OpenACC 书上的范例代码(Jacobi 迭代),part 2
▶ 使用Jacobi 迭代求泊松方程的数值解
● 首次使用 OpenACC 进行加速。
■ win10下使用 -acc 选项时报错找不到结构 _timb,我把其定义(实际是结构 __timeb64)写到本文件中,发现计时器只能精确到秒,Ubuntu 中正常运行。
■ 把 win10 把计时器改回 <time.h> 中的 clock_t(下一部分代码起都改了),可以精确计时。
■ win10 下使用 PGI_ACC_TIME=1 来计时会报错:Error: internal error: invalid thread id,暂时无解。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <openacc.h> #if defined(_WIN32) || defined(_WIN64)
#include <C:\Program Files\PGI\win64\19.4\include\wrap\sys\timeb.h>
#define gettime(a) _ftime(a)
#define usec(t1,t2) ((((t2).time - (t1).time) * 1000 + (t2).millitm - (t1).millitm))
//typedef struct _timeb timestruct; // 使用 -acc 选项时报错找不到 _timb 结构,只能把原始定义写在这里
typedef struct
{
__time64_t time;
unsigned short millitm;
short timezone;
short dstflag;
} timestruct;
#else
#include <sys/time.h>
#define gettime(a) gettimeofday(a, NULL)
#define usec(t1,t2) (((t2).tv_sec - (t1).tv_sec) * 1000000 + (t2).tv_usec - (t1).tv_usec)
typedef struct timeval timestruct;
#endif inline float uval(float x, float y)
{
return x * x + y * y;
} int main()
{
const int row = , col = ;
const float height = 1.0, width = 2.0;
const float hx = height / row, wy = width / col;
const float fij = -4.0f;
const float hx2 = hx * hx, wy2 = wy * wy, c1 = hx2 * wy2, c2 = 1.0f / (2.0 * (hx2 + wy2));
const int maxIter = ;
const int colPlus = col + ; float *restrict u0 = (float *)malloc(sizeof(float)*(row + )*colPlus);
float *restrict u1 = (float *)malloc(sizeof(float)*(row + )*colPlus);
float *utemp = NULL; // 初始化
for (int ix = ; ix <= row; ix++)
{
u0[ix*colPlus + ] = u1[ix*colPlus + ] = uval(ix * hx, 0.0f);
u0[ix*colPlus + col] = u1[ix*colPlus + col] = uval(ix*hx, col * wy);
}
for (int jy = ; jy <= col; jy++)
{
u0[jy] = u1[jy] = uval(0.0f, jy * wy);
u0[row*colPlus + jy] = u1[row*colPlus + jy] = uval(row*hx, jy * wy);
}
for (int ix = ; ix < row; ix++)
{
for (int jy = ; jy < col; jy++)
u0[ix*colPlus + jy] = 0.0f;
} // 计算
timestruct t1, t2;
gettime(&t1);
acc_init(acc_device_nvidia); // 初始化设备,定义在 openacc.h 中,acc_device_nvidia 可用 4 代替
for (int iter = ; iter < maxIter; iter++)
{
#pragma acc kernels copy(u0[0:(row + 1) * colPlus], u1[0:(row + 1) * colPlus]) // 使用 kernels 和 loop
#pragma acc loop independent // 显式说明各次循环之间独立
for (int ix = ; ix < row; ix++)
{
#pragma acc loop independent // PGI 18.04 上不加这一行也行,PGI 19.04 上不加这一行会报
for (int jy = ; jy < col; jy++) // Complex loop carried dependence of u0->,u1-> prevents parallelization. Inner sequential loop scheduled on accelerator.
{
u1[ix*colPlus + jy] = (c1*fij + wy2 * (u0[(ix - )*colPlus + jy] + u0[(ix + )*colPlus + jy]) + \
hx2 * (u0[ix*colPlus + jy - ] + u0[ix*colPlus + jy + ])) * c2;
}
}
utemp = u0, u0 = u1, u1 = utemp;
}
gettime(&t2); long long timeElapse = usec(t1, t2);
#if defined(_WIN32) || defined(_WIN64)
printf("\nElapsed time: %13ld ms.\n", timeElapse);
#else
printf("\nElapsed time: %13ld us.\n", timeElapse);
#endif
free(u0);
free(u1);
acc_shutdown(acc_device_nvidia); // 关闭设备
//getchar();
return ;
}
● 输出结果,win10 下改了计时器以后运行时间 2370 ms
cuan@CUAN:~$ pgcc -c99 -acc -Minfo main.c -o main.exe
main:
, Memory zero idiom, loop replaced by call to __c_mzero4
, Generating copy(u1[:colPlus*(row+)],u0[:colPlus*(row+)])
FMA (fused multiply-add) instruction(s) generated
, Loop is parallelizable
, Loop is parallelizable
Generating Tesla code
, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */
, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */
uval:
, FMA (fused multiply-add) instruction(s) generated
cuan@CUAN:~$ ./main.exe
launch CUDA kernel file=/home/cuan/main.c function=main line= device= threadid= num_gangs= num_workers= vector_length= grid=32x1024 block=32x4 ... //98 行相同的内容,每个展开的循环一个 kernel launch CUDA kernel file=/home/cuan/main.c function=main line= device= threadid= num_gangs= num_workers= vector_length= grid=32x1024 block=32x4 Elapsed time: us. Accelerator Kernel Timing data
/home/cuan/main.c
main NVIDIA devicenum=
time(us): ,,
: data region reached times
: data copyin transfers:
device time(us): total=, max=, min=, avg=,
: data copyout transfers:
device time(us): total=, max=, min= avg=
: compute region reached times
: kernel launched times
grid: [32x1024] block: [32x4]
device time(us): total=, max= min= avg=
elapsed time(us): total=, max= min= avg= cuan@CUAN:~$ pgcc -c99 -acc -Minfo main.c -o main-fast.exe -fast // 使用 -fast 选项
main:
, uval inlined, size= (inline) file main.c () // 47 ~ 53 行也尝试优化
, Loop not fused: different loop trip count
Loop not vectorized: data dependency
Loop unrolled times
, uval inlined, size= (inline) file main.c ()
, uval inlined, size= (inline) file main.c ()
, Loop not vectorized: data dependency
Loop not vectorized: may not be beneficial
Loop unrolled times
, uval inlined, size= (inline) file main.c ()
, Memory zero idiom, loop replaced by call to __c_mzero4
, Generating copy(u1[:colPlus*(row+)],u0[:colPlus*(row+)])
Loop not vectorized/parallelized: contains call // 65 行拒绝优化
FMA (fused multiply-add) instruction(s) generated
, Loop is parallelizable
Loop not fused: no successor loop // 69 行拒绝优化
, Loop is parallelizable
Generating Tesla code
, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */
, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */
, Loop not vectorized: data dependency // 72 行拒绝优化
Loop unrolled times
cuan@CUAN:~$ ./main-fast.exe
launch CUDA kernel file=/home/cuan/main.c function=main line= device= threadid= num_gangs= num_workers= vector_length= grid=32x1024 block=32x4 ... // 跟没有 -fast 一样 launch CUDA kernel file=/home/cuan/main.c function=main line= device= threadid= num_gangs= num_workers= vector_length= grid=32x1024 block=32x4 Elapsed time: us. // 速度影响不大 Accelerator Kernel Timing data
/home/cuan/main.c
main NVIDIA devicenum=
time(us): ,,
: data region reached times
: data copyin transfers:
device time(us): total=, max=, min=, avg=,
: data copyout transfers:
device time(us): total=, max=, min= avg=
: compute region reached times
: kernel launched times
grid: [32x1024] block: [32x4]
device time(us): total=, max= min= avg=
elapsed time(us): total=, max=, min= avg=
● 使用 Nvvp 分析,发现密密麻麻的都是内存拷贝,计算反而是瞬间完成:
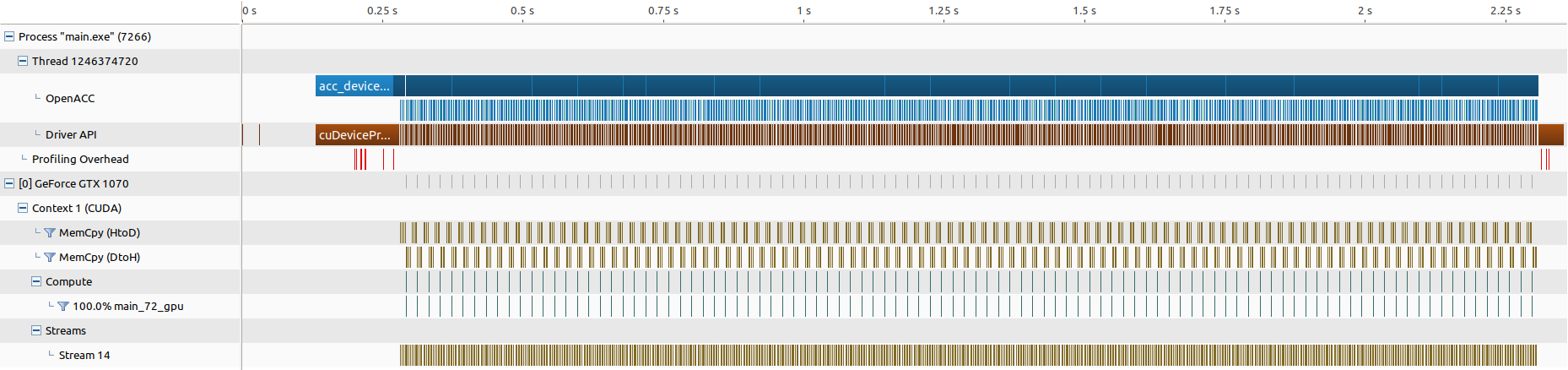
■ 注意数据管理导语 copy 是在 for(int iter=1;...) 内部的,所以会生成 100 个独立内核来运行,如果把它放到外侧(第 67 行改到 65 行之前)则会报错有以下报错:
PGC-S--Cannot determine bounds for array u0 (main.c: ) // 指针中不含有数组大小的信息
PGC-S--Cannot determine bounds for array u1 (main.c: )
main:
, Memory zero idiom, loop replaced by call to __c_mzero4
, Loop carried scalar dependence for u0 at line ,
Scalar last value needed after loop for u0 at line
Loop carried scalar dependence for u1 at line
Scalar last value needed after loop for u1 at line
Scalar last value needed after loop for u0 at line
Parallelization would require privatization of array u1[(colPlus)*i2+colPlus+:i1+i2+]
Generating Tesla code
, #pragma acc loop seq // 串行执行
, #pragma acc loop seq
, #pragma acc loop vector(128) /* threadIdx.x */
, Loop carried scalar dependence for u1 at line
Loop carried scalar dependence for u0 at line
Loop carried scalar dependence for u1 at line
Parallelization would require privatization of array u1[(colPlus)*i2+colPlus+:i1+i2+]
● 使用静态数组,此时可将数据管理导语 copy 放到 for之前,win10 下能运行,Linux上默认栈为 8 MB(ulimited -a),最大可调整为 64 MB(ulimited -s),两个数组除非调小否则刚好装不下,会报 dump core。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include <openacc.h> #if defined(_WIN32) || defined(_WIN64)
#include <C:\Program Files\PGI\win64\19.4\include\wrap\sys\timeb.h>
#define timestruct clock_t
#define gettime(a) (*(a) = clock())
#define usec(t1,t2) (t2 - t1)
#else
#include <sys/time.h>
#define gettime(a) gettimeofday(a, NULL)
#define usec(t1,t2) (((t2).tv_sec - (t1).tv_sec) * 1000000 + (t2).tv_usec - (t1).tv_usec)
typedef struct timeval timestruct;
#endif inline float uval(float x, float y)
{
return x * x + y * y;
} int main()
{
const int row = , col = , colPlus = col + ;
const float height = 1.0, width = 2.0;
const float hx = height / row, wy = width / col;
const float fij = -4.0f;
const float hx2 = hx * hx, wy2 = wy * wy, c1 = hx2 * wy2, c2 = 1.0f / (2.0 * (hx2 + wy2));
const int maxIter = ; float u0[(row + ) * (col + )];
float u1[(row + ) * (col + )]; // 初始化
for (int ix = ; ix < (row+) * colPlus; ix++)
u0[ix] = 0.0f;
for (int ix = ; ix <= row; ix++)
{
u0[ix*colPlus + ] = u1[ix*colPlus + ] = uval(ix * hx, 0.0f);
u0[ix*colPlus + col] = u1[ix*colPlus + col] = uval(ix*hx, col * wy);
}
for (int jy = ; jy <= col; jy++)
{
u0[jy] = u1[jy] = uval(0.0f, jy * wy);
u0[row*colPlus + jy] = u1[row*colPlus + jy] = uval(row*hx, jy * wy);
} // 计算
timestruct t1, t2;
gettime(&t1);
acc_init(acc_device_nvidia);
#pragma acc kernels copy(u0[0:(row + 1) * colPlus], u1[0:(row + 1) * colPlus]) // 换到 for (int iter = 0;...) 前面
for (int iter = ; iter < maxIter; iter++)
{
if (iter % ) // iter 奇偶性分类源数组和目标数组
{
#pragma acc loop independent
for (int ix = ; ix < row; ix++)
{
for (int jy = ; jy < col; jy++)
{
u0[ix*colPlus + jy] = (wy2 * (u1[(ix - ) * colPlus + jy] + u1[(ix + ) * colPlus + jy]) + \
hx2 * (u1[ix * colPlus + (jy - )] + u1[ix * colPlus + (jy + )]) + c1 * fij) * c2;
}
}
}
else
{
#pragma acc loop independent
for (int ix = ; ix < row; ix++)
{
for (int jy = ; jy < col; jy++)
{
u1[ix*colPlus + jy] = (wy2 * (u0[(ix - ) * colPlus + jy] + u0[(ix + ) * colPlus + jy]) + \
hx2 * (u0[ix * colPlus + (jy - )] + u0[ix * colPlus + (jy + )]) + c1 * fij) * c2;
}
}
}
}
gettime(&t2); long long timeElapse = usec(t1, t2);
#if defined(_WIN32) || defined(_WIN64)
printf("\nElapsed time: %13ld ms.\n", timeElapse);
#else
printf("\nElapsed time: %13ld us.\n", timeElapse);
#endif
acc_shutdown(acc_device_nvidia);
//getchar();
return ;
}
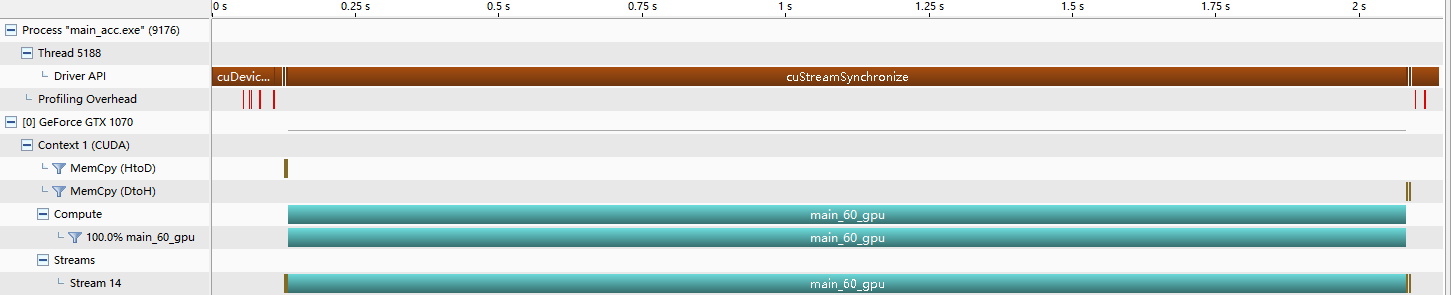
● 输出结果,在 Windows 里结果如下,在 WSL 里运行时间为 849 ms● 使用 Nvvp 分析,发现内存拷贝只有首尾两次,中间全在 GPU 上计算:
OpenACC 书上的范例代码(Jacobi 迭代),part 2的更多相关文章
- OpenACC 书上的范例代码(Jacobi 迭代),part 3
▶ 使用Jacobi 迭代求泊松方程的数值解 ● 使用 data 构件,强行要求 u0 仅拷入和拷出 GPU 各一次,u1 仅拷入GPU 一次 #include <stdio.h> #in ...
- OpenACC 书上的范例代码(Jacobi 迭代),part 1
▶ 使用Jacobi 迭代求泊松方程的数值解 ● 原始串行版本,运行时间 2272 ms #include <stdio.h> #include <stdlib.h> #inc ...
- C#高级编程(第9版) -C#5.0&.Net4.5.1 书上的示例代码下载链接
http://www.wrox.com/WileyCDA/WroxTitle/Professional-C-5-0-and-NET-4-5-1.productCd-1118833031,descCd- ...
- uva 213 - Message Decoding (我认为我的方法要比书上少非常多代码,不保证好……)
#include<stdio.h> #include<math.h> #include<string.h> char s[250]; char a[10][250] ...
- java代码流类。。程序怎么跟书上的结果不一样???
总结:这个程序很容易懂.的那是这个结果我觉得有问题啊..怎么“stop”后,输出的内容是输入过的呢? 应该是没有关系的呀,与输入的值是不同的....怎么书上运行的结果和我的不一样啊 package c ...
- 面试必备:高频算法题终章「图文解析 + 范例代码」之 矩阵 二进制 + 位运算 + LRU 合集
Attention 秋招接近尾声,我总结了 牛客.WanAndroid 上,有关笔试面经的帖子中出现的算法题,结合往年考题写了这一系列文章,所有文章均与 LeetCode 进行核对.测试.欢迎食用 本 ...
- JAVA理解逻辑程序的书上全部重要的习题
今天随便翻翻看以前学过JAVA理解逻辑程序的书上全部练习,为了一些刚学的学弟学妹,所以呢就把这些作为共享了. 希望对初学的学弟学妹有所帮助! 例子:升级“我行我素购物管理系统”,实现购物结算功能 代码 ...
- OK 开始实践书上的项目一:即使标记
OK 开始实践书上的项目一:及时标记 然而....又得往前面看啦! ----------------------我是分割线------------------------ 代码改变世界
- 关于node的基础理论,书上看来的
最近看了一本书,说了一些Node.js的东西,现在来记录一下,让自己记得更牢靠一点. 在书上,是这样介绍的:Node.js模型是源于Ruby的Event Machine 和 Python的Twiste ...
随机推荐
- Python3中 sys.argv的用法
sys.avgr 是一个Python的引用模块.刚好做一个作业需要用到它,在sublime上编辑后运行,试图从结果发现它的用途,然而结果一直都是没结果. 后面在网上查了资料,才明白过来.sys.arg ...
- Windows10 解决 “/”应用程序中的服务器错误
部署 ASP.NET MVC5程序时,访问网站出现 未能加载文件或程序集“698_BLL”或它的某一个依赖项.试图加载格式不正确的程序. ================= 解决办法: 1.打开IIS ...
- LeetCode Single Number I II Python
Single Number Given an array of integers, every element appears twice except for one. Find that sing ...
- map和jsonObject 这2中数据结构之间转换
前台写json直接是:var array = [ ] ; 调用方法:array[index],若是对象,再[“key”] var obj = {''a'':123 , "b":&q ...
- c#数据库訪问返回值类型为SqlDataReader时使用using时注意的问题
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/u010512579/article/details/24011761 在封装通用 SQLSERVER ...
- PHP中数组的各种用法
$a = 'false';if($a){ echo '好坑';}输出好坑,得转换成布尔值才行哦. in_array $people = array("Bill", "St ...
- ORACLE expdp/impdp详解
ORCALE10G提供了新的导入导出工具,数据泵.Oracle官方对此的形容是:Oracle DataPump technology enables Very High-Speed movement ...
- Django 实现CRM 问卷调查功能组件
目录结构: 母版 {% load staticfiles %} <!DOCTYPE html> <html lang="zh-CN"> <head&g ...
- qt 中文乱码
首先呢,声明一下,QString 是不存在中文支持问题的,很多人遇到问题,并不是本身 QString 的问题,而是没有将自己希望的字符串正确赋给QString. 很简单的问题,"我是中文&q ...
- react-native在mac上执行gradlew命令报错 ./gradlew: command not found
这是因为react-native项目是windows上初始化,通过git clone到mac机器上后gradlew这个文件没有可执行权限,如图: 所以只需要给gradlew这个文件增加可执行权限就可以 ...