K邻近分类算法
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 28 17:16:19 2018 @author: zhen
"""
from sklearn.model_selection import train_test_split
import mglearn
import matplotlib.pyplot as plt
x, y = mglearn.datasets.make_forge()
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0) # 生成训练和测试集数据 from sklearn.neighbors import KNeighborsClassifier
14 clf = KNeighborsClassifier(n_neighbors=3) # 调用K近邻分类算法
15
16 clf.fit(x_train, y_train) # 训练数据 print("Test set predictions:{}".format(clf.predict(x_test))) # 预测 print("Test set accuracy:{:.2f}".format(clf.score(x_test, y_test))) fig, axes = plt.subplots(1, 3, figsize=(10, 3)) # 使用matplotlib画图 for n_neighbors, ax in zip([1, 3, 9], axes):
# fit 方法返回对象本身,所以我们可以将实例化和拟合放在一行代码中
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(x, y)
mglearn.plots.plot_2d_separator(clf, x, fill=True, eps=0.5, ax=ax, alpha=0.4)
mglearn.discrete_scatter(x[:, 0], x[:, 1], y, ax=ax)
ax.set_title("{} neighbor(s)".format(n_neighbors))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
axes[0].legend(loc=3)
结果:

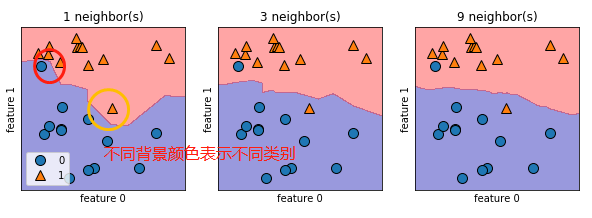
总结:从图中可以看出,使用单一邻居绘制的决策边界紧跟着训练数据,随着邻居的增多,决策边界也越来越平滑,更平滑的边界对应更简单的模型,换句话说,使用更少的邻居对应更高的模型复杂度。
K邻近分类算法的更多相关文章
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- 监督学习-KNN最邻近分类算法
分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术建立分类模型,从而对没有分类的数据进行分类的分析方法. 分类问题的应用场景:用于将事物打上一 ...
- KNN邻近分类算法
K邻近(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:计算一个点A与其他所有点之间的距离,取出与该点最近的 ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- 查看neighbors大小对K近邻分类算法预测准确度和泛化能力的影响
代码: # -*- coding: utf-8 -*- """ Created on Thu Jul 12 09:36:49 2018 @author: zhen &qu ...
- K邻近回归算法
代码: # -*- coding: utf-8 -*- """ Created on Fri Jul 13 10:40:22 2018 @author: zhen &qu ...
- sklearn_k邻近分类
# K邻近分类#--------------------------------# coding:utf-8 import pandas as pd from sklearn.neighbors im ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
随机推荐
- django 中文入门文档
django中文入门文档:阅读地址
- CSS基础和选择器
什么是CSS? CSS是指层叠样式表(Cascading Style Sheets),样式定义如何显示HTML元素,样式通常又会存在于样式表中.也就是说把HTML元素的样式都统一收集起来写在一个地方或 ...
- C# log4net 使用
利用log4net写入异常类日志,在网上搜索一阵之后便想记录下来,以便后期使用,同时希望帮到大家. 第一步:使用管理NuGet程序包导入log4net.dll 导入成功后会在引用下显示相应的log4 ...
- 正则表达式matcher.group用法
group是针对括号()来说的,group(0)就是指的整个串,group(1) 指的是第一个括号里的东西,group(2)指的第二个括号里的东西. 上代码: @Test public void te ...
- Python:标准库(包含下载地址及书本目录)
下载地址 英文版(文字版) 官方文档 The Python Standard Library <Python标准库>一书的目录 <python标准库> 译者序 序 前言 第1章 ...
- Java:Cookie实现记住用户名、密码
package com.gamecenter.api.util; import java.io.IOException; import java.io.PrintWriter; import java ...
- SpringBoot一站式启动流程源码分析
一.前言 由上篇文章我们得知,SpringBoot启动时,就是有很简单的一行代码.那我们可以很清楚的看到这行代码的主角便是SpringApplication了,本文我们就来聊一聊这货,来探寻Sprin ...
- 读vue-0.6-observer.js源码
实现监听数组方法 var ArrayProxy = Object.create(Array.prototype), methods = ['push','pop','shift','unshift', ...
- 函数调用的区别:_cdecl以及_stdcall
一.概念1)_stdcall调用 _stdcall是Pascal程序的缺省调用方式,参数采用从右到左的压栈方式,由调用者完成压栈操作,被调函数自身在返回前清空堆栈. WIN32 Api都采用_ ...
- vue里碰到 $refs 的问题
记录困惑自己一个简单的问题...(瞬间感觉官方文档的强大) 在自己做的一个项目中,遇到一个列表页,根据id能进入详情页(动态匹配路由),详情页是单独的一个组件,在这个详情的组件里,我想获取内容给你区域 ...