吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析
# 导入第三方模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import cluster
from sklearn.datasets.samples_generator import make_blobs
# 模拟数据集
X,y = make_blobs(n_samples = 2000, centers = [[-1,-2],[1,3]], cluster_std = [0.5,0.5], random_state = 1234)
# 将模拟得到的数组转换为数据框,用于绘图
plot_data = pd.DataFrame(np.column_stack((X,y)), columns = ['x1','x2','y'])
# 设置绘图风格
plt.style.use('ggplot')
# 绘制散点图(用不同的形状代表不同的簇)
sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o'],
fit_reg = False, legend = False)
# 显示图形
plt.show()

# 导入第三方模块
from sklearn import cluster
# 构建Kmeans聚类和密度聚类
kmeans = cluster.KMeans(n_clusters=2, random_state=1234)
kmeans.fit(X)
dbscan = cluster.DBSCAN(eps = 0.5, min_samples = 10)
dbscan.fit(X)
# 将Kmeans聚类和密度聚类的簇标签添加到数据框中
plot_data['kmeans_label'] = kmeans.labels_
plot_data['dbscan_label'] = dbscan.labels_
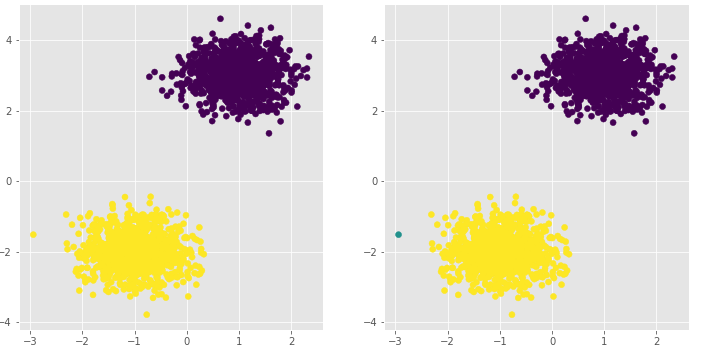
# 绘制聚类效果图
# 设置大图框的长和高
plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (1,2), loc = (0,0))
# 绘制散点图
ax1.scatter(plot_data.x1, plot_data.x2, c = plot_data.kmeans_label)
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (1,2), loc = (0,1))
# 绘制散点图(为了使Kmeans聚类和密度聚类的效果图颜色一致,通过序列的map“方法”对颜色作重映射)
ax2.scatter(plot_data.x1, plot_data.x2, c=plot_data.dbscan_label.map({-1:1,0:2,1:0}))
# 显示图形
plt.show()
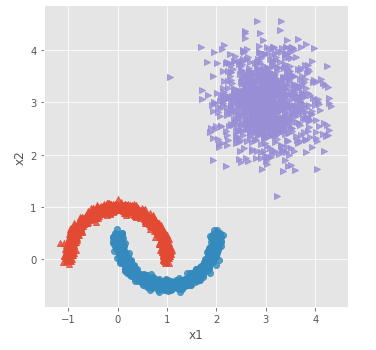
# 导入第三方模块
from sklearn.datasets.samples_generator import make_moons
# 构造非球形样本点
X1,y1 = make_moons(n_samples=2000, noise = 0.05, random_state = 1234)
# 构造球形样本点
X2,y2 = make_blobs(n_samples=1000, centers = [[3,3]], cluster_std = 0.5, random_state = 1234)
# 将y2的值替换为2(为了避免与y1的值冲突,因为原始y1和y2中都有0这个值)
y2 = np.where(y2 == 0,2,0)
# 将模拟得到的数组转换为数据框,用于绘图
plot_data = pd.DataFrame(np.row_stack([np.column_stack((X1,y1)),np.column_stack((X2,y2))]), columns = ['x1','x2','y'])
# 绘制散点图(用不同的形状代表不同的簇)
sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o','>'],
fit_reg = False, legend = False)
# 显示图形
plt.show()
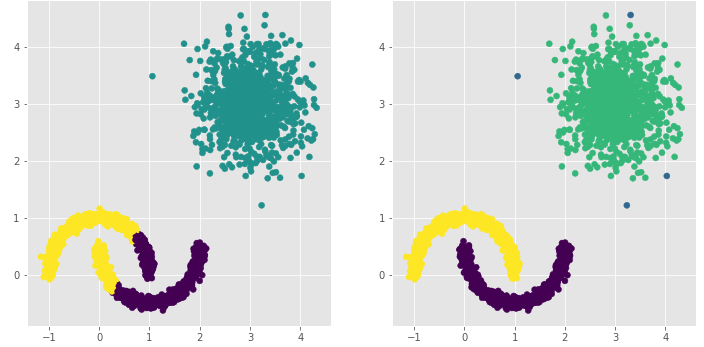
# 构建Kmeans聚类和密度聚类
kmeans = cluster.KMeans(n_clusters=3, random_state=1234)
kmeans.fit(plot_data[['x1','x2']])
dbscan = cluster.DBSCAN(eps = 0.3, min_samples = 5)
dbscan.fit(plot_data[['x1','x2']])
# 将Kmeans聚类和密度聚类的簇标签添加到数据框中
plot_data['kmeans_label'] = kmeans.labels_
plot_data['dbscan_label'] = dbscan.labels_
# 绘制聚类效果图
# 设置大图框的长和高
plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (1,2), loc = (0,0))
# 绘制散点图
ax1.scatter(plot_data.x1, plot_data.x2, c = plot_data.kmeans_label)
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (1,2), loc = (0,1))
# 绘制散点图(为了使Kmeans聚类和密度聚类的效果图颜色一致,通过序列的map“方法”对颜色作重映射)
ax2.scatter(plot_data.x1, plot_data.x2, c=plot_data.dbscan_label.map({-1:1,0:0,1:3,2:2}))
# 显示图形
plt.show()
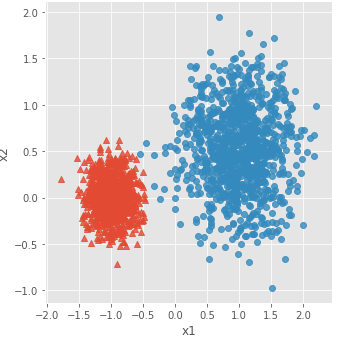
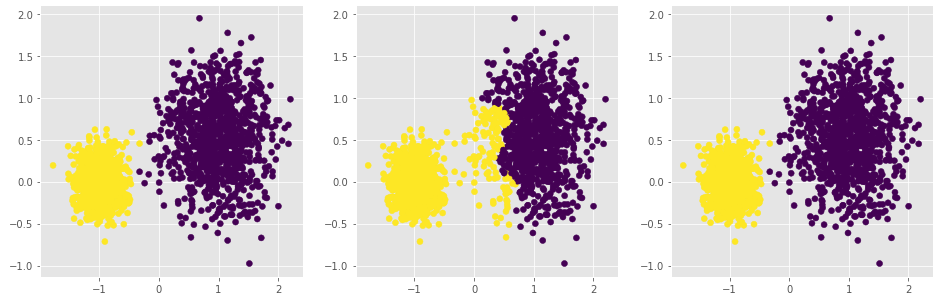
# 构造两个球形簇的数据样本点
X,y = make_blobs(n_samples = 2000, centers = [[-1,0],[1,0.5]], cluster_std = [0.2,0.45], random_state = 1234)
# 将模拟得到的数组转换为数据框,用于绘图
plot_data = pd.DataFrame(np.column_stack((X,y)), columns = ['x1','x2','y'])
# 绘制散点图(用不同的形状代表不同的簇)
sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o'],
fit_reg = False, legend = False)
# 显示图形
plt.show()
# 设置大图框的长和高
plt.figure(figsize = (16,5))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (1,3), loc = (0,0))
# 层次聚类--最小距离法
agnes_min = cluster.AgglomerativeClustering(n_clusters = 2, linkage='ward')
agnes_min.fit(X)
# 绘制聚类效果图
ax1.scatter(X[:,0], X[:,1], c=agnes_min.labels_)
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (1,3), loc = (0,1))
# 层次聚类--最大距离法
agnes_max = cluster.AgglomerativeClustering(n_clusters = 2, linkage='complete')
agnes_max.fit(X)
ax2.scatter(X[:,0], X[:,1], c=agnes_max.labels_)
# 设置第三个子图的布局
ax2 = plt.subplot2grid(shape = (1,3), loc = (0,2))
# 层次聚类--平均距离法
agnes_avg = cluster.AgglomerativeClustering(n_clusters = 2, linkage='average')
agnes_avg.fit(X)
plt.scatter(X[:,0], X[:,1], c=agnes_avg.labels_)
plt.show()
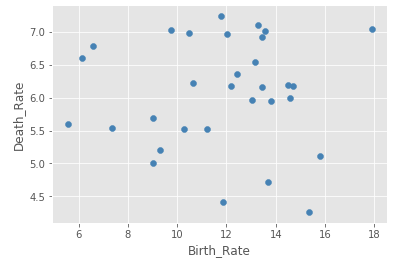
# 读取外部数据
Province = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\16\\Province.xlsx')
Province.head()
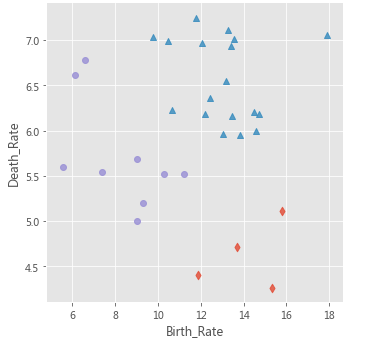
# 绘制出生率与死亡率散点图
plt.scatter(Province.Birth_Rate, Province.Death_Rate, c = 'steelblue')
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()
# 读入第三方包
from sklearn import preprocessing
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 选取建模的变量
predictors = ['Birth_Rate','Death_Rate']
# 变量的标准化处理
X = preprocessing.scale(Province[predictors])
X = pd.DataFrame(X)
# 构建空列表,用于保存不同参数组合下的结果
res = []
# 迭代不同的eps值
for eps in np.arange(0.001,1,0.05):
# 迭代不同的min_samples值
for min_samples in range(2,10):
dbscan = cluster.DBSCAN(eps = eps, min_samples = min_samples)
# 模型拟合
dbscan.fit(X)
# 统计各参数组合下的聚类个数(-1表示异常点)
n_clusters = len([i for i in set(dbscan.labels_) if i != -1])
# 异常点的个数
outliners = np.sum(np.where(dbscan.labels_ == -1, 1,0))
# 统计每个簇的样本个数
stats = str(pd.Series([i for i in dbscan.labels_ if i != -1]).value_counts().values)
res.append({'eps':eps,'min_samples':min_samples,'n_clusters':n_clusters,'outliners':outliners,'stats':stats})
# 将迭代后的结果存储到数据框中
df = pd.DataFrame(res)
# 根据条件筛选合理的参数组合
df.loc[df.n_clusters == 3, :]
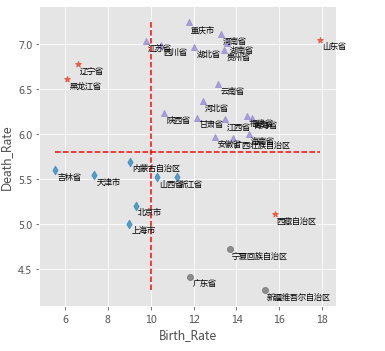
# 利用上述的参数组合值,重建密度聚类算法
dbscan = cluster.DBSCAN(eps = 0.801, min_samples = 3)
# 模型拟合
dbscan.fit(X)
Province['dbscan_label'] = dbscan.labels_
# 绘制聚类聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'dbscan_label', data = Province,
markers = ['*','d','^','o'], fit_reg = False, legend = False)
# 添加省份标签
for x,y,text in zip(Province.Birth_Rate,Province.Death_Rate, Province.Province):
plt.text(x+0.1,y-0.1,text, size = 8)
# 添加参考线
plt.hlines(y = 5.8, xmin = Province.Birth_Rate.min(), xmax = Province.Birth_Rate.max(),
linestyles = '--', colors = 'red')
plt.vlines(x = 10, ymin = Province.Death_Rate.min(), ymax = Province.Death_Rate.max(),
linestyles = '--', colors = 'red')
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()
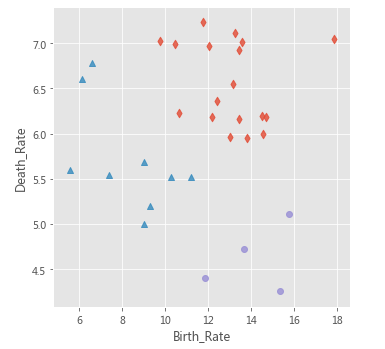
# 利用最小距离法构建层次聚类
agnes_min = cluster.AgglomerativeClustering(n_clusters = 3, linkage='ward')
# 模型拟合
agnes_min.fit(X)
Province['agnes_label'] = agnes_min.labels_
# 绘制层次聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'agnes_label', data = Province,
markers = ['d','^','o'], fit_reg = False, legend = False)
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()
# 导入第三方模块
from sklearn import metrics
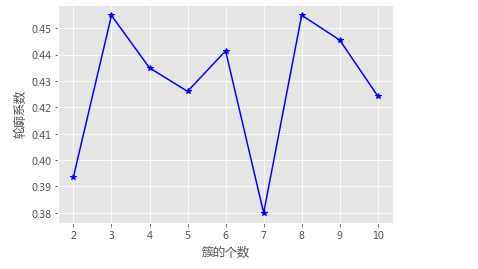
# 构造自定义函数,用于绘制不同k值和对应轮廓系数的折线图
def k_silhouette(X, clusters):
K = range(2,clusters+1)
# 构建空列表,用于存储个中簇数下的轮廓系数
S = []
for k in K:
kmeans = cluster.KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_
# 调用字模块metrics中的silhouette_score函数,计算轮廓系数
S.append(metrics.silhouette_score(X, labels, metric='euclidean'))
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
# 绘制K的个数与轮廓系数的关系
plt.plot(K, S, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('轮廓系数')
# 显示图形
plt.show()
# 聚类个数的探索
k_silhouette(X, clusters = 10)
# 利用Kmeans聚类
kmeans = cluster.KMeans(n_clusters = 3)
# 模型拟合
kmeans.fit(X)
Province['kmeans_label'] = kmeans.labels_
# 绘制Kmeans聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'kmeans_label', data = Province,
markers = ['d','^','o'], fit_reg = False, legend = False)
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
plt.show()
吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析的更多相关文章
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 吴裕雄 数据挖掘与分析案例实战(3)——python数值计算工具:Numpy
# 导入模块,并重命名为npimport numpy as np# 单个列表创建一维数组arr1 = np.array([3,10,8,7,34,11,28,72])print('一维数组:\n',a ...
- 吴裕雄 数据挖掘与分析案例实战(13)——GBDT模型的应用
# 导入第三方包import pandas as pdimport matplotlib.pyplot as plt # 读入数据default = pd.read_excel(r'F:\\pytho ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- 吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用
# 导入第三方包import pandas as pd # 导入数据Knowledge = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\1 ...
- 吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt # 自定义绘制ks曲线的函数def plot_ks(y_tes ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
- 吴裕雄 数据挖掘与分析案例实战(5)——python数据可视化
# 饼图的绘制# 导入第三方模块import matplotlibimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['S ...
- 吴裕雄 数据挖掘与分析案例实战(4)——python数据处理工具:Pandas
# 导入模块import pandas as pdimport numpy as np # 构造序列gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])print(g ...
随机推荐
- CentOS6.5 搭建在线yum源
CentOS6.5 搭建在线yum源 发布时间: 2017-04-21 浏览次数: 611 下载次数: 1 问题描述 尽管有很多的免费镜像提供yum源服务,但是还是有必要建立自己的yum服务器 ...
- Oracle Grid control 11g及Active DataGuard 11g安装部署
Oracle Grid control 11g及Active DataGuard 11g安装部署(一) 原贴 http://blog.csdn.net/lichangzai/article/detai ...
- typescript-dva脚手架
2019有太多的东西想尝试,ts,GraphQL,SSR,docker,python,electron,小程序云后台,vue3等等,一个个来吧,用两天了解了下typescript,大概做了个webpa ...
- BASIC-12_蓝桥杯_十六进制转八进制
总结: 1.使用库函数可有效节省空间,但时间花费较多; 2.由于本题的输入数据较大,又限制时间,故要注意利用空间换时间; 3.使用顺序结构换取最小运行时间; 示例代码: #include <st ...
- 【Spring学习笔记-MVC-8.1】SpringMVC之类型转换@initBinder
作者:ssslinppp 1. 摘要 类型转换器常用于转换double.float.date等类型. 上文讲解了Converter类型转换器,这属于Spring 3新支持的类型转换器: 本 ...
- setting.xml配置文件 --转载
转载出处:http://www.cnblogs.com/yakov/archive/2011/11/26/maven2_settings.html 在此,简单的说下 setting.xml 和 pom ...
- python selenium-4自动化测试模型
1.线性测试 特点:每一个脚本都是完整且独立的,可以单独执行. 缺点:用例的开发与维护成本很高 2.模块化驱动测试 特点:把重复的操作独立成公共模块,提高测试用例的可维护性 示例:将搜索封装到func ...
- asp控制项目超时
If Session("username")="" or isnull(Session("username")) Then %> &l ...
- TCP阻塞模式开发
在阻塞模式下,在IO操作完成前,执行的操作函数将一直等候而不会立刻返回,该函数所在的进程会阻塞在这里.相反,在非阻塞模式下,套接字函数会立即返回,而不管IO是否完成,该函数所在的线程将继续运行.阻塞模 ...
- .Net2.0部署在IIS8.5上的问题
请求的内容似乎是脚本,因而将无法由静态文件处理程序来处理. 到"应用程序池"里找网站对应的应用程序池(右击网站-> 高级设置),双击程序池, 看程序池是否也网站的net ...