数据源管理 | OLAP查询引擎,ClickHouse集群化管理
本文源码:GitHub·点这里 || GitEE·点这里
一、列式库简介
ClickHouse是俄罗斯的Yandex公司于2016年开源的列式存储数据库(DBMS),主要用于OLAP在线分析处理查询,能够使用SQL查询实时生成分析数据报告。
列式存储
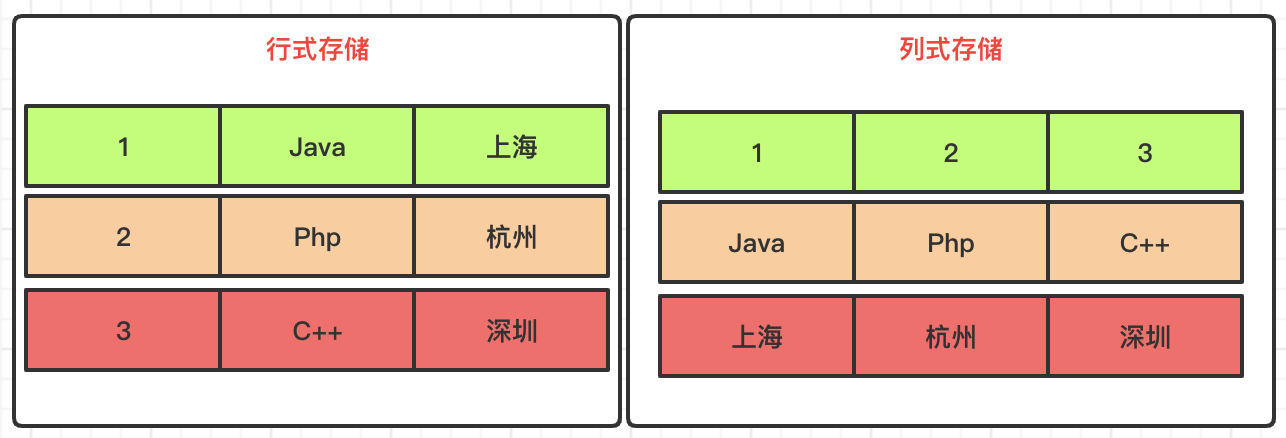
行式存储和列式存储,数据在磁盘上的组织结构有着根本不同,数据分析计算时,行式存储需要遍历整表,列式存储只需要遍历单个列,所以列式库更适合做大宽表,用来做数据分析计算。
絮叨一句:注意这里比较的场景,是数据分析计算的场景。
二、集群配置
1、基础环境
ClickHouse单服务默认已经安装完毕
2、取消文件限制
vim /etc/security/limits.conf
vim /etc/security/limits.d/90-nproc.conf
文件末尾追加
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
3、取消SELINUX
修改/etc/selinux/config中的SELINUX=disabled后重启
4、集群配置文件
服务分别添加集群配置:vim /etc/metrika.xml
<yandex>
<clickhouse_remote_servers>
<clickhouse_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.72.133</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>192.168.72.136</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.72.137</host>
<port>9000</port>
</replica>
</shard>
</clickhouse_cluster>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.72.133</host>
<port>2181</port>
</node>
<node index="2">
<host>192.168.72.136</host>
<port>2181</port>
</node>
<node index="3">
<host>192.168.72.137</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<replica>192.168.72.133</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
注意这里
<macros>
<replica>192.168.72.133</replica>
</macros>
配置各自服务的IP地址。
5、启动集群
分别启动三台服务
service clickhouse-server start
6、登录客户端查看
这里登录任意一台服务就好
clickhouse-client
en-master :) select * from system.clusters
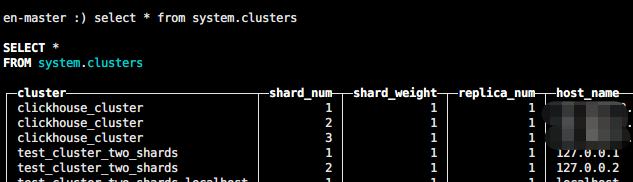
这里这里集群名称:clickhouse_cluster,后续使用。
7、基本环境测试
三台服务上同时创建表结构。
CREATE TABLE ontime_local (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
133环境创建分布表
CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(clickhouse_cluster, default, ontime_local, rand());
随便写入一台服务数据
insert into ontime_local (FlightDate,Year) values ('2020-03-12',2020);
查询总表
select * from ontime_all;
写入总表,数据会分布到各个单表中
insert into ontime_all (FlightDate,Year)values('2001-10-12',2001);
insert into ontime_all (FlightDate,Year)values('2002-10-12',2002);
insert into ontime_all (FlightDate,Year)values('2003-10-12',2003);
任意关闭一台服务,集群查询直接挂掉
三、集群环境整合
1、基础配置
url:配置全部的服务列表,主要用来管理表结构,批量处理;
cluster:集群连接服务,可以基于Nginx代理服务配置;
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
click:
driverClassName: ru.yandex.clickhouse.ClickHouseDriver
url: jdbc:clickhouse://127.0.0.1:8123/default,jdbc:clickhouse://127.0.0.1:8123/default,jdbc:clickhouse://127.0.0.1:8123/default
cluster: jdbc:clickhouse://127.0.0.1:8123/default
initialSize: 10
maxActive: 100
minIdle: 10
maxWait: 6000
2、管理接口
分别向每个单节点服务创建表和写入数据:
data_shard(单节点数据)
data_all(分布数据)
@RestController
public class DataShardWeb {
@Resource
private JdbcFactory jdbcFactory ;
/**
* 基础表结构创建
*/
@GetMapping("/createTable")
public String createTable (){
List<JdbcTemplate> jdbcTemplateList = jdbcFactory.getJdbcList();
for (JdbcTemplate jdbcTemplate:jdbcTemplateList){
jdbcTemplate.execute("CREATE TABLE data_shard (FlightDate Date,Year UInt16) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192)");
jdbcTemplate.execute("CREATE TABLE data_all AS data_shard ENGINE = Distributed(clickhouse_cluster, default, data_shard, rand())");
}
return "success" ;
}
/**
* 节点表写入数据
*/
@GetMapping("/insertData")
public String insertData (){
List<JdbcTemplate> jdbcTemplateList = jdbcFactory.getJdbcList();
for (JdbcTemplate jdbcTemplate:jdbcTemplateList){
jdbcTemplate.execute("insert into data_shard (FlightDate,Year) values ('2020-04-12',2020)");
}
return "success" ;
}
}
3、集群查询
上述步骤执行完成后,可以连接集群服务查询分布总表和单表的数据。
基于Druid连接
@Configuration
public class DruidConfig {
@Resource
private JdbcParamConfig jdbcParamConfig ;
@Bean
public DataSource dataSource() {
DruidDataSource datasource = new DruidDataSource();
datasource.setUrl(jdbcParamConfig.getCluster());
datasource.setDriverClassName(jdbcParamConfig.getDriverClassName());
datasource.setInitialSize(jdbcParamConfig.getInitialSize());
datasource.setMinIdle(jdbcParamConfig.getMinIdle());
datasource.setMaxActive(jdbcParamConfig.getMaxActive());
datasource.setMaxWait(jdbcParamConfig.getMaxWait());
return datasource;
}
}
基于mapper查询
<mapper namespace="com.ckhouse.cluster.mapper.DataAllMapper">
<resultMap id="BaseResultMap" type="com.ckhouse.cluster.entity.DataAllEntity">
<result column="FlightDate" jdbcType="VARCHAR" property="flightDate" />
<result column="Year" jdbcType="INTEGER" property="year" />
</resultMap>
<select id="getList" resultMap="BaseResultMap" >
select * from data_all where Year=2020
</select>
</mapper>
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

推荐阅读:数据源管理
| 序号 | 标题 |
|---|---|
| A01 | 数据源管理:主从库动态路由,AOP模式读写分离 |
| A02 | 数据源管理:基于JDBC模式,适配和管理动态数据源 |
| A03 | 数据源管理:动态权限校验,表结构和数据迁移流程 |
| A04 | 数据源管理:关系型分库分表,列式库分布式计算 |
| A05 | 数据源管理:PostGreSQL环境整合,JSON类型应用 |
| A06 | 数据源管理:基于DataX组件,同步数据和源码分析 |
数据源管理 | OLAP查询引擎,ClickHouse集群化管理的更多相关文章
- 架构设计 | 分布式系统调度,Zookeeper集群化管理
本文源码:GitHub·点这里 || GitEE·点这里 一.框架简介 1.基础简介 Zookeeper基于观察者模式设计的组件,主要应用于分布式系统架构中的,统一命名服务.统一配置管理.统一集群管理 ...
- 数据源管理 | 搜索引擎框架,ElasticSearch集群模式
本文源码:GitHub·点这里 || GitEE·点这里 一.集群环境搭建 1.环境概览 ES版本6.3.2,集群名称esmaster,虚拟机centos7. 服务群 角色划分 说明 en-maste ...
- mtools 是由MongoDB 官方工程师实现的一套工具集,可以很快速的日志查询分析、统计功能,此外还支持本地集群部署管理.
mtools 是由MongoDB 官方工程师实现的一套工具集,可以很快速的日志查询分析.统计功能,此外还支持本地集群部署管理 https://www.cnblogs.com/littleatp/p/9 ...
- 手把手教你:将 ClickHouse 集群迁至云上
前言 随着云上 ClickHouse 服务完善,越来越多的用户将自建 ClickHouse 服务迁移至云上.对于不同数据规模,我们选择不同的方案: 对于数据量比较小的表,通常小于10GB 情况下,可以 ...
- 一文读懂clickhouse集群监控
更多精彩内容,请关注微信公众号:后端技术小屋 一文读懂clickhouse集群监控 常言道,兵马未至,粮草先行,在clickhouse上生产环境之前,我们就得制定好相关的监控方案,包括metric采集 ...
- ClickHouse(04)如何搭建ClickHouse集群
ClickHouse集群的搭建和部署和单机的部署是类似的,主要在于配置的不一致,如果需要了解ClickHouse单机的安装设部署,可以看看这篇文章,ClickHouse(03)ClickHouse怎么 ...
- XNginx - nginx 集群可视化管理工具
之前团队的nginx管理,都是运维同学每次去修改配置文件,然后重启,非常不方便,一直想找一个可以方便管理nginx集群的工具,翻遍web,未寻到可用之物,于是自己设计开发了一个. 效果预览 集群gro ...
- redis cluster集群web管理工具 relumin
redis cluster集群web管理工具 relumin 下载地址 https://github.com/be-hase/relumin 只支持redis cluster模式 java环境 tar ...
- docker swarm英文文档学习-7-在集群中管理节点
Manage nodes in a swarm在集群中管理节点 List nodes列举节点 为了查看集群中的节点列表,可以在管理节点中运行docker node ls: $ docker node ...
随机推荐
- python 进阶篇 python 的值传递
值传递和引用传递 值传递,通常就是拷贝参数的值,然后传递给函数里的新变量,这样,原变量和新变量之间互相独立,互不影响. 引用传递,通常是指把参数的引用传给新的变量,这样,原变量和新变量就会指向同一块内 ...
- Python修改paramiko模块开发运维审计保垒机
目前市面上,专门做IT审计堡垒机的厂商有很多,他们的产品都有一个特点,那就是基本上每台的售价都在20万以上.像我们做技术的,不可能每次待的公司都是大公司,那么在小公司,是不太可能投资20多万买一台硬件 ...
- Thymeleaf+SpringBoot+Mybatis实现的齐贤易游网旅游信息管理系统
项目简介 项目来源于:https://github.com/liuyongfei-1998/root 本系统是基于Thymeleaf+SpringBoot+Mybatis.是非常标准的SSM三大框架( ...
- Oracle数据库排序后分页查询数据错误问题解决
一.问题描述:根据更新时间倒序排序然后分页查询数据,但是点击分页操作的时候,会出现数据重复看似没有操作的情况 二.问题错误原因分析 分页查询的SQL语句: select * FROM (select ...
- Java 虚拟机中的运行时数据区分析
本文基于 JDK1.8 阐述分析 运行过程 我们都知道 Java 源文件通过编译器编译后,能产生相应的 .Class 文件,也就是字节码文件.而字节码文件通过 Java 虚拟机中的解释器,编译成特定机 ...
- Apache Hudi集成Apache Zeppelin实战
1. 简介 Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本.方便你做出可数据驱动的.可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spa ...
- 使用pthread进行编程
使用pthread进行并行编程 进程与线程 进程是一个运行程序的实例:线程像一个轻量级的进程:在一个共享内存系统中,一个进程可以有多个线程 POSIX® Threads: 即 Pthreads,是一个 ...
- Android 中 OkHttp 三步实现生命周期绑定
简介 OkHttps 是 OkHttp 增强版的超轻量封装包. 和 Retrofit 相比,它更加轻量(只有 59Kb),是 Retrofit (124Kb)的一半,而且更加的开箱即用,API 更加自 ...
- 使用宝塔面板部署tp5网站
来源:https://www.cnblogs.com/e0yu/p/9102902.html 遇到一个问题,就是当thinkphp5部署在宝塔面板上,会出现这个问题: 参考解决办法: http://w ...
- Spring5参考指南:基于Schema的AOP
文章目录 基于Schema的AOP 定义Aspect 定义Pointcut 定义Advice advice参数 Advisors 基于Schema的AOP 上篇文章我们讲到了使用注解的形式来使用Spr ...