MapReduce部分源码解读(一)
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.hadoop.mapreduce.lib.input; import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext; import com.google.common.base.Charsets; /** An {@link InputFormat} for plain text files. Files are broken into lines.
* Either linefeed or carriage-return are used to signal end of line. Keys are
* the position in the file, and values are the line of text.. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextInputFormat extends FileInputFormat<LongWritable, Text> { @Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
} @Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
} }
TextInputFormat
父类(TextInputFormat本身含义为把每一行解析成键值对)
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.hadoop.mapreduce.lib.input; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.mapred.LocatedFileStatusFetcher;
import org.apache.hadoop.mapred.SplitLocationInfo;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.security.TokenCache;
import org.apache.hadoop.util.ReflectionUtils;
import org.apache.hadoop.util.StringUtils; import com.google.common.base.Stopwatch;
import com.google.common.collect.Lists; /**
* A base class for file-based {@link InputFormat}s.
*
* <p><code>FileInputFormat</code> is the base class for all file-based
* <code>InputFormat</code>s. This provides a generic implementation of
* {@link #getSplits(JobContext)}.
* Subclasses of <code>FileInputFormat</code> can also override the
* {@link #isSplitable(JobContext, Path)} method to ensure input-files are
* not split-up and are processed as a whole by {@link Mapper}s.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class FileInputFormat<K, V> extends InputFormat<K, V> {
public static final String INPUT_DIR =
"mapreduce.input.fileinputformat.inputdir";
public static final String SPLIT_MAXSIZE =
"mapreduce.input.fileinputformat.split.maxsize";
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
public static final String PATHFILTER_CLASS =
"mapreduce.input.pathFilter.class";
public static final String NUM_INPUT_FILES =
"mapreduce.input.fileinputformat.numinputfiles";
public static final String INPUT_DIR_RECURSIVE =
"mapreduce.input.fileinputformat.input.dir.recursive";
public static final String LIST_STATUS_NUM_THREADS =
"mapreduce.input.fileinputformat.list-status.num-threads";
public static final int DEFAULT_LIST_STATUS_NUM_THREADS = 1; private static final Log LOG = LogFactory.getLog(FileInputFormat.class); private static final double SPLIT_SLOP = 1.1; // 10% slop @Deprecated
public static enum Counter {
BYTES_READ
} private static final PathFilter hiddenFileFilter = new PathFilter(){
public boolean accept(Path p){
String name = p.getName();
return !name.startsWith("_") && !name.startsWith(".");
}
}; /**
* Proxy PathFilter that accepts a path only if all filters given in the
* constructor do. Used by the listPaths() to apply the built-in
* hiddenFileFilter together with a user provided one (if any).
*/
private static class MultiPathFilter implements PathFilter {
private List<PathFilter> filters; public MultiPathFilter(List<PathFilter> filters) {
this.filters = filters;
} public boolean accept(Path path) {
for (PathFilter filter : filters) {
if (!filter.accept(path)) {
return false;
}
}
return true;
}
} /**
* @param job
* the job to modify
* @param inputDirRecursive
*/
public static void setInputDirRecursive(Job job,
boolean inputDirRecursive) {
job.getConfiguration().setBoolean(INPUT_DIR_RECURSIVE,
inputDirRecursive);
} /**
* @param job
* the job to look at.
* @return should the files to be read recursively?
*/
public static boolean getInputDirRecursive(JobContext job) {
return job.getConfiguration().getBoolean(INPUT_DIR_RECURSIVE,
false);
} /**
* Get the lower bound on split size imposed by the format.
* @return the number of bytes of the minimal split for this format
*/
protected long getFormatMinSplitSize() {
return 1;
} /**
* Is the given filename splitable? Usually, true, but if the file is
* stream compressed, it will not be.
*
* <code>FileInputFormat</code> implementations can override this and return
* <code>false</code> to ensure that individual input files are never split-up
* so that {@link Mapper}s process entire files.
*
* @param context the job context
* @param filename the file name to check
* @return is this file splitable?
*/
protected boolean isSplitable(JobContext context, Path filename) {
return true;
} /**
* Set a PathFilter to be applied to the input paths for the map-reduce job.
* @param job the job to modify
* @param filter the PathFilter class use for filtering the input paths.
*/
public static void setInputPathFilter(Job job,
Class<? extends PathFilter> filter) {
job.getConfiguration().setClass(PATHFILTER_CLASS, filter,
PathFilter.class);
} /**
* Set the minimum input split size
* @param job the job to modify
* @param size the minimum size
*/
public static void setMinInputSplitSize(Job job,
long size) {
job.getConfiguration().setLong(SPLIT_MINSIZE, size);
} /**
* Get the minimum split size
* @param job the job
* @return the minimum number of bytes that can be in a split
*/
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
} /**
* Set the maximum split size
* @param job the job to modify
* @param size the maximum split size
*/
public static void setMaxInputSplitSize(Job job,
long size) {
job.getConfiguration().setLong(SPLIT_MAXSIZE, size);
} /**
* Get the maximum split size.
* @param context the job to look at.
* @return the maximum number of bytes a split can include
*/
public static long getMaxSplitSize(JobContext context) {
return context.getConfiguration().getLong(SPLIT_MAXSIZE,
Long.MAX_VALUE);
} /**
* Get a PathFilter instance of the filter set for the input paths.
*
* @return the PathFilter instance set for the job, NULL if none has been set.
*/
public static PathFilter getInputPathFilter(JobContext context) {
Configuration conf = context.getConfiguration();
Class<?> filterClass = conf.getClass(PATHFILTER_CLASS, null,
PathFilter.class);
return (filterClass != null) ?
(PathFilter) ReflectionUtils.newInstance(filterClass, conf) : null;
} /** List input directories.
* Subclasses may override to, e.g., select only files matching a regular
* expression.
*
* @param job the job to list input paths for
* @return array of FileStatus objects
* @throws IOException if zero items.
*/
protected List<FileStatus> listStatus(JobContext job
) throws IOException {
Path[] dirs = getInputPaths(job);
if (dirs.length == 0) {
throw new IOException("No input paths specified in job");
} // get tokens for all the required FileSystems..
TokenCache.obtainTokensForNamenodes(job.getCredentials(), dirs,
job.getConfiguration()); // Whether we need to recursive look into the directory structure
boolean recursive = getInputDirRecursive(job); // creates a MultiPathFilter with the hiddenFileFilter and the
// user provided one (if any).
List<PathFilter> filters = new ArrayList<PathFilter>();
filters.add(hiddenFileFilter);
PathFilter jobFilter = getInputPathFilter(job);
if (jobFilter != null) {
filters.add(jobFilter);
}
PathFilter inputFilter = new MultiPathFilter(filters); List<FileStatus> result = null; int numThreads = job.getConfiguration().getInt(LIST_STATUS_NUM_THREADS,
DEFAULT_LIST_STATUS_NUM_THREADS);
Stopwatch sw = new Stopwatch().start();
if (numThreads == 1) {
result = singleThreadedListStatus(job, dirs, inputFilter, recursive);
} else {
Iterable<FileStatus> locatedFiles = null;
try {
LocatedFileStatusFetcher locatedFileStatusFetcher = new LocatedFileStatusFetcher(
job.getConfiguration(), dirs, recursive, inputFilter, true);
locatedFiles = locatedFileStatusFetcher.getFileStatuses();
} catch (InterruptedException e) {
throw new IOException("Interrupted while getting file statuses");
}
result = Lists.newArrayList(locatedFiles);
} sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Time taken to get FileStatuses: " + sw.elapsedMillis());
}
LOG.info("Total input paths to process : " + result.size());
return result;
} private List<FileStatus> singleThreadedListStatus(JobContext job, Path[] dirs,
PathFilter inputFilter, boolean recursive) throws IOException {
List<FileStatus> result = new ArrayList<FileStatus>();
List<IOException> errors = new ArrayList<IOException>();
for (int i=0; i < dirs.length; ++i) {
Path p = dirs[i];
FileSystem fs = p.getFileSystem(job.getConfiguration());
FileStatus[] matches = fs.globStatus(p, inputFilter);
if (matches == null) {
errors.add(new IOException("Input path does not exist: " + p));
} else if (matches.length == 0) {
errors.add(new IOException("Input Pattern " + p + " matches 0 files"));
} else {
for (FileStatus globStat: matches) {
if (globStat.isDirectory()) {
RemoteIterator<LocatedFileStatus> iter =
fs.listLocatedStatus(globStat.getPath());
while (iter.hasNext()) {
LocatedFileStatus stat = iter.next();
if (inputFilter.accept(stat.getPath())) {
if (recursive && stat.isDirectory()) {
addInputPathRecursively(result, fs, stat.getPath(),
inputFilter);
} else {
result.add(stat);
}
}
}
} else {
result.add(globStat);
}
}
}
} if (!errors.isEmpty()) {
throw new InvalidInputException(errors);
}
return result;
} /**
* Add files in the input path recursively into the results.
* @param result
* The List to store all files.
* @param fs
* The FileSystem.
* @param path
* The input path.
* @param inputFilter
* The input filter that can be used to filter files/dirs.
* @throws IOException
*/
protected void addInputPathRecursively(List<FileStatus> result,
FileSystem fs, Path path, PathFilter inputFilter)
throws IOException {
RemoteIterator<LocatedFileStatus> iter = fs.listLocatedStatus(path);
while (iter.hasNext()) {
LocatedFileStatus stat = iter.next();
if (inputFilter.accept(stat.getPath())) {
if (stat.isDirectory()) {
addInputPathRecursively(result, fs, stat.getPath(), inputFilter);
} else {
result.add(stat);
}
}
}
} /**
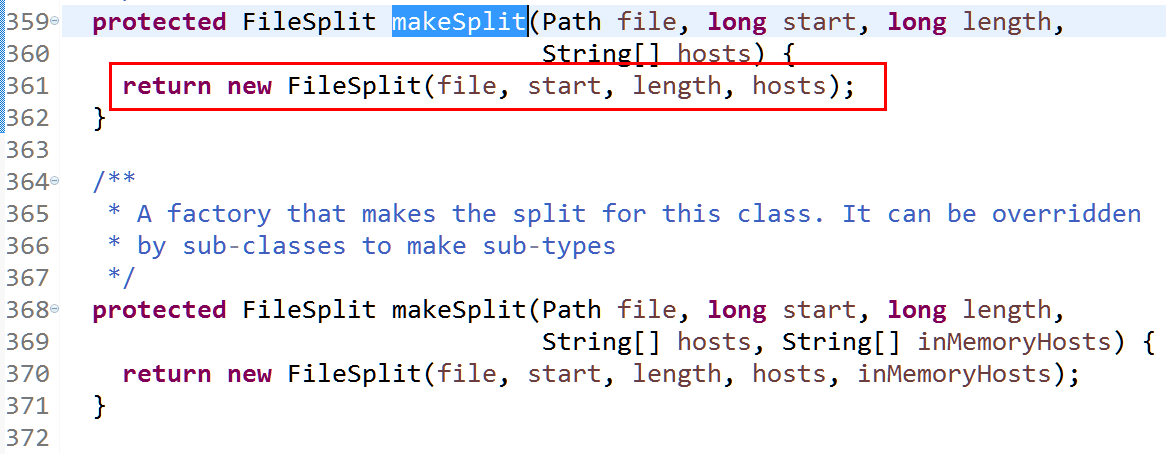
* A factory that makes the split for this class. It can be overridden
* by sub-classes to make sub-types
*/
protected FileSplit makeSplit(Path file, long start, long length,
String[] hosts) {
return new FileSplit(file, start, length, hosts);
} /**
* A factory that makes the split for this class. It can be overridden
* by sub-classes to make sub-types
*/
protected FileSplit makeSplit(Path file, long start, long length,
String[] hosts, String[] inMemoryHosts) {
return new FileSplit(file, start, length, hosts, inMemoryHosts);
} /**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job); // generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize); long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
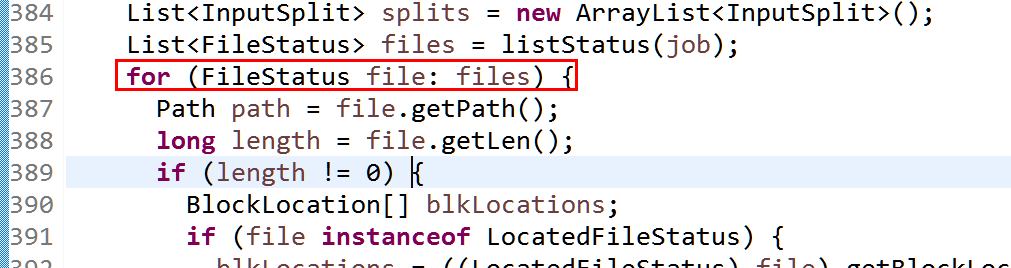
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
} if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
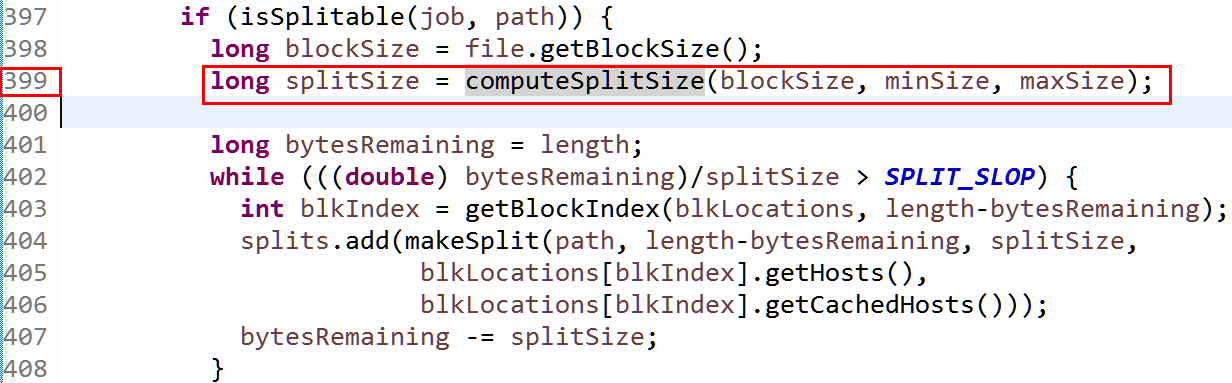
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
} protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
} protected int getBlockIndex(BlockLocation[] blkLocations,
long offset) {
for (int i = 0 ; i < blkLocations.length; i++) {
// is the offset inside this block?
if ((blkLocations[i].getOffset() <= offset) &&
(offset < blkLocations[i].getOffset() + blkLocations[i].getLength())){
return i;
}
}
BlockLocation last = blkLocations[blkLocations.length -1];
long fileLength = last.getOffset() + last.getLength() -1;
throw new IllegalArgumentException("Offset " + offset +
" is outside of file (0.." +
fileLength + ")");
} /**
* Sets the given comma separated paths as the list of inputs
* for the map-reduce job.
*
* @param job the job
* @param commaSeparatedPaths Comma separated paths to be set as
* the list of inputs for the map-reduce job.
*/
public static void setInputPaths(Job job,
String commaSeparatedPaths
) throws IOException {
setInputPaths(job, StringUtils.stringToPath(
getPathStrings(commaSeparatedPaths)));
} /**
* Add the given comma separated paths to the list of inputs for
* the map-reduce job.
*
* @param job The job to modify
* @param commaSeparatedPaths Comma separated paths to be added to
* the list of inputs for the map-reduce job.
*/
public static void addInputPaths(Job job,
String commaSeparatedPaths
) throws IOException {
for (String str : getPathStrings(commaSeparatedPaths)) {
addInputPath(job, new Path(str));
}
} /**
* Set the array of {@link Path}s as the list of inputs
* for the map-reduce job.
*
* @param job The job to modify
* @param inputPaths the {@link Path}s of the input directories/files
* for the map-reduce job.
*/
public static void setInputPaths(Job job,
Path... inputPaths) throws IOException {
Configuration conf = job.getConfiguration();
Path path = inputPaths[0].getFileSystem(conf).makeQualified(inputPaths[0]);
StringBuffer str = new StringBuffer(StringUtils.escapeString(path.toString()));
for(int i = 1; i < inputPaths.length;i++) {
str.append(StringUtils.COMMA_STR);
path = inputPaths[i].getFileSystem(conf).makeQualified(inputPaths[i]);
str.append(StringUtils.escapeString(path.toString()));
}
conf.set(INPUT_DIR, str.toString());
} /**
* Add a {@link Path} to the list of inputs for the map-reduce job.
*
* @param job The {@link Job} to modify
* @param path {@link Path} to be added to the list of inputs for
* the map-reduce job.
*/
public static void addInputPath(Job job,
Path path) throws IOException {
Configuration conf = job.getConfiguration();
path = path.getFileSystem(conf).makeQualified(path);
String dirStr = StringUtils.escapeString(path.toString());
String dirs = conf.get(INPUT_DIR);
conf.set(INPUT_DIR, dirs == null ? dirStr : dirs + "," + dirStr);
} // This method escapes commas in the glob pattern of the given paths.
private static String[] getPathStrings(String commaSeparatedPaths) {
int length = commaSeparatedPaths.length();
int curlyOpen = 0;
int pathStart = 0;
boolean globPattern = false;
List<String> pathStrings = new ArrayList<String>(); for (int i=0; i<length; i++) {
char ch = commaSeparatedPaths.charAt(i);
switch(ch) {
case '{' : {
curlyOpen++;
if (!globPattern) {
globPattern = true;
}
break;
}
case '}' : {
curlyOpen--;
if (curlyOpen == 0 && globPattern) {
globPattern = false;
}
break;
}
case ',' : {
if (!globPattern) {
pathStrings.add(commaSeparatedPaths.substring(pathStart, i));
pathStart = i + 1 ;
}
break;
}
default:
continue; // nothing special to do for this character
}
}
pathStrings.add(commaSeparatedPaths.substring(pathStart, length)); return pathStrings.toArray(new String[0]);
} /**
* Get the list of input {@link Path}s for the map-reduce job.
*
* @param context The job
* @return the list of input {@link Path}s for the map-reduce job.
*/
public static Path[] getInputPaths(JobContext context) {
String dirs = context.getConfiguration().get(INPUT_DIR, "");
String [] list = StringUtils.split(dirs);
Path[] result = new Path[list.length];
for (int i = 0; i < list.length; i++) {
result[i] = new Path(StringUtils.unEscapeString(list[i]));
}
return result;
} }
FileInputFormat
父类
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.hadoop.mapreduce; import java.io.IOException;
import java.util.List; import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; /**
* <code>InputFormat</code> describes the input-specification for a
* Map-Reduce job.
*
* <p>The Map-Reduce framework relies on the <code>InputFormat</code> of the
* job to:<p>
* <ol>
* <li>
* Validate the input-specification of the job.
* <li>
* Split-up the input file(s) into logical {@link InputSplit}s, each of
* which is then assigned to an individual {@link Mapper}.
* </li>
* <li>
* Provide the {@link RecordReader} implementation to be used to glean
* input records from the logical <code>InputSplit</code> for processing by
* the {@link Mapper}.
* </li>
* </ol>
*
* <p>The default behavior of file-based {@link InputFormat}s, typically
* sub-classes of {@link FileInputFormat}, is to split the
* input into <i>logical</i> {@link InputSplit}s based on the total size, in
* bytes, of the input files. However, the {@link FileSystem} blocksize of
* the input files is treated as an upper bound for input splits. A lower bound
* on the split size can be set via
* <a href="{@docRoot}/../hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml#mapreduce.input.fileinputformat.split.minsize">
* mapreduce.input.fileinputformat.split.minsize</a>.</p>
*
* <p>Clearly, logical splits based on input-size is insufficient for many
* applications since record boundaries are to respected. In such cases, the
* application has to also implement a {@link RecordReader} on whom lies the
* responsibility to respect record-boundaries and present a record-oriented
* view of the logical <code>InputSplit</code> to the individual task.
*
* @see InputSplit
* @see RecordReader
* @see FileInputFormat
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class InputFormat<K, V> { /**
* Logically split the set of input files for the job.
*
* <p>Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.</p>
*
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple. The InputFormat
* also creates the {@link RecordReader} to read the {@link InputSplit}.
*
* @param context job configuration.
* @return an array of {@link InputSplit}s for the job.
*/
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException; /**
* Create a record reader for a given split. The framework will call
* {@link RecordReader#initialize(InputSplit, TaskAttemptContext)} before
* the split is used.
* @param split the split to be read
* @param context the information about the task
* @return a new record reader
* @throws IOException
* @throws InterruptedException
*/
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException; }
InputFormat源码
* <p>Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.</p>
*
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple. The InputFormat
* also creates the {@link RecordReader} to read the {@link InputSplit}.
*
* @param context job configuration.
* @return an array of {@link InputSplit}s for the job.
*/
public abstract
List<InputSplit> getSplits(JobContext context
) throws IOException, InterruptedException;
意思是:每一个文件逻辑上切分成若干个split(由getsplit方法),一个split对应一个mapper任务
/**
* Create a record reader for a given split. The framework will call
* {@link RecordReader#initialize(InputSplit, TaskAttemptContext)} before
* the split is used.
* @param split the split to be read
* @param context the information about the task
* @return a new record reader
* @throws IOException
* @throws InterruptedException
*/
public abstract
RecordReader<K,V> createRecordReader(InputSplit split,
TaskAttemptContext context
) throws IOException,
InterruptedException; }
意思是:split本质上是文件内容一部分,由RecordReader来处理文件内容(键值对),进入RecordReader查看,可得该抽象类将data数据拆分成键值对,目的是输入给Mapper
/**
* The record reader breaks the data into key/value pairs for input to the
* {@link Mapper}.
* @param <KEYIN>
* @param <VALUEIN>
*/
public abstract class RecordReader<KEYIN, VALUEIN> implements Closeable {
/**
* Called once at initialization.
* @param split the split that defines the range of records to read
* @param context the information about the task
* @throws IOException
* @throws InterruptedException
*/
由此总结,源码分析的
文件-----------通过----------->getsplits()-----------分解为------------>InputSplit------------通过-------------->RecordReader类(由createRecordReader()方法创建的)-------处理---------->map(k1,v1)
第一部分:文件切分
问题1:如何将文件切分成split,查看自雷的getsplits()方法
/**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job); // generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize); long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
} if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
}
getSplits
/**
* Generate the list of files and make them into FileSplits.
将文件切分成split
* @param job the job context
* @throws IOException
*/
(1) 通过add方法将切片加入列表

(2)add方法中通过makesplit方法实现逻辑块的切分

(3)makeSplit内部使用FileSplit进行文件切分
(4)FileSplit三个参数的意义如下
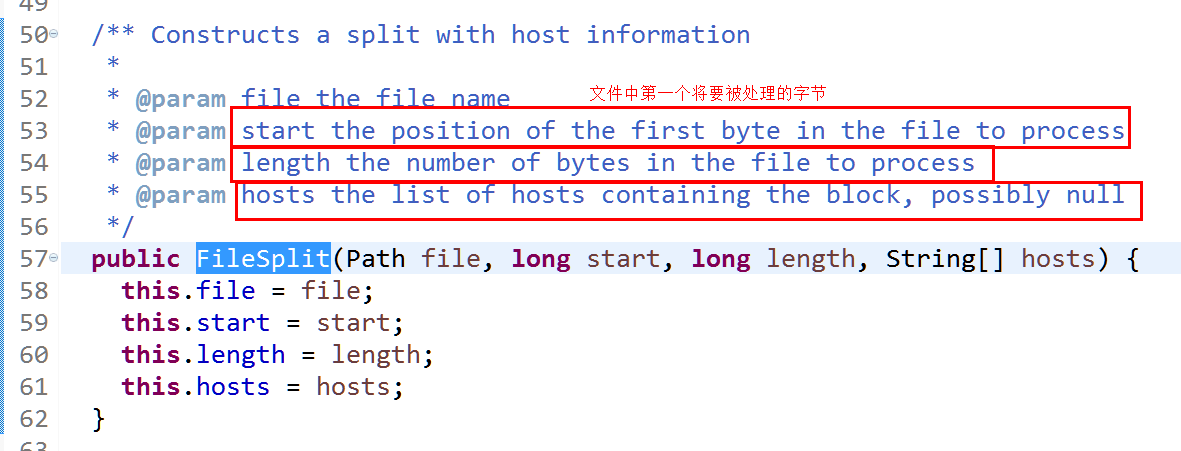
hosts值得是包含块的节点列表,即block块。从start开始处理,处理多长length,处理的数据信息位于那个block块上,因此Split是逻辑切分
没有真正切分,如此对程序的影响,不会真正去读磁盘数据,而是使用HDFS读数据方法。
(5)分析文件长度不为0程序如何执行
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) { //如果文件被切分,并非所有文件 都可以切分,比如密码文件,通常有文件结构决定是否可以被切分
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize, //length-bytesRemaining为剩余字节
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize; }
- 如果文件大小300,length=300,bytesRemaining=300
- 执行第一次makesplit(0,128) 按splitSize=128切分
- bytesRemaining=300-128=172
- 执行第二次makesplit(300-172=128,128)
- bytesRemaining=172-128=44
- 执行第三次makesplit(300-44=256,128)
文件不允许被分割,执行以下程序
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
(6)分析文件块大小
380 long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); //结果分析为1L
381 long maxSize = getMaxSplitSize(job);//最大为Long的最大值
查看變量minsize的源代碼
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
点击getFormatMinSplitSize()查看,为1L
/**
* Get the lower bound on split size imposed by the format.
* @return the number of bytes of the minimal split for this format
*/
protected long getFormatMinSplitSize() {
return 1;
}
点击getMinSplitSize()查看,计算办法为返回当前文件块的最小尺寸,如果配置文件中没有SPLIT_MINSIZE参数则返回1L
/**
* Get the minimum split size
* @param job the job
* @return the minimum number of bytes that can be in a split
*/
public static long getMinSplitSize(JobContext job) {
return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L);
}
从而得到minsplit最小值为1L
而真正计算block是在399行,默认情况下inputsplit和block的大小均为128M,换句话说,一个map处理数据块的大小是一个block块大小
397 if (isSplitable(job, path)) {
398 long blockSize = file.getBlockSize();
399 long splitSize = computeSplitSize(blockSize, minSize, maxSize);
当inputsplit和block的大小不同的时候,就会产生网络传输,如果inputsplit比block大,则inputsplit所需的是一个block块是不够的的,必须在找一个block块。
如果inputsplit比block小,block块中得一部分数据是没有被处理的,可能被别的map处理,也就可鞥产生网络传输,也是一种数据本地化的。
因为源码中使用的是for循环,因此,没一个文件都会去切分split
(7)两个50M,一个200M的文件和一个空文件会产生几个split
空白文件也会产生split,两个50M产生两个split,一个200M产生2个split,共需要5个map任务
**********************************************************
第二部分 通过createRecordReader()处理map任务
(1)解读createRecordReader
/** An {@link InputFormat} for plain text files. Files are broken into lines.
* Either linefeed or carriage-return are used to signal end of line. Keys are
* the position in the file, and values are the line of text.. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);//delimiter为分隔符,编码格式为utf-8,在解析的时候如果不是这个格式将会出错
return new LineRecordReader(recordDelimiterBytes); }
LineRecordReader为RecordReader的子类
/**
* Treats keys as offset in file and value as line. key为偏移量,value为每一行的值
*/
@InterfaceAudience.LimitedPrivate({"MapReduce", "Pig"})
@InterfaceStability.Evolving
public class LineRecordReader extends RecordReader<LongWritable, Text> {
private static final Log LOG = LogFactory.getLog(LineRecordReader.class);
public static final String MAX_LINE_LENGTH =
"mapreduce.input.linerecordreader.line.maxlength"; private long start;
private long pos;
private long end;
RecordReader类
/**
* Called once at initialization.
* @param split the split that defines the range of records to read
* @param context the information about the task
* @throws IOException
* @throws InterruptedException
*/
public abstract void initialize(InputSplit split, //初始化,执行一次
TaskAttemptContext context
) throws IOException, InterruptedException; /**
* Read the next key, value pair.
* @return true if a key/value pair was read
* @throws IOException
* @throws InterruptedException
*/
public abstract //读取下一个键值对 这个键值对是map端的k1和v1
boolean nextKeyValue() throws IOException, InterruptedException; /**
* Get the current key //得到key值
* @return the current key or null if there is no current key
* @throws IOException
* @throws InterruptedException
*/
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException; /**
* Get the current value.
* @return the object that was read
* @throws IOException
* @throws InterruptedException
*/
public abstract
VALUEIN getCurrentValue() throws IOException, InterruptedException; /**
* The current progress of the record reader through its data.
* @return a number between 0.0 and 1.0 that is the fraction of the data read
* @throws IOException
* @throws InterruptedException
*/
public abstract float getProgress() throws IOException, InterruptedException; /**
* Close the record reader.
*/
public abstract void close() throws IOException;
}
上述没有key和value的值,这是需要注意的,下面却提供了key和value的get方法,因此key和value在类的字段中存放,
在方法体中对key和value赋值,然后再利用getCurrentkey和getCurrentValue获得key和value。
比如:while(rs.next()){rs.getLong()}
Enumeration里面有一个hasMoreElement()方法也是上述情况,hashtable方法,用element做迭代,最后归结到Enumeration
因此上述程序可理解为:
while(rr.nextKeyValue()){key=rr.getCurrentKey(),value=rr.getCurrentValue(),map(key,value,context)}
通过源代码可以验证上述猜想,key和value的类型已经固定,因此在mapreduce中可以省略<k1,v1>不写
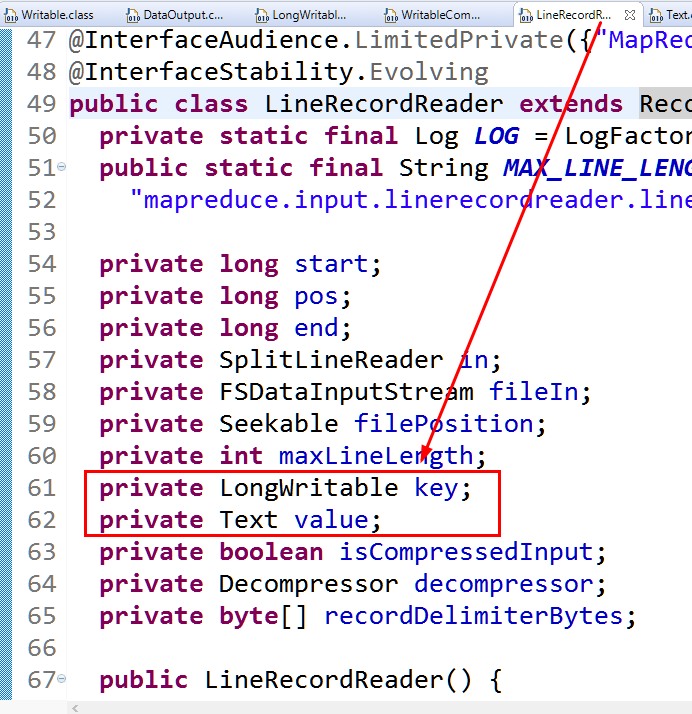
其中SplitLineReader为行读取器。
(2)
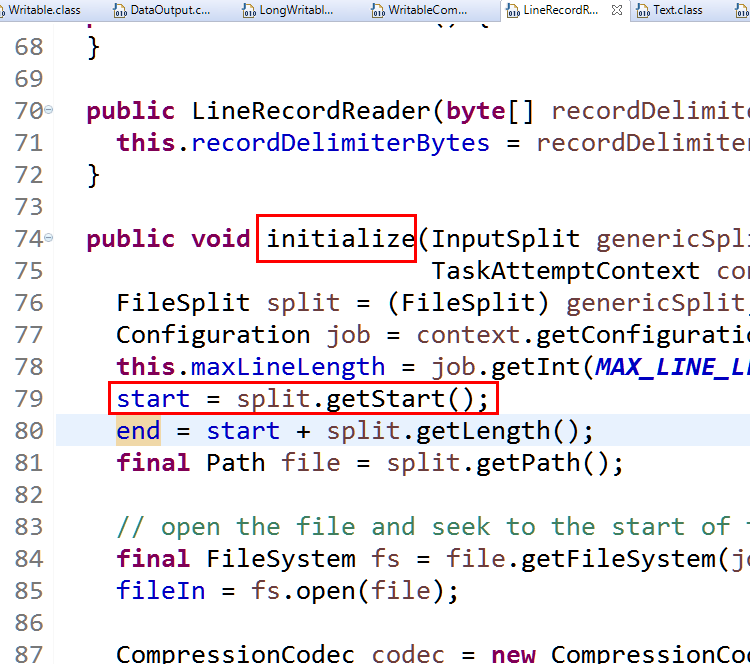
**split.getStart()处理被处理数据的起始位置,和行没有关系
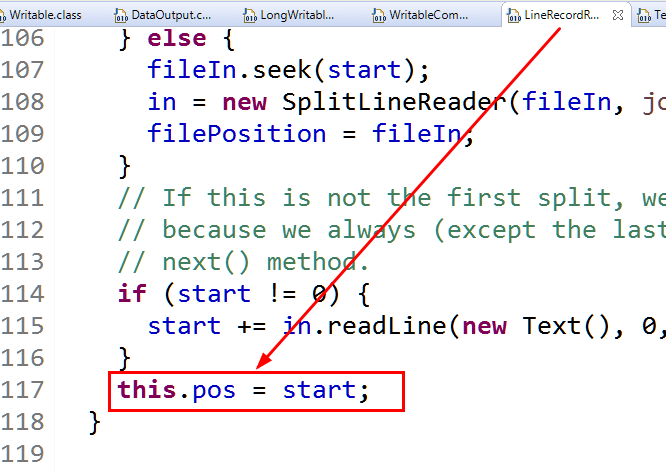
起始位置赋给了pos当前位置,现在查找netKeyVAalue()方法
LineRecordReader类中
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
如:hello you
hello me
上述文件中,会被切分成一个split,在这里
第一次调用nextKeyValue()的时候start=0,value=hello you,end=19,pos=0,key=0,newsize=10
第二次调用nextKeyValue()的时候key=10,value=hello me,newsize=10
由readLine()方法从输入流中读取给定文本,返回值为被读取字节的数量
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));读取一行数据,将数据放入value中,返回值为被读取字节的长度,还包括新行(换行)
总结,key和value的值就是通过nextKeyValue()方法赋值的。
第三部分 当key,value被赋值之后,剩下的问题就是如何被map函数所调用?
*****************************************************************
从map类分析:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.hadoop.mapreduce; import java.io.IOException; import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapreduce.task.MapContextImpl; /**
* Maps input key/value pairs to a set of intermediate key/value pairs.
*
* <p>Maps are the individual tasks which transform input records into a
* intermediate records. The transformed intermediate records need not be of
* the same type as the input records. A given input pair may map to zero or
* many output pairs.</p>
*
* <p>The Hadoop Map-Reduce framework spawns one map task for each
* {@link InputSplit} generated by the {@link InputFormat} for the job.
* <code>Mapper</code> implementations can access the {@link Configuration} for
* the job via the {@link JobContext#getConfiguration()}.
*
* <p>The framework first calls
* {@link #setup(org.apache.hadoop.mapreduce.Mapper.Context)}, followed by
* {@link #map(Object, Object, Context)}
* for each key/value pair in the <code>InputSplit</code>. Finally
* {@link #cleanup(Context)} is called.</p>
*
* <p>All intermediate values associated with a given output key are
* subsequently grouped by the framework, and passed to a {@link Reducer} to
* determine the final output. Users can control the sorting and grouping by
* specifying two key {@link RawComparator} classes.</p>
*
* <p>The <code>Mapper</code> outputs are partitioned per
* <code>Reducer</code>. Users can control which keys (and hence records) go to
* which <code>Reducer</code> by implementing a custom {@link Partitioner}.
*
* <p>Users can optionally specify a <code>combiner</code>, via
* {@link Job#setCombinerClass(Class)}, to perform local aggregation of the
* intermediate outputs, which helps to cut down the amount of data transferred
* from the <code>Mapper</code> to the <code>Reducer</code>.
*
* <p>Applications can specify if and how the intermediate
* outputs are to be compressed and which {@link CompressionCodec}s are to be
* used via the <code>Configuration</code>.</p>
*
* <p>If the job has zero
* reduces then the output of the <code>Mapper</code> is directly written
* to the {@link OutputFormat} without sorting by keys.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class TokenCounterMapper
* extends Mapper<Object, Text, Text, IntWritable>{
*
* private final static IntWritable one = new IntWritable(1);
* private Text word = new Text();
*
* public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
* StringTokenizer itr = new StringTokenizer(value.toString());
* while (itr.hasMoreTokens()) {
* word.set(itr.nextToken());
* context.write(word, one);
* }
* }
* }
* </pre></blockquote></p>
*
* <p>Applications may override the {@link #run(Context)} method to exert
* greater control on map processing e.g. multi-threaded <code>Mapper</code>s
* etc.</p>
*
* @see InputFormat
* @see JobContext
* @see Partitioner
* @see Reducer
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { /**
* The <code>Context</code> passed on to the {@link Mapper} implementations.
*/
public abstract class Context
implements MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
} /**
* Called once at the beginning of the task.任务执行开始调用
*/
protected void setup(Context context
) throws IOException, InterruptedException {
// NOTHING
} /**input split的每一个键值对都调用一次
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
} /**
* Called once at the end of the task.
*/
protected void cleanup(Context context
) throws IOException, InterruptedException {
// NOTHING
} /**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context); 执行一次
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);//一个inputsplit调用一次map函数
}
} finally {
cleanup(context); 执行一次
}
}
}
nextKeyValue()方法查看,
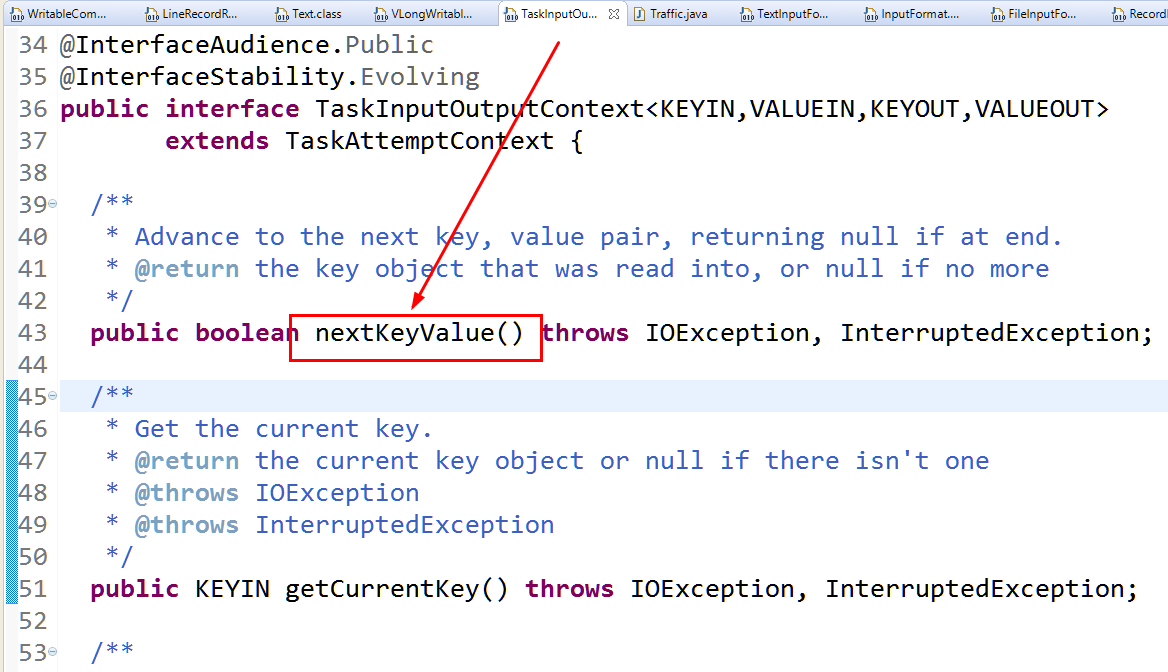
找到nextkeyvalue的实现,ctrl+t也可进入
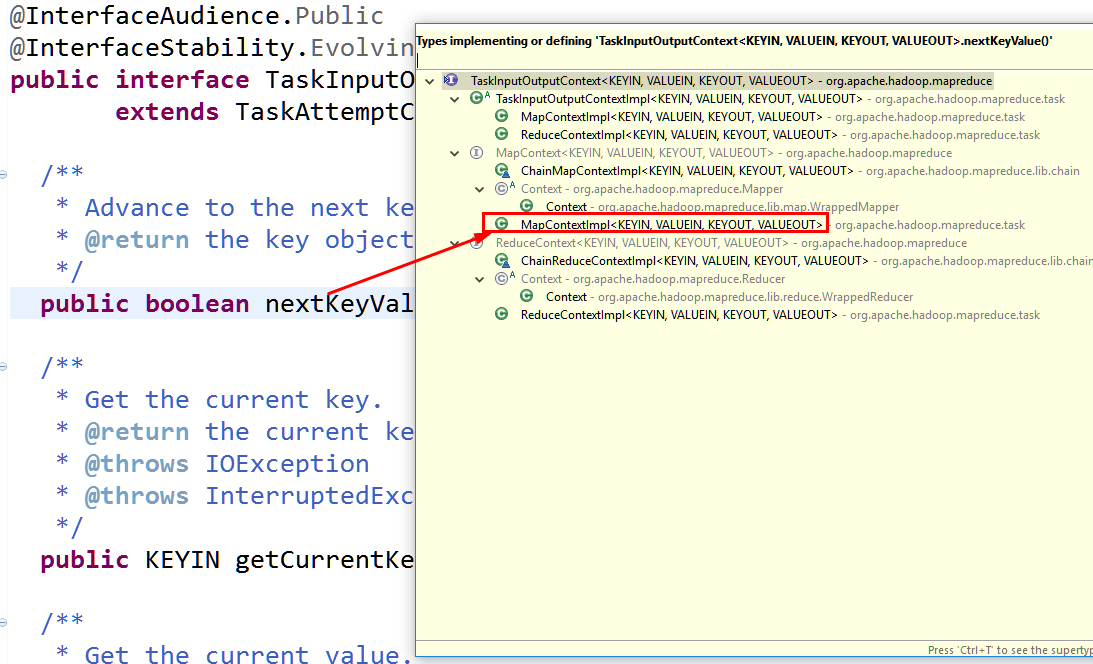
MapContextImpl类下面提供了该类的实现
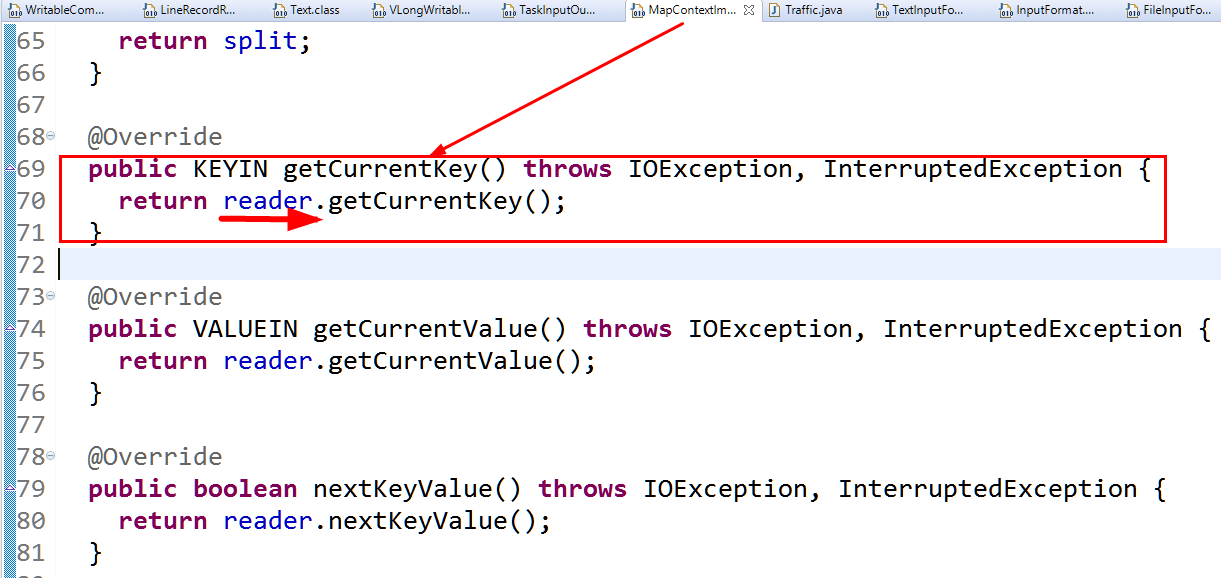
其种reader由RecordReader类提供

另外通过Context源码查看

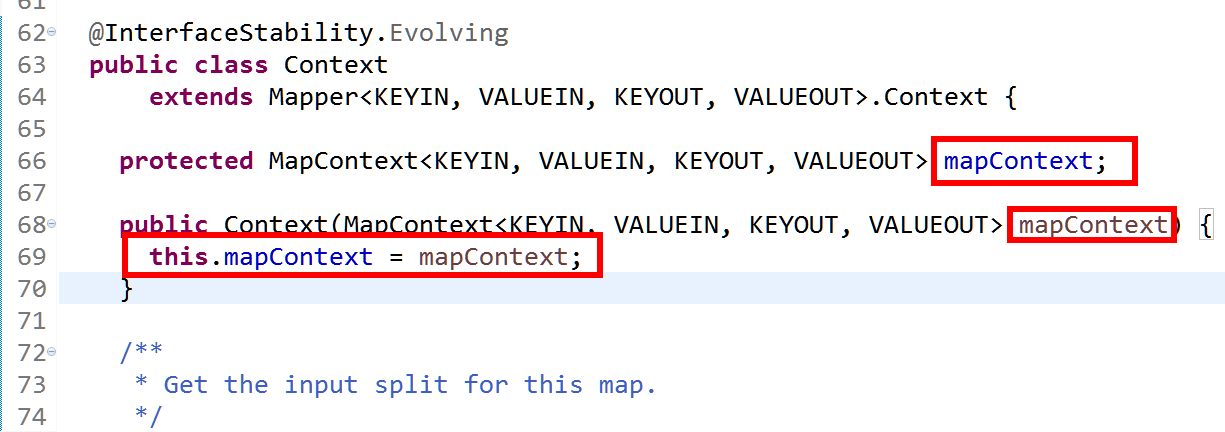
进入该类

研究mapcontext,mapcontext是在构造函数中赋值的
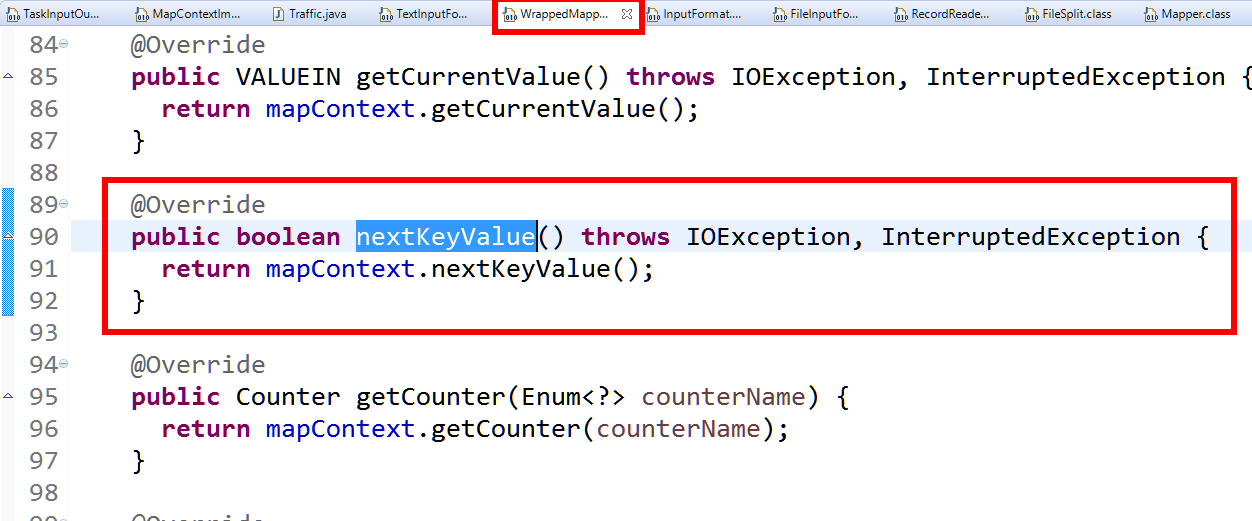
查看WrappedMapper類的nextkeyvalue()方法

通過查看其實現,可以查找其實鮮類
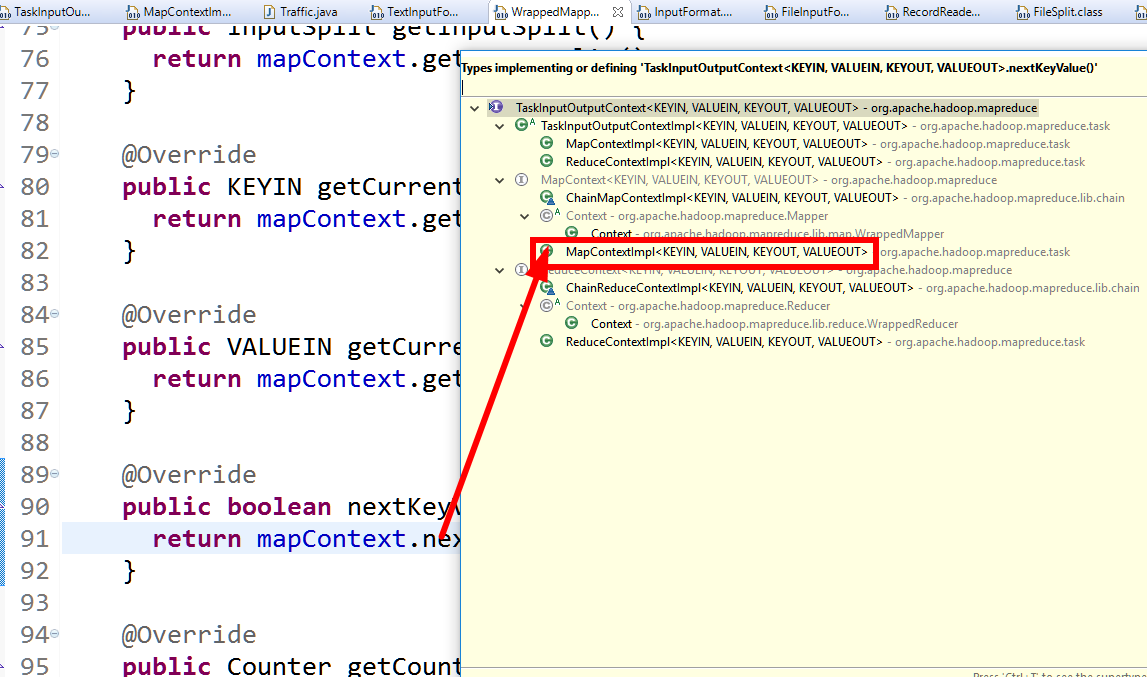
可觀察到以下reader的實現情況

reader最終是有RecordReader來聲明的。
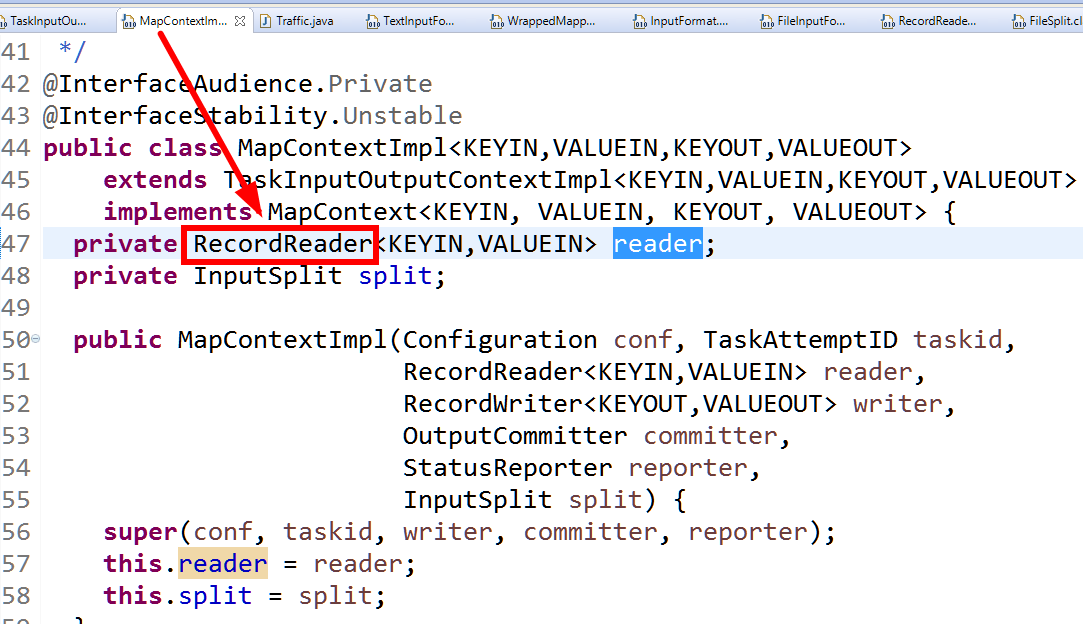
總結:
调用MapContextImpl有参构造方法,然后将RecordReader赋值进去(57行),从而可以调用80行的nextkeyvalue()方法,然后MapContextImpl的父类Context调用nextkeyvalue()
总结:从源代码的角度分析map函数处理的<k1,v1>是如何从HDFS文件中获取的?答:
1.从TextInputFormat入手分析,找到父类FileInputFormat,找到父类InputFormat。
在InputFormat中找到2个方法,分别是getSplits(...)和createRecordReader(...)。
通过注释知道getSplits(...)作用是把输入文件集合中的所有内容解析成一个个的InputSplits,每一个InputSplit对应一个mapper task。
createRecordReader(...)作用是创建一个RecordReader的实现类。RecordReader作用是解析InputSplit产生一个个的<k,v>。
2.在FileInputFormat中找到getSplits(...)的实现。
通过实现,获知
(1)每个SplitSize的大小和默认的block大小一致,好处是满足数据本地性。
(2)每个输入文件都会产生一个InputSplit,即使是空白文件,也会产生InputSPlit;
如果一个文件非常大,那么会按照InputSplit大小,切分产生多个InputSplit。
3.在TextInputFormat中找到createRecordReader(...)的实现,在方法中找到了LineRecordReader。
接下来分析LineRecordReader类。
在RecordReader类中,通过查看多个方法,知晓key、value作为类的属性存在的,且知道了nextKeyValue()方法的用法。
在LineRecordReader类中,重点分析了nextKeyValue(...)方法。在这个方法中,重点分析了newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
在in.readLine(...)中,第一个形参存储被读取的行文本内容,返回值表示被读取内容的字节数。
通过以上代码,分析了InputSplit中的内容是如何转化为一个个的<k,v>。
4.从Mapper类中进行分析,发现了setup()、cleanup()、map()、run()。
在run()方法中,通过while,调用context.nextKeyValue(...)。
进一步分析Context的接口类是org.apache.hadoop.mapreduce.lib.map.WrappedMapper.MapContext,MapContext调用了nextKeyValue(...)。最终找到了MapContext的实现了MapContextImpl类org.apache.hadoop.mapreduce.task.MapContextImpl。
在这个类的构造方法中,发现传入了RecordReader的实现类。
MapReduce部分源码解读(一)的更多相关文章
- [Hadoop源码解读](六)MapReduce篇之MapTask类
MapTask类继承于Task类,它最主要的方法就是run(),用来执行这个Map任务. run()首先设置一个TaskReporter并启动,然后调用JobConf的getUseNewAPI()判断 ...
- 2,MapReduce原理及源码解读
MapReduce原理及源码解读 目录 MapReduce原理及源码解读 一.分片 灵魂拷问:为什么要分片? 1.1 对谁分片 1.2 长度是否为0 1.3 是否可以分片 1.4 分片的大小 1.5 ...
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读 之 SDWebImageCompat
第三篇 前言 本篇主要解读SDWebImage的配置文件.正如compat的定义,该配置文件主要是兼容Apple的其他设备.也许我们真实的开发平台只有一个,但考虑各个平台的兼容性,对于框架有着很重要的 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
随机推荐
- [web] spring boot 整合MyBatis
1.maven依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="h ...
- 如何重新排列数组使得数组左边为奇数,右边为偶数,并使得空间复杂度为O(1),时间复杂度为O(n)
思路分析: 类似快速排序的处理.可以用两个指针分别指向数组的头和尾,头指针正向遍历数组,找到第一个偶数,尾指针逆向遍历数组,找到第一个奇数,使用引用参数传值交换两个指针指向的数字,然后两指针沿着相应的 ...
- Nginx配置中文域名
今天碰到一个好玩的问题,还以为是nginx的缓存,各种清理就差把nginx卸载了,后来想想不对应该是中文域名的问题,对中文进行编码,搞定,如下: ... server { listen 80; ser ...
- zabbix添加对tomcat线程池的监控
在zabbix模板中添加以下监控项: 可以参考文档:http://www.fblinux.com/?p=616
- iOS开发-编译出错 duplicate symbols for architecture x86_64
今天对原来项目文件进行重新整理,根据文件内容进行分类,结果复制粘贴时没注意把一个文件复制了两遍 编译的时候就出现Duplicate Symbol Error 在网上搜素了一圈发现也有人遇到过这个问题, ...
- Django 添加应用
一个项目可以添加多个应用,可以使用以下两种方法来添加应用: [root@localhost web]$ python manage.py startapp blog [root@localhost w ...
- JavaWeb学习总结(十六)Cookie保存中文内容
Cookie的值保存中文内容,可以使用Java.net.URLDecoder进行解码. 示例: <%@page import="java.net.URLDecoder"%&g ...
- Excel 导入遍历
package com.founder.ec.cms.service.impl; import com.founder.ec.cms.service.ProductListImportService; ...
- transformClassesWithJarMergingForDebug
Error:Execution failed for task ':app:transformClassesWithJarMergingForDebug'.> com.android.build ...
- [转]redis的三种启动方式
来源:https://www.cnblogs.com/pqchao/p/6549510.html redis的启动方式1.直接启动 进入redis根目录,执行命令: #加上‘&’号使red ...