如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频

国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶~~
我身边的很多小伙伴们在朋友圈里面晒着出去游玩的照片,简直了,人多的不要不要的,长城被堵到水泄不通,老实人想想啊,既然人这么多,哪都不去也是件好事,没事还可以刷刷 B 站 23333 。这时候老实人也有了一个大胆地想法,能不能让这些在旅游景点排队的小伙伴们更快地打发时间呢?考虑到视频的娱乐性和大众观看量,我决定对 B 站新推出的小视频功能下手,于是我跑到B站去找API接口,果不起然,B站在小视频功能处提供了 API 接口,小伙伴们有福了哟!
B 站小视频网址在这里哦:
http://vc.bilibili.com/p/eden/rank#/?tab=全部
此次实验,我们爬取的是每日的小视频排行榜前 top100
我们该如何去爬取呢???
实验环境准备
Chrome浏览器 (能使用开发者模式的浏览器都行)Vim(编辑器任选,老实人比较喜欢Vim界面,所以才用这个啦)Python3开发环境Kali Linux(其实随便一个操作系统都行啦)
API寻找&&提取
我们通过 F12 打开开发者模式,然后在 Networking -> Name 字段下找到这个链接:
http://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&next_offset=&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc
我们查看一下 Headers 属性
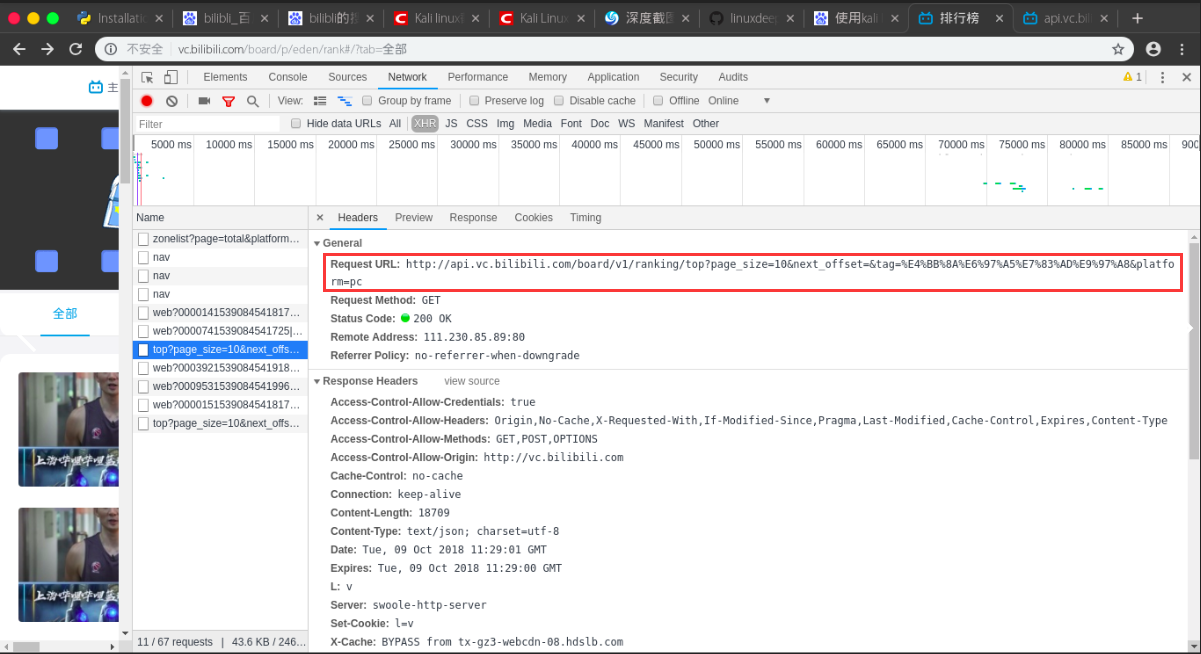
我们可以看到Request URL这个属性值,我们向下滑动加载视频的过程中,发现只有这段url是不变的。
http://api.vc.bilibili.com/board/v1/ranking/top?
next_offset 会一直变化,我们可以猜测,这个可能就是获取下一个视频序号,我们只需要把这部分参数取出来,把 next_offset 写成变量值,用 JSON 的格式返回到目标网页即可。
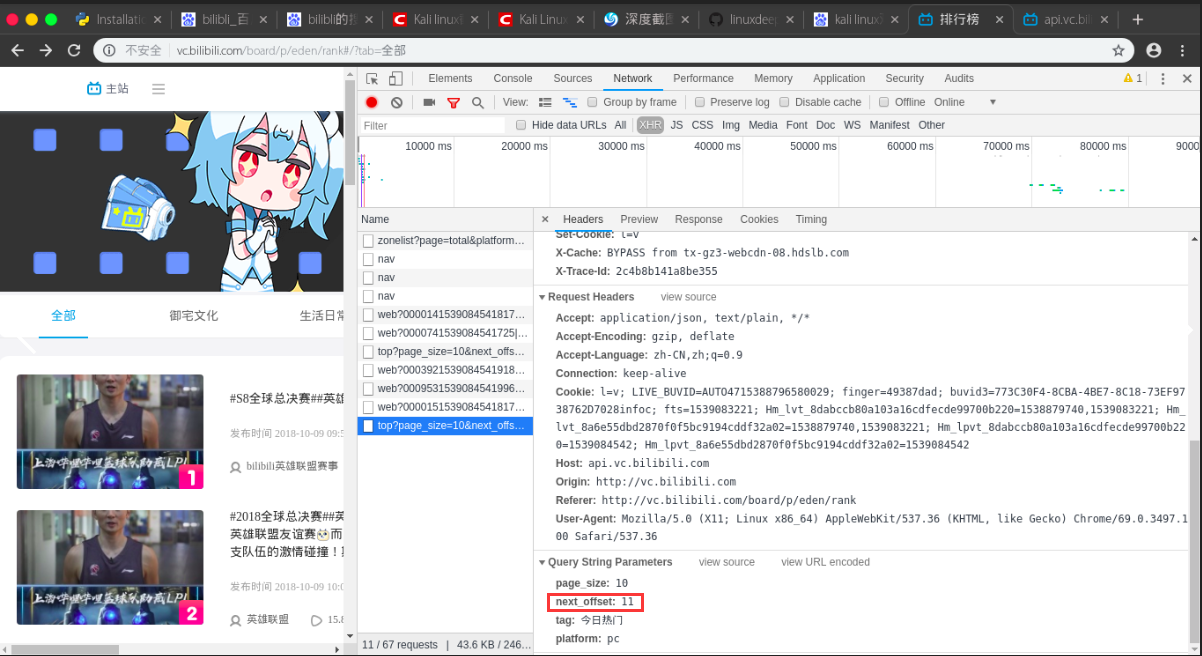
代码实现
我们通过上面的尝试写了段代码,发现 B 站在一定程度上做了反爬虫操作,所以我们需要先获取 headers 信息,否则下载下来的视频是空的,然后定义 params 参数存储 JSON 数据,然后通过 requests.get 去获取其参数值信息,用 JSON 的格式返回到目标网页即可,实现代码如下:
def get_json(url):
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
params = {
'page_size': 10,
'next_offset': str(num),
'tag': '今日热门',
'platform': 'pc'
}
try:
html = requests.get(url,params=params,headers=headers)
return html.json()
except BaseException:
print('request error')
pass
为了能够清楚的看到我们下载的情况,我们折腾了一个下载器上去,实现代码如下:
def download(url,path):
start = time.time() # 开始时间
size = 0
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url,headers=headers,stream=True) # stream属性必须带上
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 总大小
if response.status_code == 200:
print('[文件大小]:%0.2f MB' %(content_size / chunk_size / 1024)) # 换算单位
with open(path,'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data) # 已下载的文件大小
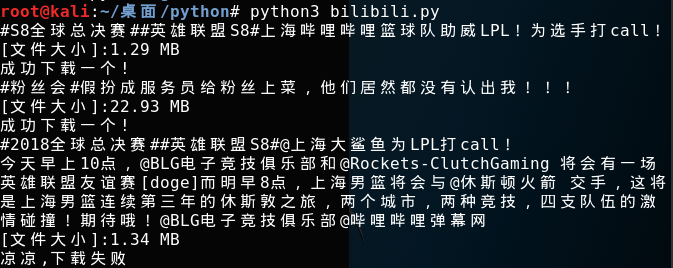
效果如下:
将上面的代码进行汇总,整个实现过程如下:
#!/usr/bin/env python
#-*-coding:utf-8-*-
import requests
import random
import time
def get_json(url):
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
params = {
'page_size': 10,
'next_offset': str(num),
'tag': '今日热门',
'platform': 'pc'
}
try:
html = requests.get(url,params=params,headers=headers)
return html.json()
except BaseException:
print('request error')
pass
def download(url,path):
start = time.time() # 开始时间
size = 0
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url,headers=headers,stream=True) # stream属性必须带上
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 总大小
if response.status_code == 200:
print('[文件大小]:%0.2f MB' %(content_size / chunk_size / 1024)) # 换算单位
with open(path,'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data) # 已下载的文件大小
if __name__ == '__main__':
for i in range(10):
url = 'http://api.vc.bilibili.com/board/v1/ranking/top?'
num = i*10 + 1
html = get_json(url)
infos = html['data']['items']
for info in infos:
title = info['item']['description'] # 小视频的标题
video_url = info['item']['video_playurl'] # 小视频的下载链接
print(title)
# 为了防止有些视频没有提供下载链接的情况
try:
download(video_url,path='%s.mp4' %title)
print('成功下载一个!')
except BaseException:
print('凉凉,下载失败')
pass
time.sleep(int(format(random.randint(2,8)))) # 设置随机等待时间
爬取效果图如下:
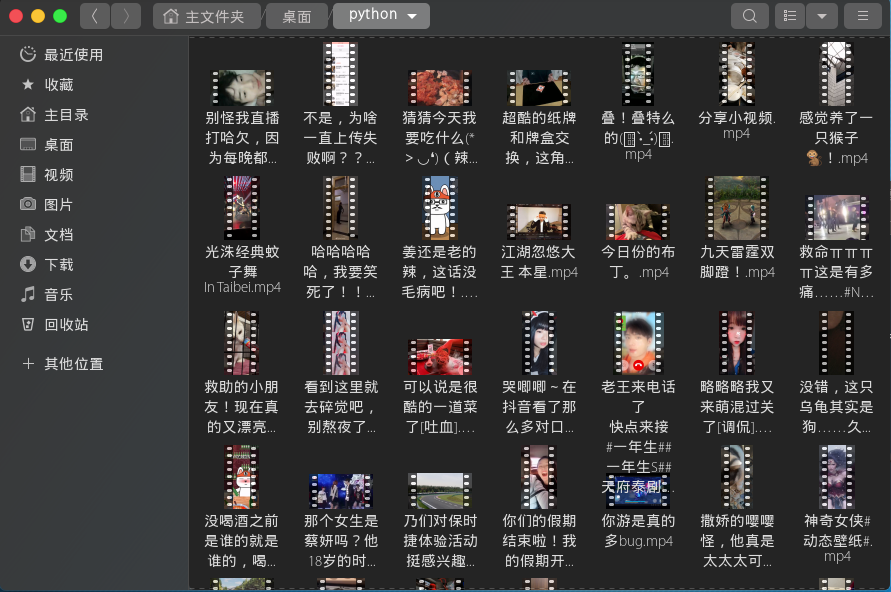
似乎爬取的效果还可以,当然喜欢的朋友不要忘记点赞推荐 & star啊。
项目链接
如何手动写一个Python脚本自动爬取Bilibili小视频的更多相关文章
- 写一个python脚本监控在linux中的进程
在虚拟机中安装Linux中的CentOS7系统 https://baijiahao.baidu.com/s?id=1597320700700593557&wfr=spider&for= ...
- Python 自动爬取B站视频
文件名自定义(文件格式为.py),脚本内容: #!/usr/bin/env python #-*-coding:utf-8-*- import requests import random impor ...
- Python脚本:爬取天气数据并发邮件给心爱的Ta
第一部分:爬取天气数据 # 在函数调用 get_weather(url = 'https://www.tianqi.com/foshan') 的 url中更改城市,foshan为佛山市 1 impor ...
- Python爬虫:爬取美拍小姐姐视频
最近在写一个应用,需要收集微博上一些热门的视频,像这些小视频一般都来自秒拍,微拍,美拍和新浪视频,而且没有下载的选项,所以只能动脑想想办法了. 第一步 分析网页源码. 例如:http://video. ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- sumafan:python爬虫多线程爬取数据小练习(附答案)
抓取 https://www.cnbeta.com/ 首页中新闻内容页网址, 抓取内容例子: https://hot.cnbeta.com/articles/game/825125 将抓取下来的内容页 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- 用Node+wechaty写一个爬虫脚本每天定时给女(男)朋友发微信暖心话
wechatBot 微信每日说,每日自动发送微信消息给你心爱的人 项目介绍 灵感来源 在掘金看到了一篇<用Node + EJS写一个爬虫脚本每天定时女朋友发一封暖心邮件>后, 在评论区偶然 ...
随机推荐
- 【转】解决weblogic启动慢和创建域慢的方法
创建域慢启动慢的特征:创建域到70%时,进程长时间等待(命令行创建时停止在100%处),创建域启动Weblogic的时候也是长时间停止. Weblogic在Linux下启动慢的原因,发现从进程堆来看, ...
- python第九十五天--js正则
定义正则表达式 /.../ 用于定义正则表达式 /.../g 表示全局匹配 /.../i 表示不区分大小写 /.../m 表示多行匹配 JS正则匹配时本身就是支持多行,此处多行匹配只是影响正则表达式^ ...
- 非对称加密与GPG/PGP
最近浏览博客的时候,经常会看到博主展示出自己的公钥,于是对 GPG/PGP 产生兴趣.下面简单记录相关文章的链接,方便以后了解. 简介: 1991年,程序员Phil Zimmermann为了避开政府的 ...
- Centos7下安装与卸载docker应用容器引擎
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然后发布到任何流行的 Li ...
- linux 下正则匹配时间命名格式的文件夹
用正则表达式匹配时间格式命名的文件夹 ls mypath | grep -E "[0-9]{4}-[0-9]{1,2}" mypath为需要查询的目录 查询出来的文件夹格式为:例 ...
- Hive-1.2.1_01_安装部署
前言:该文章是基于 Hadoop2.7.6_01_部署 进行的. 1. Hive基本概念 1.1. 什么是Hive Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库 ...
- 在pycharm中每次运行代码不使用console而使用run
问题:在pycharm中点击run运行程序,发现没有打开run窗口,而是打开的Python console窗口. 解决方法:打开菜单栏run->edit configurations,把下图中的 ...
- 创建随机的9x9数独游戏终盘并打印
创建随机的9x9数独游戏终盘并打印 项目github地址 1. 项目相关要求 1.1 要求 利用程序随机构造出N个已解答的9x9数独棋盘 . 输入 数独棋盘题目个数N(0<N<=10000 ...
- CSS3 animation动画,循环间的延时执行时间
如下代码,其中的delay值为3s,但是animation按现在的规则,这个delay是指动画开始前的延时,在动画循环执行间,这个delay是不生效的. .item{ webkit-animation ...
- vue的组件详解
什么是组件 组件(Component)是 Vue.js 最强大的功能之一.(好比电脑中的每一个元件(键盘,鼠标,CPU),它是一个具有独立的逻辑和功能或界面,同时又能根据规定的接口规则进行互相融合,变 ...