
### MySQL主从搭建Position的更多相关文章
- mysql 主从搭建步骤
mysql 主从搭建步骤 1:主库开启master端bin-log 2:主库创建备份用户 3:主库全备 4:从库导入全备数据 5:从库修改change master to信息 6:从库slave st ...
- SQL Server、MySQL主从搭建,EF Core读写分离代码实现
一.SQL Server的主从复制搭建 1.1.SQL Server主从复制结构图 SQL Server的主从通过发布订阅来实现 1.2.基于SQL Server2016实现主从 新建一个主库&quo ...
- MySQL主从搭建
主服务器配置 1.编辑配置文件 # 如果不存在,就手动创建一个 vim /etc/my.cnf 在配置文件加入如下值: [mysqld] # 唯一的服务辨识号,数值位于 1 到 2^32-1之间. # ...
- MySql主从搭建详细步骤
环境: linux64位,一台机器两个实例,主库3306端口,从库3307端口 步骤: 一.下载安装 先下载安装mysql,这里使用了5.7.21版本,具体过程不做详细说明,可自行查资料如何下载 二. ...
- mysql主从搭建之诡异事件
今天在搭建主从后出现了主库system账号丢失INSERT权限的情况,记录如下 主库: system账号权限同root权限,并且mysql库已经删除 从库: mysql库存在,无system账号 主从 ...
- MariaDB(Mysql)-主从搭建
卸载过程: 停止服务:systemctl stop mariadb 查询安装包:rpm -qa | grep mariadb 卸载: rpm -e mariadb-server rpm -e mari ...
- mysql主从搭建操作
1.搭建说明准备工作:主从库已安装mysql软件以及xtracbackup备份工具.具体操作可参见mysql rpm安装文档. 介质 版本操作系统 Red Hat Enterprise Linux S ...
- mysql 主从搭建
主要搭建步骤如下: 1.打开binlog,设置server_id 打开主库的--log-bin,并设置server_id 2.主库授权 --最好也在从库对主库授权 ...
- mysql之 MySQL 主从基于position复制原理概述
1 .主从复制简介MySQL 主从复制就是将一个 MySQL 实例(Master)中的数据实时复制到另一个 MySQL 实例(slave)中,而且这个复制是一个异步复制的过程.实现整个复制操作主要由三 ...
随机推荐
- Docker 快速安装Jenkins完美教程 (亲测采坑后详细步骤)
一.前言 有人问,为什么要用Jenkins,在一些中小型企业?我说下我以前开发的痛点,每次开发一个项目完成后,需要打包部署,可能没有专门的运维人员,只能开发人员去把项目打成一个war包,可能这个项目已 ...
- .NET Core技术研究-通过Roslyn代码分析技术规范提升代码质量
随着团队越来越多,越来越大,需求更迭越来越快,每天提交的代码变更由原先的2位数,暴涨到3位数,每天几百次代码Check In,补丁提交,大量的代码审查消耗了大量的资源投入. 如何确保提交代码的质量和提 ...
- bootstrap栅格系统的使用
bootstrap栅格系统的使用 bootstrap栅格系统的使用,主要分为四种方式 1.列组合 col-md-* 2.列偏移 col-md-offset-* 3.列嵌套 大列组合包含着小组合 4 ...
- 安卓集成Unity开发示例(一)
本项目目的是在移动端的 Native App 中以库的形式集成已经写好的 Unity 工程,利用 Unity 游戏引擎便捷的开发手段进行跨平台开发. Unity官方文档 Unity as a Libr ...
- HMM-前向后向算法
基本要素 状态 \(N\)个 状态序列 \(S = s_1,s_2,...\) 观测序列 \(O=O_1,O_2,...\) \(\lambda(A,B,\pi)\) 状态转移概率 \(A = \{a ...
- LabVIEW动态添加控件
综述: 事例1: 未执行: 执行后:
- Windows 10 IoT Core用PWM控制器控制树莓派LED灯亮度
我接到一个需求,需要调节LED灯的亮度,且是从上位机进行控制,我了解到树莓派也有PWM,就准备通过PWM来控制灯的亮度. PWM又叫脉宽调制,是用微处理器的数字输出来对模拟电路进行控制,对模拟信号电平 ...
- flink批处理从0到1学习
一.DataSet API之Data Sources(消费者之数据源) 介绍: flink提供了大量的已经实现好的source方法,你也可以自定义source 通过实现sourceFunction接口 ...
- etcd实现服务发现
前言 etcd环境安装与使用文章中介绍了etcd的安装及v3 API使用,本篇将介绍如何使用etcd实现服务发现功能. 服务发现介绍 服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式 ...
- SpringBoot基础实战系列(二)springboot解析json与HttpMessageConverter
SpringBoot解析Json格式数据 @ResponseBody 注:该注解表示前端请求后端controller,后端响应请求返回 json 格式数据前端,实质就是将java对象序列化 1.创建C ...