python实现线性回归之简单回归
代码来源:https://github.com/eriklindernoren/ML-From-Scratch
首先定义一个基本的回归类,作为各种回归方法的基类:
class Regression(object):
""" Base regression model. Models the relationship between a scalar dependent variable y and the independent
variables X.
Parameters:
-----------
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
"""
def __init__(self, n_iterations, learning_rate):
self.n_iterations = n_iterations
self.learning_rate = learning_rate def initialize_wights(self, n_features):
""" Initialize weights randomly [-1/N, 1/N] """
limit = 1 / math.sqrt(n_features)
self.w = np.random.uniform(-limit, limit, (n_features, )) def fit(self, X, y):
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
self.training_errors = []
self.initialize_weights(n_features=X.shape[1]) # Do gradient descent for n_iterations
for i in range(self.n_iterations):
y_pred = X.dot(self.w)
# Calculate l2 loss
mse = np.mean(0.5 * (y - y_pred)**2 + self.regularization(self.w))
self.training_errors.append(mse)
# Gradient of l2 loss w.r.t w
grad_w = -(y - y_pred).dot(X) + self.regularization.grad(self.w)
# Update the weights
self.w -= self.learning_rate * grad_w def predict(self, X):
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
y_pred = X.dot(self.w)
return y_pred
说明:初始化时传入两个参数,一个是迭代次数,另一个是学习率。initialize_weights()用于初始化权重。fit()用于训练。需要注意的是,对于原始的输入X,需要将其最前面添加一项为偏置项。predict()用于输出预测值。
接下来是简单线性回归,继承上面的基类:
class LinearRegression(Regression):
"""Linear model.
Parameters:
-----------
n_iterations: float
The number of training iterations the algorithm will tune the weights for.
learning_rate: float
The step length that will be used when updating the weights.
gradient_descent: boolean
True or false depending if gradient descent should be used when training. If
false then we use batch optimization by least squares.
"""
def __init__(self, n_iterations=100, learning_rate=0.001, gradient_descent=True):
self.gradient_descent = gradient_descent
# No regularization
self.regularization = lambda x: 0
self.regularization.grad = lambda x: 0
super(LinearRegression, self).__init__(n_iterations=n_iterations,
learning_rate=learning_rate)
def fit(self, X, y):
# If not gradient descent => Least squares approximation of w
if not self.gradient_descent:
# Insert constant ones for bias weights
X = np.insert(X, 0, 1, axis=1)
# Calculate weights by least squares (using Moore-Penrose pseudoinverse)
U, S, V = np.linalg.svd(X.T.dot(X))
S = np.diag(S)
X_sq_reg_inv = V.dot(np.linalg.pinv(S)).dot(U.T)
self.w = X_sq_reg_inv.dot(X.T).dot(y)
else:
super(LinearRegression, self).fit(X, y)
这里使用两种方式进行计算。如果规定gradient_descent=True,那么使用随机梯度下降算法进行训练,否则使用标准方程法进行训练。
最后是使用:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
import sys
sys.path.append("/content/drive/My Drive/learn/ML-From-Scratch/") from mlfromscratch.utils import train_test_split, polynomial_features
from mlfromscratch.utils import mean_squared_error, Plot
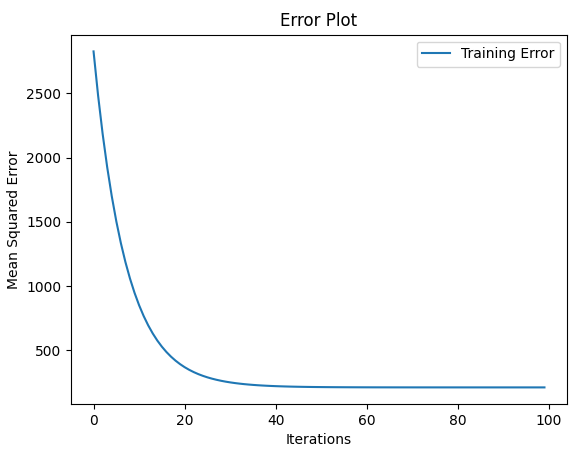
from mlfromscratch.supervised_learning import LinearRegression def main(): X, y = make_regression(n_samples=100, n_features=1, noise=20) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4) n_samples, n_features = np.shape(X) model = LinearRegression(n_iterations=100) model.fit(X_train, y_train) # Training error plot
n = len(model.training_errors)
training, = plt.plot(range(n), model.training_errors, label="Training Error")
plt.legend(handles=[training])
plt.title("Error Plot")
plt.ylabel('Mean Squared Error')
plt.xlabel('Iterations')
plt.savefig("test1.png")
plt.show() y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print ("Mean squared error: %s" % (mse)) y_pred_line = model.predict(X) # Color map
cmap = plt.get_cmap('viridis') # Plot the results
m1 = plt.scatter(366 * X_train, y_train, color=cmap(0.9), s=10)
m2 = plt.scatter(366 * X_test, y_test, color=cmap(0.5), s=10)
plt.plot(366 * X, y_pred_line, color='black', linewidth=2, label="Prediction")
plt.suptitle("Linear Regression")
plt.title("MSE: %.2f" % mse, fontsize=10)
plt.xlabel('Day')
plt.ylabel('Temperature in Celcius')
plt.legend((m1, m2), ("Training data", "Test data"), loc='lower right')
plt.savefig("test2.png")
plt.show() if __name__ == "__main__":
main()
利用sklearn库生成线性回归数据,然后将其拆分为训练集和测试集。
utils下的mean_squared_error():
def mean_squared_error(y_true, y_pred):
""" Returns the mean squared error between y_true and y_pred """
mse = np.mean(np.power(y_true - y_pred, 2))
return mse
结果:
Mean squared error: 532.3321383700828

python实现线性回归之简单回归的更多相关文章
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- python实现线性回归
参考:<机器学习实战>- Machine Learning in Action 一. 必备的包 一般而言,这几个包是比较常见的: • matplotlib,用于绘图 • numpy,数组处 ...
- python求线性回归斜率
一. 先说我对这个题目的理解 直线的x,y方程是这样的:y = kx+b, k就是斜率. 求线性回归斜率, 就是说 有这么一组(x, y)的对应值——样本.如果有四组,就说样本量是4.根据这些样本,做 ...
- 吴裕雄 python 机器学习——线性回归模型
import numpy as np from sklearn import datasets,linear_model from sklearn.model_selection import tra ...
- python模拟线性回归的点
构造符合线性回归的数据点 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # 随机生成1000个点 ...
- python机器学习---线性回归案例和KNN机器学习案例
散点图和KNN预测 一丶案例引入 # 城市气候与海洋的关系研究 # 导包 import numpy as np import pandas as pd from pandas import Serie ...
- Python机器学习/LinearRegression(线性回归模型)(附源码)
LinearRegression(线性回归) 2019-02-20 20:25:47 1.线性回归简介 线性回归定义: 百科中解释 我个人的理解就是:线性回归算法就是一个使用线性函数作为模型框架($ ...
- 机器学习之线性回归(纯python实现)][转]
本文转载自:https://juejin.im/post/5a924df16fb9a0634514d6e1 机器学习之线性回归(纯python实现) 线性回归是机器学习中最基本的一个算法,大部分算法都 ...
- 【机器学习】线性回归python实现
线性回归原理介绍 线性回归python实现 线性回归sklearn实现 这里使用python实现线性回归,没有使用sklearn等机器学习框架,目的是帮助理解算法的原理. 写了三个例子,分别是单变量的 ...
随机推荐
- Python中的编码及操作文件
------------恢复内容开始------------ 1,字符编码 ASCII 用1个字符来表示所有的英文字母和特殊符号 GB2313(GBK)用2个字符来表示英文字母及中文字符,且决定如果 ...
- 并查集例题02.带权并查集(poj1182)
Description 动物王国中有三类动物A,B,C,这三类动物的食物链构成了有趣的环形.A吃B, B吃C,C吃A.现有N个动物,以1-N编号.每个动物都是A,B,C中的一种,但是我们并不知道它到底 ...
- Ruby学习计划-(0)前言
前言 接触过的编程语言现在来说有C.C++.Java.Object-C.Swift.这几门语言中最熟悉的就是oc了,毕竟靠他吃饭,对于其他几门语言都是初入门径而已,由于本身一直从事iPhone ...
- python:*args和**kwargs的用法
1.*args用来将参数打包成tuple给函数体调用 代码: # *args用来将参数打包成tuple给函数体调用 def func(*args): print(args,type(args)) fu ...
- 单周期CPU
一个时钟周期执行一条指令的过程理解(单周期CPU): https://blog.csdn.net/a201577F0546/article/details/84726912 单周期CPU指的是一条指令 ...
- Mysql索引、explain执行计划
1.索引的使用场景 哪些情况使用索引: 1.主键自动建立唯一索引 2.频繁作为查询条件的字段应该创建索引 where 3.多表关联查询中,关联字段应该创建索引on两边都要创建索引 select * f ...
- .Net微服务实践(五)[服务发现]:Consul介绍和环境搭建
目录 介绍 服务发现 健康检查.键值存储和数据中心 架构 Consul模式 环境安装 HTTP API 和Command CLI 示例API介绍 最后 在上篇.Net微服务实践(四)[网关]:Ocel ...
- MySQL入门,第二部分,必备基础知识点
一.数据类型 日期和时间数据类型 date 字节 日期,格式:2014-09-18 日期和时间数据类型 time 字节 时间,格式:08:42:30 日期和时间数据类型 datetime 字节 日期时 ...
- Linux网络安全篇,进入SELinux的世界(二)
一.简单的网页制作 1.启动httpd服务 /etc/init.d/httpd start 2.编写首页网页文件 echo "hello,this is my first webPage&q ...
- Jmeter使用Websocket插件测试SingalR,外加还有阿里云PTS的Jmeter原生测试爬坑日志。
题外话:距离我的上一篇博客已经过去7年多了,我实在是个不务正业的程序员,遇到测试方面的东西总想分享一下,因为可用的资料实在太少了(包括国外的资料). 本人不喜欢授人以鱼,所以不会直接给出问题和解决方案 ...