Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力。Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立集群管理器)上运行,所以Spark应用既能够适应专用集群,又能用于共享的云计算环境。
- Spark运行时架构
Spark在分布式环境中的架构如下图:
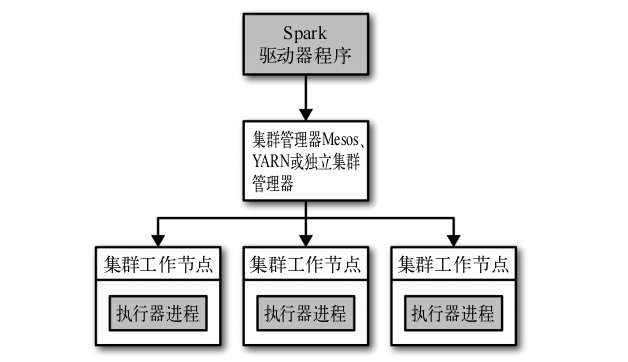
在分布式环境下,Spark集群采用的是主/从结构。在Spark集群,驱动器节点负责中央协调,调度各个分布式工作节点。执行器节点是工作节点,作为独立的Java进行运行,可以和大量的执行器节点进行通信,作为独立的Java进程运行。驱动器节点和所有的执行器节点一起被称为一个Spark应用。
Spark应用通过一个叫做集群管理器的外部服务在集群上的机器上启动。Spark自动的集群管理器称为独立集群管理器。Spark也能运行在Hadoop YARN和Apache Mesos两大开源集群管理器上。
详细说明驱动器节点和执行器节点的作用:
1、驱动器节点
Spark驱动器是执行程序中main()方法的进程。它执行用户编写的用来创建SparkContext ,创建RDD,以及进行RDD转化操作和行动操作的代码。
驱动器进程在Spark应用中有以下两个职责:
- 把用户程序转为任务
Spark驱动器程序负责把用户程序转为多个物理执行的单元,这些单元称为任务。任务是Spark中最小的工作单元,用户程序通常要启动成百上千的独立任务。
- 为执行器节点调度任务
Spark驱动器在各执行器进程间协调任务的调度,驱动器进程对应用中所有的执行器节点有完整的记录。每个执行器节点代表一个能够处理任务和存储RDD数据的进程。
2、执行器节点
Spark执行器节点是一种工作进程,负责在Spark作业中运行任务,任务间相互独立。执行器节点在Spark应用启动时启动,伴随着整个Spark应用的生命周期而存在。
执行器节点负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
执行器节点通过自身的块管理器为用户程序中要求缓存的RDD提供内存式存储。
- spark-submit部署应用
使用Spark提供的统一脚本spark-submit将应用提交到集群管理器上。
spark-submit提供了各种选项可以控制应用每次运行的各项细节。这些选项分为两类:第一类是调度信息,比如你希望为作业申请的资源量。第二类是应用的运行时依赖,比如需要部署到所有工作节点的库和文件。
spark-submit的一般格式:
bin/spark-submit [options] <app jar | python file> [app options]
[options]是要传给spark-submit的标记列表,运行spark-submit --help 可以列出所有可以接收的标记。
<app jar | python file>表示包含应用入口的JAR包或Python脚本。
[app options]是传给应用的选项。
spark-submit一些常用的标记如下:

- 使用Maven依赖
<properties>
<scala.version>2.10.4</scala.version>
<spark.version>1.6.3</spark.version>
<hadoop.version>2.6.0</hadoop.version>
</properties> <dependencies>
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency> <!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <!-- hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency> <!-- JDBC -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
</dependencies>
- Spark应用内与应用间调度
在调度多用户集群时,Spark主要依赖集群管理器来在Saprk应用间共享资源。Spark内部的公平调度器会让长期运行的应用定义调度任务的优先级队列。
Spark学习笔记5:Spark集群架构的更多相关文章
- Redis学习笔记八:集群模式
作者:Grey 原文地址:Redis学习笔记八:集群模式 前面提到的Redis学习笔记七:主从复制和哨兵只能解决Redis的单点压力大和单点故障问题,接下来要讲的Redis Cluster模式,主要是 ...
- ZooKeeper学习笔记一:集群搭建
作者:Grey 原文地址:ZooKeeper学习笔记一:集群搭建 说明 单机版的zk安装和运行参考:https://zookeeper.apache.org/doc/r3.6.3/zookeeperS ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- rabbitmq系统学习(三)集群架构
RabbitMQ集群架构模式 主备模式 实现RabbitMQ的高可用集群,一般在并发和数据量不高的情况下,这种模型非常的好用且简单.主备模式也称为Warren模式 HaProxy配置 listen r ...
- spark学习1(hadoop集群搭建)
把原先搭建的集群环境给删除了,自己重新搭建了一次,将笔记整理在这里,方便自己以后查看 第一步:安装主节点spark1 第一个节点:centos虚拟机安装,全名spark1,用户名hadoop,密码12 ...
- spark学习5(hbase集群搭建)
第一步:Hbase安装 hadoop,zookeeper前面都安装好了 将hbase-1.1.3-bin.tar.gz上传到/usr/HBase目录下 [root@spark1 HBase]# chm ...
- redis 学习笔记(6)-cluster集群搭建
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞shardi ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- 开源流媒体服务器SRS学习笔记(4) - Cluster集群方案
单台服务器做直播,总归有单点风险,利用SRS的Forward机制 + Edge Server设计,可以很容易搭建一个大规模的高可用集群,示意图如下 源站服务器集群:origin server clus ...
随机推荐
- C# 历史曲线控件 基于时间的曲线控件 可交互的高级曲线控件 HslControls曲线控件使用教程
本篇博客主要对 HslControls 中的曲线控件做一个详细的教程说明,大家可以根据下面的教程开发出高质量的曲线控件 Prepare 先从nuget下载到组件,然后就可以使用组件里的各种组件信息了. ...
- Java中生产者与消费者模式
生产者消费者模式 首先来了解什么是生产者消费者模式.该模式也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例.该问题描述了两个共享固定大小缓冲区的线 ...
- tensorflow中的参数初始化方法
1. 初始化为常量 tf中使用tf.constant_initializer(value)类生成一个初始值为常量value的tensor对象. constant_initializer类的构造函数定义 ...
- paho.mqtt.embedded-c MQTTPacket pub0sub1.c hacking
/******************************************************************************* * paho.mqtt.embedde ...
- FZU OJ:2230 翻翻棋
Problem 2230 翻翻棋 Accept: 872 Submit: 2132Time Limit: 1000 mSec Memory Limit : 32768 KB Proble ...
- PAT 团体程序设计天梯赛 L1-046 整除光棍(模拟除法)
L1-046. 整除光棍 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 翁恺 这里所谓的"光棍",并不是指单身汪 ...
- CH4101 银河英雄传说
题意 4101 银河英雄传说 0x40「数据结构进阶」例题 描述 公元五八○一年,地球居民迁移至金牛座α第二行星,在那里发表银河联邦创立宣言,同年改元为宇宙历元年,并开始向银河系深处拓展. 宇宙历七 ...
- JS常用功能
1.字符串转Json var json='[{"id":0,"text":"ddddd"},{"id":1," ...
- day36 python学习gevent io 多路复用 socketserver *****
---恢复内容开始--- gevent 1.切换+保存状态 2.检测单线程下任务的IO,实现遇到IO自动切换 Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在geven ...
- sprintf拼接字符串的问题
] = {}; char a1[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G'}; char a2[] = {'H', 'I', 'J', 'K', 'L', 'M', ...