twitter storm源码走读之4 -- worker进程中线程的分类及用途
欢迎转载,转载请注明出版,徽沪一郎。
本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程。
概述
worker进程启动过程中最重要的两个函数是mk-worker和worker-data,代码就不一一列出了。worker顺利启动之后会拥有如下图所示的各类线程。
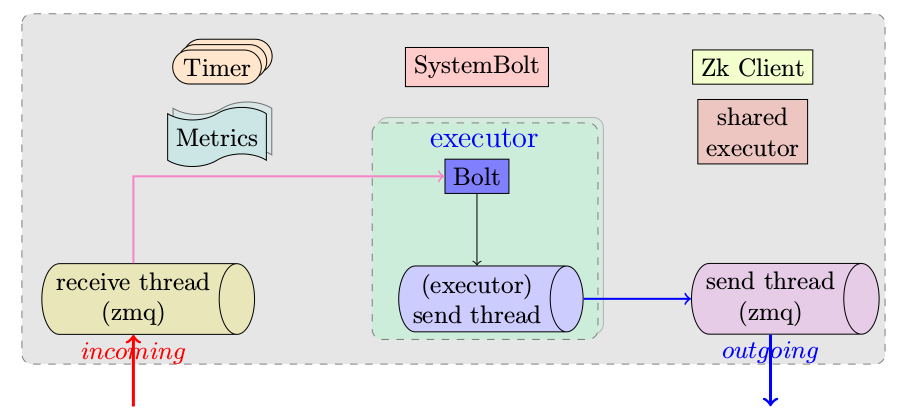
接收和发送线程
worker在启动的时候会生成进程级别的消息接收和消息发送线程,它们视具体配置而定,可以是基于zmq,也可以基于netty,这个没有太多好说的。socket connection的建立过程可以在tuple消息传递一文中找到说明。
zk client
worker需要定期的向zk server发送心跳消息,与zk server之间的连接处理就落到zk client这个线程身上了。具体代码见函数do-heartbeat及do-executor-heartbeats。
定时器线程
worker进程需要定期的做些事情,比如发送心跳消息,刷新socket连接,这些定时器归为如下几类,每类定时器运行在各自的线程。
- :heartbeat-timer worker
- :refresh-connections-timer worker
- :refresh-active-timer worker
- :executor-heartbeat-timer worker
- :user-timer worker
上述定时器分类见于worker的shutdown函数,有时候在分析代码的时候,如果从入口看不清楚的话,不妨试试从退出的处理逻辑哪里找找答案。
SystemBolt
在topology提交的时候曾经见过函数system-topology!,这个函数会创建SystemBolt,每个worker内有且只有一个SystemBolt,可以见SystemBolt.java中注释的说明或参考github上storm对该改变的说明,https://github.com/nathanmarz/storm/pull/517。
SystemBolt主要进行进程相关的统计功能,比如内存使用情况,网络包的吞吐量,具体可见SystemBolt.java。SystemBolt是不接收tuple,只有出度,没有入度。
Metrics Bolt线程
MetricsBolt主要也是处理统计工作,与systembolt不同的是,metricsbolt主要处理executor级别的,如果用户在配置文件中定义了相关的MetricsConsumer类,那么这些类会在此被执行。
与之相关的配置内容,
## Metrics Consumers
# topology.metrics.consumer.register:
# - class: "backtype.storm.metrics.LoggingMetricsConsumer"
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"
Shared Executor
这个是在storm 0.8中引入的,其用途可在0.8的release notes中找到,创建共享线程池,具体用途没太搞清楚,:).
Metrics的执行流程
metrics所做的计量工作是在什么时候被唤醒的呢,也就是说如何一步步的触发直到MetricsConsumeBolt的execute函数被调用。
下图勾勒出与metrics相关的线程间的消息传递过程。

简要说明如下
- worker在启动的时候,会往:user-timer中注册metrics timer(见setup-metrics!函数).
- 一旦metrics timer超时,会发送一个stream-id为metrics-tick-stream-id的tuple到非metrics类型的bolt,如user/acker/system bolt.
- 接收到tuple之后,会调用metrics-tick函数发送task-data给MetricsConsumerBolt, stream-id为metrics-stream-id
- MetricsConsumerBolt接收到stream-id为metrics-stream-id的tuple后,会执行execute
注:在worker内部还有另一套计量api,定义于builtin-metrics.clj中,与MetricsConsumerBolt的区别在于,builtin-metrics是在处理外部进程发送过来的tuple时进行计量统计,而MetricsConsumerBolt是定时触发。
twitter storm源码走读之4 -- worker进程中线程的分类及用途的更多相关文章
- twitter storm 源码走读之5 -- worker进程内部消息传递处理和数据结构分析
欢迎转载,转载请注明出处,徽沪一郎. 本文从外部消息在worker进程内部的转化,传递及处理过程入手,一步步分析在worker-data中的数据项存在的原因和意义.试图从代码实现的角度来回答,如果是从 ...
- worker进程中线程的分类及用途
worker进程中线程的分类及用途 欢迎转载,转载请注明出版,徽沪一郎. 本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程. ...
- twitter storm源码走读之2 -- tuple消息发送场景分析
欢迎转载,转载请注明出处源自徽沪一郎.本文尝试分析tuple发送时的具体细节,本博的另一篇文章<bolt消息传递路径之源码解读>主要从消息接收方面来阐述问题,两篇文章互为补充. worke ...
- twitter storm源码走读之3--topology提交过程分析
概要 storm cluster可以想像成为一个工厂,nimbus主要负责从外部接收订单和任务分配.除了从外部接单,nimbus还要将这些外部订单转换成为内部工作分配,这个时候nimbus充当了调度室 ...
- twitter storm源码走读之1 -- nimbus启动场景分析
欢迎转载,转载时请注明作者徽沪一郎及出处,谢谢. 本文详细介绍了twitter storm中的nimbus节点的启动场景,分析nimbus是如何一步步实现定义于storm.thrift中的servic ...
- twitter storm源码走读之7 -- trident topology可靠性分析
欢迎转载,转载请注明出处,徽沪一郎. 本文详细分析TridentTopology的可靠性实现, TridentTopology通过transactional spout与transactional s ...
- twitter storm源码走读之8 -- TridentTopology创建过程详解
欢迎转载,转载请注明出处,徽沪一郎. 从用户层面来看TridentTopology,有两个重要的概念一是Stream,另一个是作用于Stream上的各种Operation.在实现层面来看,无论是str ...
- twitter storm源码走读之6 -- Trident Topology执行过程分析
欢迎转载,转载请注明出处,徽沪一郎. TridentTopology是storm提供的高层使用接口,常见的一些SQL中的操作在tridenttopology提供的api中都有类似的影射.关于Tride ...
- 【原】storm源码之mac os x编译twitter storm源码
twitter storm是由backtype公司创始人nathanmarz一手研发和开源的流计算(实时计算)框架,堪称实时计算领域的hadoop.nathanmarz也是在mac os x环境下开发 ...
随机推荐
- 安装绿色版mysql
#修改my.ini basedir = "D:\tools\mysql-5.7.13-winx64" datadir = "D:\tools\mysql-5.7.13-w ...
- Hadoop 2.x HDFS新特性
Hadoop 2.x HDFS新特性 1.HDFS联邦 2. HDFS HA(要用到zookeeper等,留在后面再讲) 3.HDFS快照 回顾: HDFS两层模型 Namespa ...
- Hadoop入门经典:WordCount
转:http://blog.csdn.net/jediael_lu/article/details/38705371 以下程序在hadoop1.2.1上测试成功. 本例先将源代码呈现,然后详细说明执行 ...
- kindEditort图片自动上传
参考:http://www.cnblogs.com/jaxu/p/3824583.html (赞一个)
- Solr常用查询语法笔记
1.常用查询 q - 查询字符串,这个是必须的.如果查询所有*:* ,根据指定字段查询(Name:张三 AND Address:北京) fq - (filter query)过虑查询,作用:在q查询符 ...
- 【Android 进阶】临时卸载root和恢复root功能
[前言]为什么有这个需求? Q:首先,谈谈为啥想要root呢? A:有root才能有控制权,也才能折腾很多东西,比如:删删流氓软件,用用代理.软件自动安装等: Q:然后,那么为何又需要删除root呢? ...
- 有哪些关于 Android 开发的博客值得订阅?
链接:http://www.zhihu.com/question/19788650/answer/60771437来源:知乎 Google 官方[Android Developers Blog](An ...
- MATLAB信号与系统分析(四)——离散信号与系统的复频域分析及MATLAB实现
一.系统的z变换和反变换 1.利用部分分式展开求解逆Z变换: 2.例子 3.Z变换的MATLAB函数 clear all f=sym('cos(a*k)'); F=ztrans(f) F=sym('z ...
- 用DTD约束XML详解及示例
文档类型定义(DTD)可定义合法的XML文档构建模块.它使用一系列合法的元素来定义文档的结构. dtd的三种引入方式 (1)引入外部的dtd文件 <!DOCTYPE 根元素名称 SYSTE ...
- Eclipse+Tomcat部署项目的一些总结
1. eclipse运行web项目后, 默认保存到 workspace\.metadata\.plugins\org.eclipse.wst.server.core\tmp0\wtpwebapps. ...