『Scrapy』终端调用&选择器方法
Scrapy终端
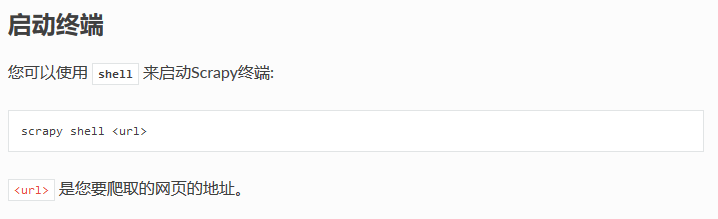
示例,输入如下命令后shell会进入Python(或IPython)交互式界面:
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
有一点注意的是必须是双引号,单引号会报错。
之后会显示当前保存的数据结构以供查询,这和我们编写py脚本时的数据结构完全相同,可以直接使用相关方法,
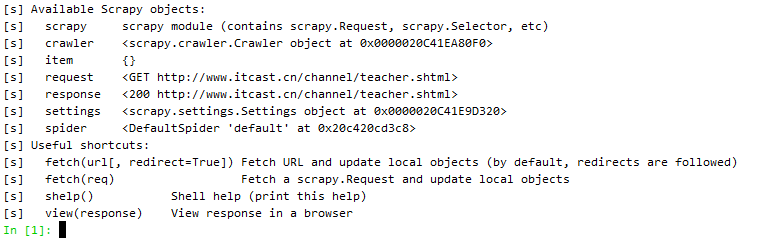
诸如:
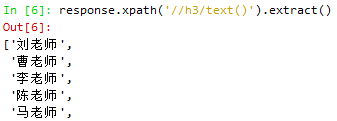
Scrapy Selectors

如下所示,
>>> response.xpath('//title/text()')
[<Selector (text) xpath=//title/text()>]
>>> response.css('title::text')
[<Selector (text) xpath=//title/text()>]这两种方式提取的都是节点型数据,所以都可以使用.extract()或者.extract_first()方法提取data部分

以下面的源码为例进行提取示范:
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
提取标签属性,
>>> response.xpath('//base/@href').extract()
[u'http://example.com/']
>>> response.css('base::attr(href)').extract()
[u'http://example.com/']对提取目标路径的标签进行筛选,contains(@href, "image")表示href熟悉需要包含image字符,css同理,
response.xpath('//a[contains(@href, "image")]/@href').extract()
Out[1]: ['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
response.xpath('//a[contains(@href, "image1")]/@href').extract()
Out[2]: ['image1.html']
response.css('a[href*=image]::attr(href)').extract()
Out[3]: ['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
esponse.css('a[href*=image2]::attr(href)').extract()
Out[4]: ['image2.html']结合两者,
>>> response.xpath('//a[contains(@href, "image")]/img/@src').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']
>>> response.css('a[href*=image] img::attr(src)').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']内置了正则表达式re和re_first方法,
response.xpath('//a[contains(@href, "image")]/text()')
Out[8]:
[<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 1 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 2 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 3 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 4 '>,
<Selector xpath='//a[contains(@href, "image")]/text()' data='Name: My image 5 '>]
response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:\s*(.*)')
Out[7]: ['My image 1 ', 'My image 2 ', 'My image 3 ', 'My image 4 ', 'My image 5 ']
response.xpath('//a[contains(@href, "image")]/text()').re_first(r'Name:\s*(.*)')
Out[9]: 'My image 1 '『Scrapy』终端调用&选择器方法的更多相关文章
- 『GoLang』结构体与方法
结构体 结构体类型 Go 通过结构体的形式支持用户自定义类型,或者叫定制类型. Go 语言结构体是实现自定义类型的一种重要数据类型. 结构体是复合类型(composite types),它由一系列属性 ...
- 『Java』接口的使用方法
以下三个文件存在于同一个包下: 定义接口Dome_Interface.java: package cn.xxmmqg.Interface; // 接口不能直接使用,必须有一个"实现类&quo ...
- 『Scrapy』爬取斗鱼主播头像
分析目标 爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣...... 目标URL如下, ...
- 『Scrapy』爬取腾讯招聘网站
分析爬取对象 初始网址, http://hr.tencent.com/position.php?@start=0&start=0#a (可选)由于含有多页数据,我们可以查看一下这些网址有什么相 ...
- 『Scrapy』全流程爬虫demo
建立好的爬虫工程如下: item.py 它用来存储解析后的响应文件: # -*- coding: utf-8 -*- # Define here the models for your scraped ...
- 『Scrapy』爬虫框架入门
框架结构 引擎:处于中央位置协调工作的模块 spiders:生成需求url直接处理响应的单元 调度器:生成url队列(包括去重等) 下载器:直接和互联网打交道的单元 管道:持久化存储的单元 框架安装 ...
- 『Python』Python 调用 ZoomEye API 批量获取目标网站IP
#### 20160712 更新 原API的访问方式是以 HTTP 的方式访问的,根据官网最新文档,现在已经修改成 HTTPS 方式,测试可以正常使用API了. 0x 00 前言 ZoomEye 的 ...
- 『Python』为什么调用函数会令引用计数+2
一.问题描述 Python中的垃圾回收是以引用计数为主,分代收集为辅,引用计数的缺陷是循环引用的问题.在Python中,如果一个对象的引用数为0,Python虚拟机就会回收这个对象的内存. sys.g ...
- 『Java』StringBuilder类使用方法
String类存在的问题 String类的底层是一个被final修饰的byte[],不能改变. 为了解决以上问题,可以使用java.lang.StringBuilder类. StringBuilder ...
随机推荐
- centos7源码编译安装Subversion 1.9.5
svn是Subversion的简称,是一个开放源代码的版本控制系统.svn有两种运行方式:1.独立服务器(svn://xxx.xxx/xxx) 2.借助apache(http://svn.xxx.xx ...
- 4 个技巧学习 Golang
到达 Golang 大陆:一位资深开发者之旅. 2014 年夏天…… IBM:“我们需要你弄清楚这个 Docker.” 我:“没问题.” IBM:“那就开始吧.” 我:“好的.”(内心声音):”Doc ...
- htpasswd命令的使用
htpasswd的基本用法 htpasswd是Apache服务器中生成用户认证的一个工具,仅说明htpasswd的用法: htpasswd参数 -c 创建passwdfile.如果passwdfile ...
- jdbc连接池c3p0/dbcp强制连接超过设置时间后失效
通常来说,各种技术实现的优化参数或者选项或者歪门邪道之所以能被想出来,通常是因为开发者或者实现的贡献者曾经遇到过导致此结果的问题,所以才出了对应的策略选项. 在有些情况下,比如存在客户端或者服务端连接 ...
- 关于STM32外接4—16MHz晶振主频处理方法
由于STM32F10x库官方采用的是默认的外接8MHz晶振,因此造成很多用户也采用了8MHz的晶振,但是,8MHz的晶振不是必须的,其他频点的晶振也是可行的,只需要在库中做相应的修改就行. 在论 ...
- QVector排序
QVector<double> tempX ; qSort(tempX.begin(), tempX.end());//从小到大排序
- BZOJ 2434 阿狸的打字机(fail树)
题目链接:http://61.187.179.132/JudgeOnline/problem.php?id=2434 题意:阿狸喜欢收藏各种稀奇古怪的东西,最近他淘到一台老式的打字机.打字机上只有28 ...
- 写一个标准宏MIN,输入两个参数,返回较小的
#define MIN(A,B) ((A) <= (B) ? (A) : (B))MIN(*p++, b)会产生宏的副作用 剖析: 这个面试题主要考查面试者对宏定义的使用,宏定义可以实现类似于函 ...
- linux交叉编译gcc4.8.3
1.环境: Ubuntu 16.04 2.获取 wget mirrors.ustc.edu.cn/gnu/gcc/gcc-4.8.3/gcc-4.8.3.tar.bz2 3.解压 tar xvf gc ...
- bootstrap的 附加导航Affix导航 (侧边窄条式 滚动监控式导航) 附加导航使用3.
affix: 意思是粘附, 附着, 沾上. 因此, 附加导航就是 bootstrap的 Affix.js组件. bootstrap的 附加导航, 不是说导航分成主导航, 或者什么 副导航的 而是指, ...