第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件
创建爬虫文件是根据scrapy的母版来创建爬虫文件的
scrapy genspider -l 查看scrapy创建爬虫文件可用的母版
Available templates:母版说明
basic
创建基础爬虫文件
crawl
创建自动爬虫文件
csvfeed
创建爬取csv数据爬虫文件
xmlfeed
创建爬取xml数据爬虫文件
创建一个基础母版爬虫,其他同理
scrapy
genspider -t 母版名称 爬虫文件名称 要爬取的域名 创建一个基础母版爬虫,其他同理
如:scrapy genspider -t crawl lagou www.lagou.com
第一步,配置items.py接收数据字段
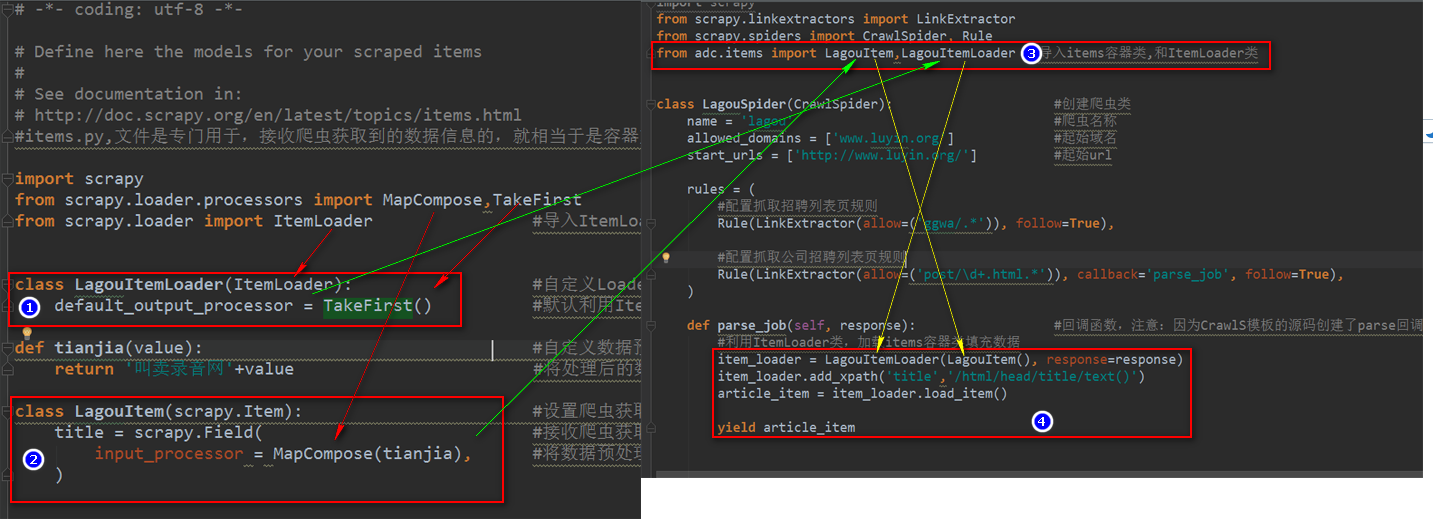
default_output_processor = TakeFirst()默认利用ItemLoader类,加载items容器类填充数据,是列表类型,可以通过TakeFirst()方法,获取到列表里的内容
input_processor = MapCompose(预处理函数)设置数据字段的预处理函数,可以是多个函数
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
#items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件 import scrapy
from scrapy.loader.processors import MapCompose,TakeFirst
from scrapy.loader import ItemLoader #导入ItemLoader类也就加载items容器类填充数据 class LagouItemLoader(ItemLoader): #自定义Loader继承ItemLoader类,在爬虫页面调用这个类填充数据到Item类
default_output_processor = TakeFirst() #默认利用ItemLoader类,加载items容器类填充数据,是列表类型,可以通过TakeFirst()方法,获取到列表里的内容 def tianjia(value): #自定义数据预处理函数
return '叫卖录音网'+value #将处理后的数据返给Item class LagouItem(scrapy.Item): #设置爬虫获取到的信息容器类
title = scrapy.Field( #接收爬虫获取到的title信息
input_processor = MapCompose(tianjia), #将数据预处理函数名称传入MapCompose方法里处理,数据预处理函数的形式参数value会自动接收字段title
)
第二步,编写自动爬虫与利用ItemLoader类加载items容器类填充数据
自动爬虫
Rule()设置爬虫规则
参数:
LinkExtractor()设置url规则
callback='回调函数名称'
follow=True 表示在抓取页面继续深入
LinkExtractor()对爬虫获取到的url做规则判断处理
参数:
allow= r'jobs/' 是一个正则表达式,表示符合这个url格式的,才提取
deny= r'jobs/' 是一个正则表达式,表示符合这个url格式的,不提取抛弃掉,与allow相反
allow_domains= www.lagou.com/ 表示这个域名下的连接才提取
deny_domains= www.lagou.com/ 表示这个域名下的连接不提取抛弃
restrict_xpaths= xpath表达式 表示可以用xpath表达式限定爬虫只提取一个页面指定区域的URL
restrict_css= css选择器,表示可以用css选择器限定爬虫只提取一个页面指定区域的URL
tags= 'a' 表示爬虫通过a标签去寻找url,默认已经设置,默认即可
attrs= 'href' 表示获取到a标签的href属性,默认已经设置,默认即可
利用自定义Loader类继承ItemLoader类,加载items容器类填充数据
ItemLoader()实例化一个ItemLoader对象来加载items容器类,填充数据,如果是自定义Loader继承的ItemLoader同样的用法
参数:
第一个参数:要填充数据的items容器类注意加上括号,
第二个参数:response
ItemLoader对象下的方法:
add_xpath('字段名称','xpath表达式')方法,用xpath表达式获取数据填充到指定字段
add_css('字段名称','css选择器')方法,用css选择器获取数据填充到指定字段
add_value('字段名称',字符串内容)方法,将指定字符串数据填充到指定字段
load_item()方法无参,将所有数据生成,load_item()方法被yield后数据被填充items容器指定类的各个字段
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from adc.items import LagouItem,LagouItemLoader #导入items容器类,和ItemLoader类 class LagouSpider(CrawlSpider): #创建爬虫类
name = 'lagou' #爬虫名称
allowed_domains = ['www.luyin.org'] #起始域名
start_urls = ['http://www.luyin.org/'] #起始url rules = (
#配置抓取列表页规则
Rule(LinkExtractor(allow=('ggwa/.*')), follow=True), #配置抓取内容页规则
Rule(LinkExtractor(allow=('post/\d+.html.*')), callback='parse_job', follow=True),
) def parse_job(self, response): #回调函数,注意:因为CrawlS模板的源码创建了parse回调函数,所以切记我们不能创建parse名称的函数
#利用ItemLoader类,加载items容器类填充数据
item_loader = LagouItemLoader(LagouItem(), response=response)
item_loader.add_xpath('title','/html/head/title/text()')
article_item = item_loader.load_item() yield article_item
items.py文件与爬虫文件的原理图
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制的更多相关文章
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- 第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册
第三百八十四节,Django+Xadmin打造上线标准的在线教育平台—路由映射与静态文件配置以及会员注册 基于类的路由映射 from django.conf.urls import url, incl ...
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍 Requests请求 Requests请求就是我们在爬虫文件写的Requests() ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表、课程章节表、课程视频表、课程资源表
第三百七十四节,Django+Xadmin打造上线标准的在线教育平台—创建课程app,在models.py文件生成4张表,课程表.课程章节表.课程视频表.课程资源表 创建名称为app_courses的 ...
- 第三百一十四节,Django框架,自定义分页
第三百一十四节,Django框架,自定义分页 自定义分页模块 #!/usr/bin/env python #coding:utf-8 from django.utils.safestring impo ...
随机推荐
- ES monitoring
https://www.quora.com/What-is-the-best-monitoring-tool-for-Elasticsearch-I-also-want-log-monitoring- ...
- vim学习日志(8):linux查看和修改文件编码
查看文件的编码 方法一: 1.在Vim中可以直接查看文件编码:set fileencoding即可显示文件编码格式.注:如果你只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问题,那么你可 ...
- 【线程】linux之thread错误解决方案
1.错误现象: undefined reference to 'pthread_create' undefined reference to 'pthread_join' 2.问题原因: pt ...
- git命令--git checkout 之 撤销提交到暂存区的更改
SYJ@WIN-95I6OG3AT1N /D/gitlab/ihr-kafka-produce (master) $ git status [由于工作区文件被修改了,所以显示为红色] On branc ...
- Android.mk简介
http://www.cnblogs.com/hnrainll/archive/2012/12/18/2822711.html Android.mk文件是GNU Makefile的一小部分,它用来对A ...
- spring boot映射静态资源.
增加配置文件 package com.wisely.upload.config; import org.springframework.context.annotation.Configuration ...
- hadoop的核心思想【转】
[转自]:http://www.superwu.cn/2014/01/10/963/ 1.1.1. hadoop的核心思想 Hadoop包括两大核心,分布式存储系统和分布式计算系统. 1.1.1.1. ...
- iOS中大文件下载(单线程下载)
主要是需要注意,在客服端发请求给服务器的时候,在请求头里是可以设置服务器返回的数据从哪开始,到哪结束的. 当服务器响应客户端时,是可以拿到服务器返回数据具体类型以及大小的 思路: 在接收到服务器响应时 ...
- django 部署,gunicorn、virtualenv、nginx
声明: 1.本篇文章是我边写命令边写的,请尊重我的劳动成果,转载请加上链接. 2.我既然公开写出来,是希望大家遇到问题的时候有个参考,所以,大家可以免费转载,使用该文章 3.但是,如果你要用这篇文章来 ...
- CentOS 7 下安装 Nginx(转)
转载自:http://www.linuxidc.com/Linux/2016-09/134907.htm 安装所需环境 Nginx 是 C语言 开发,建议在 Linux 上运行,当然,也可以安装 Wi ...