(转)spark日志配置
一、第一部分
1、spark2.1与hadoop2.7.3集成,spark on yarn模式下,需要对hadoop的配置文件yarn-site.xml增加内容,如下:

<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2、spark的conf/spark-defaults.conf配置
spark.yarn.historyServer.address=node2:18080
spark.history.ui.port=18080
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///tmp/spark/events
spark.history.fs.logDirectory=hdfs:///tmp/spark/events
如果你是运行在yarn之上的话,就要告诉yarn,你spark的地址,当我在yarn上点击一个任务,进去看history的时候,他会链接到18080里面,如果你配的是node1:18080,那么你就要在node1上启动spark的history server(见后面注①)
最下面两个配置是运行spark程序的时候配置的,一旦你运行spark,就会将日志等发送到那两个目录,有了这两个目录,spark的historyserver就可以读取spark的运行状态信息日志等读取并展示
18080是spark的history server,会显示出你最近spark跑过的一些程序,点击execution后,点击最右边的日志(如果有的话),会重定向到19888(见后面注②),这个是mr的jobserver的地址(启动命令:mr-jobhistory-daemon.sh start historyserver)
spark.yarn.historyServer.address和spark.history.ui.port如果缺少其中一个,日志就看不到
综上,1和2两个配置齐全,才可以查看spark的stdout和stderr日志
二、第二部分

实际上,在spark程序运行的时候,会起一个driver程序和多个executor程序,他们都是跑在nodemanager之上的,在启动程序的时候,如果我们在默认的配置项里面,配置了参数spark.eventLog.enabled=true,spark.eventLog.dir=地址,那么driver上就会把所有的事件全部给记录下来,事件包括,executor的启动,executor执行的task等发送给driver
每当写日志的时候,都有一个写日志的组件将日志写进那个目录里面,这个目录下面每一个应用程序都会存在一个文件,然后将会由spark的history server(也就是配置在spark-default.conf里面),这个server会在18080启动一个进程,去扫描日志目录,并解析每一个文件,进行还原,就得到了整个应用的状态
在hadoop-2.7.3/etc/hadoop/mapred-site.xml配置文件中
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/user/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/user/history/done_intermediate</value>
</property>
stdlog和err是每一个nodemanager上的每一个executor都会产生的,如果当程序完成后,在这个节点上,跟这个应用相关的所有信息全部会被清除掉,包括这些日志,这样的话如果我们不把这个日志收集起来,那么后面在历史信息(18080 executord模块的stderr和out)里面就看不到这些日志
为了能够看到这些日志,我们要做的事情是,让nodemanager开启一个日志聚合的功能,这个功能的作用是,当应用程序终止的时候,需要将这个应用程序产生的所有日志全部聚集到远程hdfs上的一个目录,聚集之后,还需要通过一个http的接口去查看这些日志,查看日志的这个角色就叫做mr的history server,通过她的web ui接口,当我们点击std日志的时候,就会跳转到mr job history server这个地址上19888上,然后去把这个日志展示出来
三、总结
总的来说,yarn-site.xml和conf/spark-defaults.conf这两个配置文件中的地址比较关键
http://node2:19888/jobhistory/logs : 对应的是点击strout的时候跳转的地址
spark.yarn.historyServer.address=node2:18080 :对应的是在yarn里点击history,跳转的地址
注①:
1、进入yarn的web ui页面,点击左侧FINISHED,可查看运行完的作业,点击一个app id

2、进入下图页面,点击History
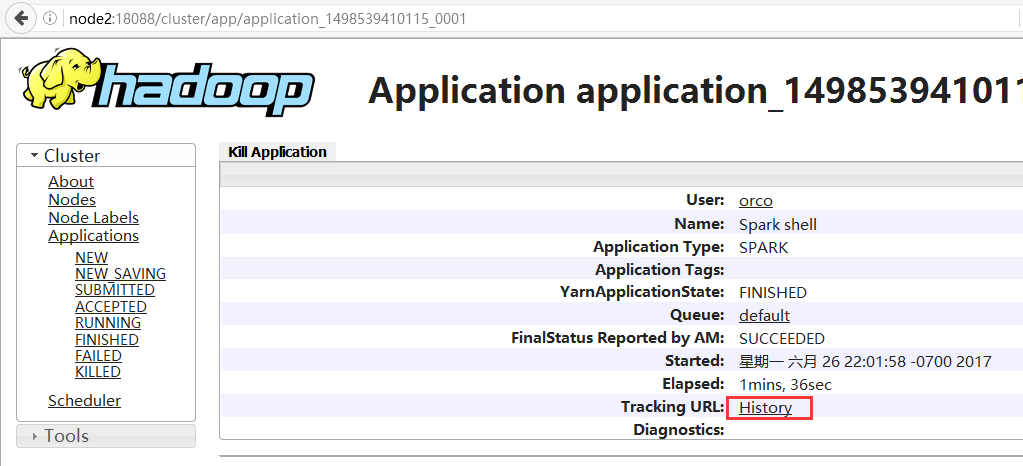
3、重定向到conf/spark-defaults.conf配置的地址

注②:
具体步骤如下:
1、我先运行一个spark程序
bin/spark-shell --master local
2、登录Spark History server的web ui
http://node1:18080/
3、如下图,找到我刚才运行的程序
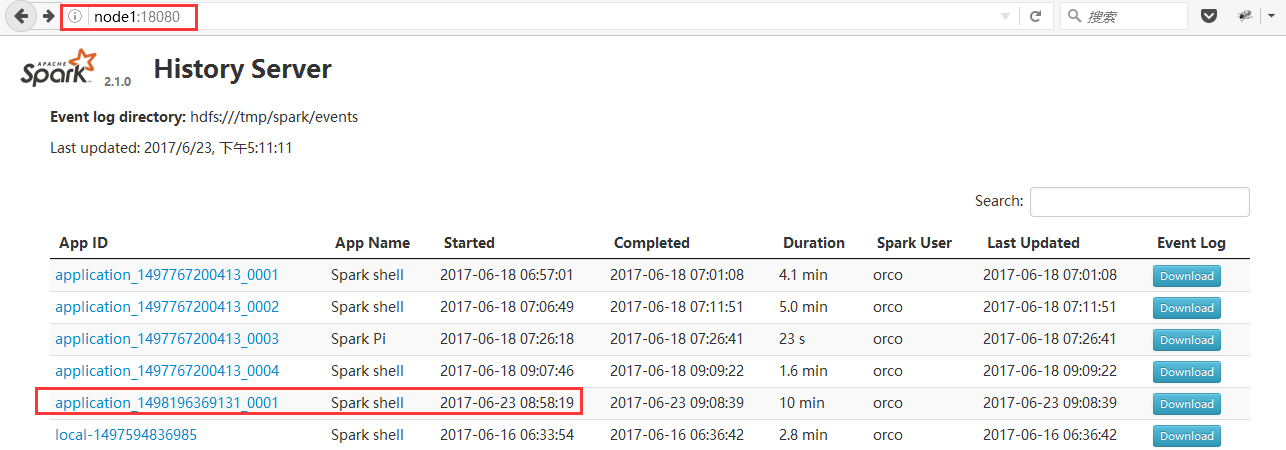 4、点击红框位置App ID,进入如下图页面
4、点击红框位置App ID,进入如下图页面
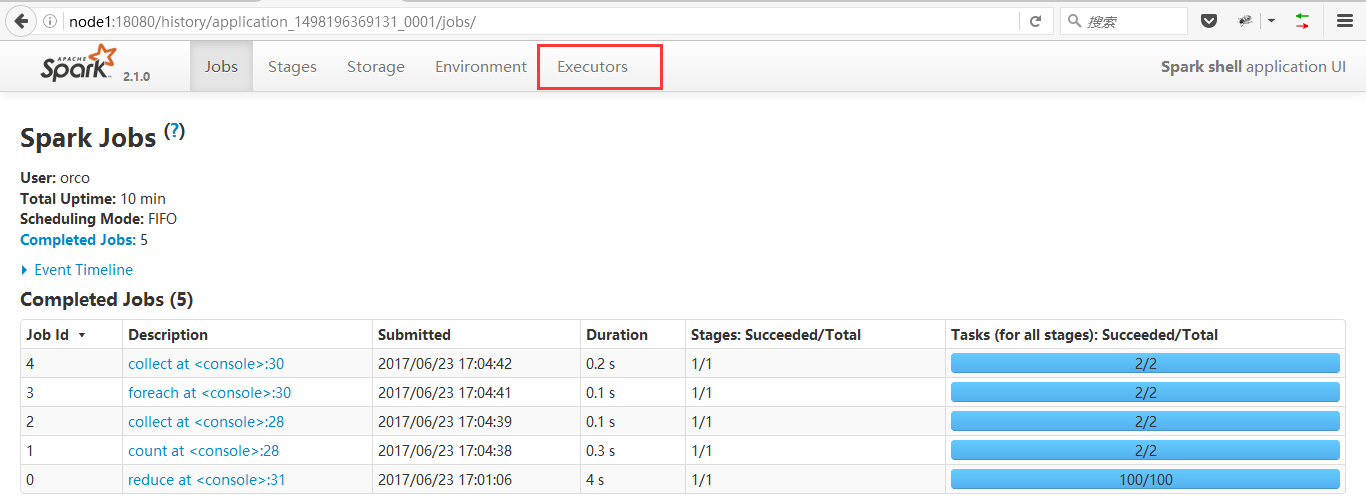
5、点击红框位置Executor,进入下图页面
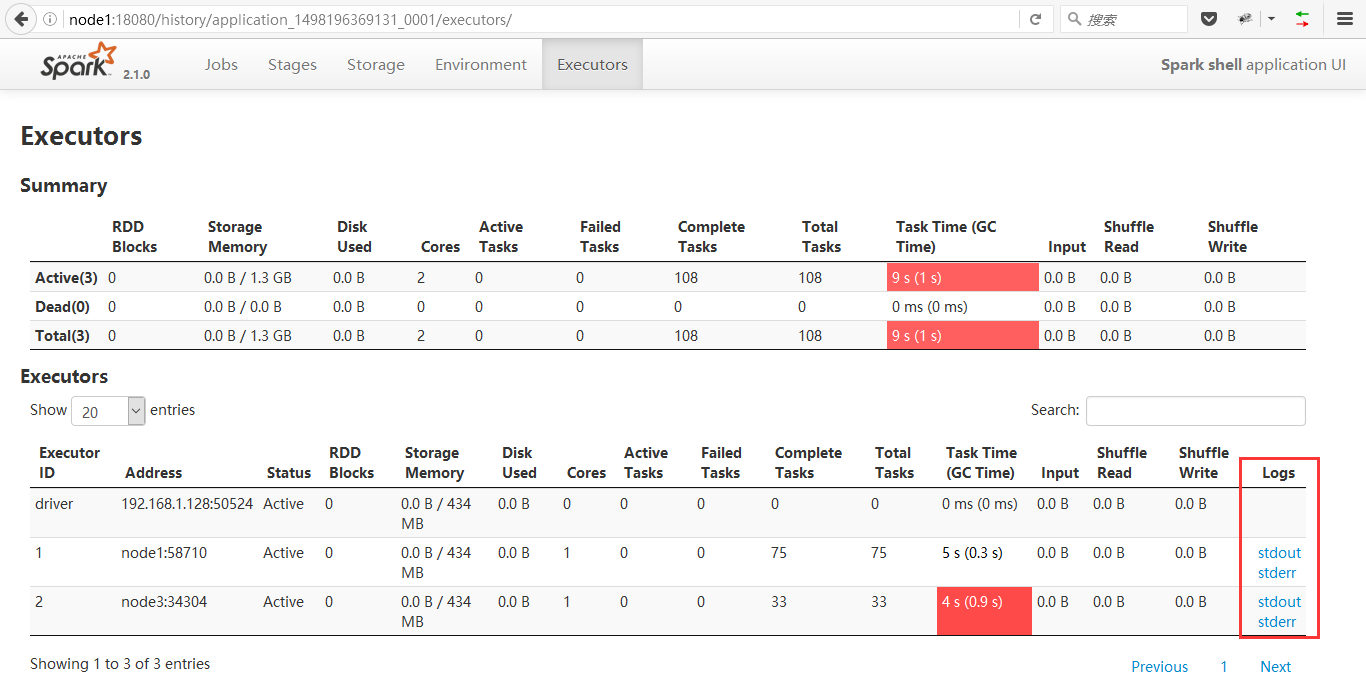
6、右下角的stderr和stdout就是我们此行的目标了
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
当你点击stderr或stdout,就会重定向到node2:19888,所以如果这里你配错了,那这两个日志你是看不了的
node2:19888是你的MapReduce job history server的启动节点地址
进入页面如下图
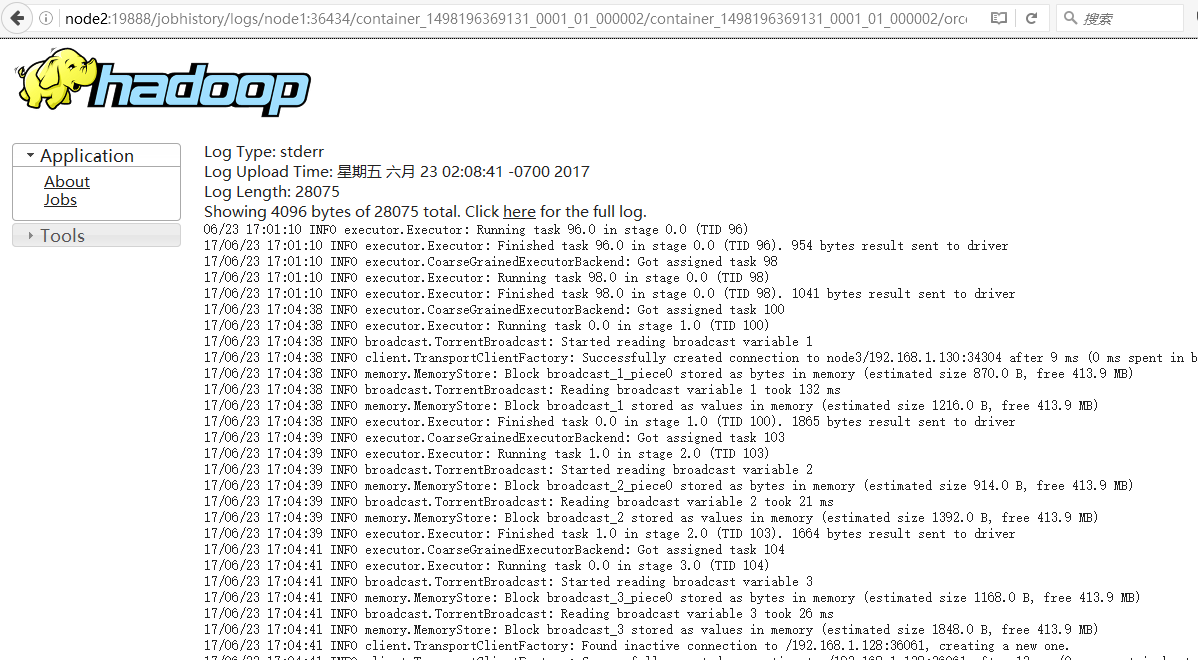
https://www.cnblogs.com/sorco/p/7070922.html
(转)spark日志配置的更多相关文章
- spark日志配置及问题排查方式。
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 任何时候日志都是定位问题的关键,spark也不会例外,合适的配置和获取spark的driver,am,及exe ...
- spark入门(四)日志配置
1 背景 在测试spark计算时,将作业提交到yarn(模式–master yarn-cluster)上,想查看print到控制台这是很难的,因为作业是提交到yarn的集群上,所以,去yarn集群上看 ...
- Spark 属性配置
1.Spark1.x 属性配置方式 Spark属性提供了大部分应用程序的控制项,并且可以单独为每个应用程序进行配置. 在Spark1.0.0提供了3种方式的属性配置: SparkConf方式 Spar ...
- Spark日志,及设置日志输出级别
Spark日志,及设置日志输出级别 1.全局应用设置 2.局部应用设置日志输出级别 3.Spark log4j.properties配置详解与实例(摘录于铭霏的记事本) 文章内容来源: 作者:大葱拌豆 ...
- django 1.8 日志配置
django 1.8 日志配置 以下为setings配置logging代码片段 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(_ ...
- nginx日志配置
nginx日志配置 http://www.ttlsa.com/linux/the-nginx-log-configuration/ 日志对于统计排错来说非常有利的.本文总结了nginx日志相关的配置如 ...
- 日志配置logback
在选择项目日志框架时,发现log4j的作者开发了新的日志框架,据说性能提高不少,那就选它了,不过,除了配置上有点不习惯外,最重要的一点 ,打印线程号这个功能依然没有(打印线程名这个东西是在是个鸡肋). ...
- 服务器是windows时tomcat无法打印所有日志配置修改
Tomcat运行仅一天磁盘空间突然就增加了很多,发现是日志文件太大了,修改tomcat的日志配置即可. 查看目录所占空间大小: ? 1 [root@XXX webapps]du -sh 清理方法: ? ...
- [译]Stairway to Integration Services Level 12 - 高级日志配置
介绍 本文中,我们将结合之前学习的时间冒泡,日志记录,以及复制模型.建立一个自定义的SSIS包日志模型. SSIS Task事件回顾 Reviewing SSIS Task Events 在做实 ...
随机推荐
- [转]Intellij IDEA快捷键与使用小技巧
Ctrl+Shift + Enter,语句完成“!”,否定完成,输入表达式时按 “!”键Ctrl+E,最近的文件Ctrl+Shift+E,最近更改的文件Shift+Click,可以关闭文件Ctrl+[ ...
- [转]PostgreSQL教程:系统表详解
这篇文章主要介绍了PostgreSQL教程(十五):系统表详解,本文讲解了pg_class.pg_attribute.pg_attrdef.pg_authid.pg_auth_members.pg_c ...
- 使用 http 请求方式获取 eureka server的服务信息
对于一些系统不能接入 eureka server,又需要访问接入eureka server 的服务. 方法一:直接调用服务的地址是一种实现方式,弊端就是地址是写死的,万一服务地址变更则访问不到. 方法 ...
- activiti 6 查询api
1 activiti 查询多字段排序 每个字段都要有 sortBy -> desc/asc [sortBy -> desc/asc] [sortBy -> desc/asc] 2 使 ...
- mysql中查询一个字段属于哪一个数据库中的哪一个表的方式
mysql中查询一个字段具体是属于哪一个数据库的那一张表:用这条语句就能查询出来,其中 table_schema 是所在库, table_name 是所在表 --mysql中查询某一个字段名属于哪一个 ...
- php分享二十四:数组
1:isset() 对于数组中为 NULL 的值不会返回 TRUE,而 array_key_exists() 会. 2:利用array_filter和strlen快速过滤数组中等于0的值 $path ...
- tomcat重启步骤
tomcat重启步骤1.切换到tomcat目录cd /home/tomcat-home/tomcat-erp/bin2.关闭tomcatsh shutdown.sh3.启动tomcatsh start ...
- [LeetCode] Basic Calculator & Basic Calculator II
Basic Calculator Implement a basic calculator to evaluate a simple expression string. The expression ...
- Fiddler 抓取 app 网络请求数据
通过设置代理在同一个路由器下可以通过 Fiddler 实现抓取 app 的网络数据 步骤如下: 手机(Android ,iOS 都可以)和 PC 连到同一个路由器 对手机连接的 WIFI 设置代理,代 ...
- 【Linux运维-集群技术进阶】Nginx+Keepalived+Tomcat搭建高可用/负载均衡/动静分离的Webserver集群
额.博客名字有点长.. . 前言 最终到这篇文章了,心情是有点激动的. 由于这篇文章会集中曾经博客讲到的全部Nginx功能点.包含主要的负载均衡,还有动静分离技术再加上这篇文章的重点.通过Keepal ...