宽字符wchar_t和窄字符char——putwchar、wprintf
宽字符wchar_t 与 窄字符char
先说下窄字符char,这个大部分读者应该很清楚,char类型的变量占一个字节(byte)(也就是8个bit(比特)),能表示256个字符,那char的范围有两种
第一种(signed char):-128~127
第二种(unsigned char):0~255
(对char的范围感兴趣的读者可以看一下这篇文章:浅谈char类型范围)
但C标准并没有规定char 应该是unsigned还是signed,C标准定义了三种类型:char、signed char、unsigned char在不同的编译器下char可能是有符号数,也有可能是无符号数(意思是取决于编译器)
那么怎样确定char是有符号数还是无符号数呢,有两种方法
方法一:使用CHAR_MIN(注意:CHAR_MIN这个宏是在stdlib.h这个头文件中定义的)
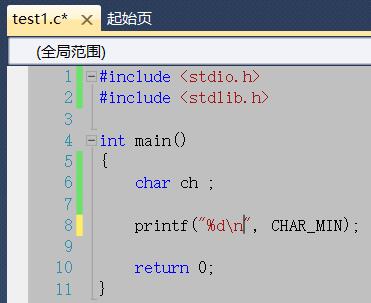
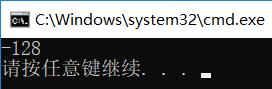
运行结果:
方法二:给char类型的变量赋值负数(如果char在编译器上是有符号数,那么赋值只要是大于等于-128的数都可以正常打印)
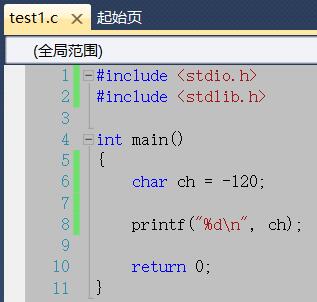
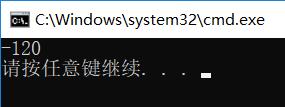
运行结果:
上述两种方法都可以用来确定char是无符号数还是有符号数(感兴趣的读者可以自行测试一下char的边界,如果char是有符号数,可以给char赋值127或128来看一下会出现什么结果)
现在来说下宽字符wchar_t,先来看下char和wchar_t在存储空间上的差别

运行结果:
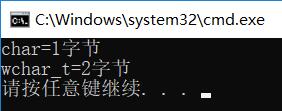
从上面可以看出char占一个字节,wchar_t占两个字节
下面来确定wchar_t是有符号数还是无符号数
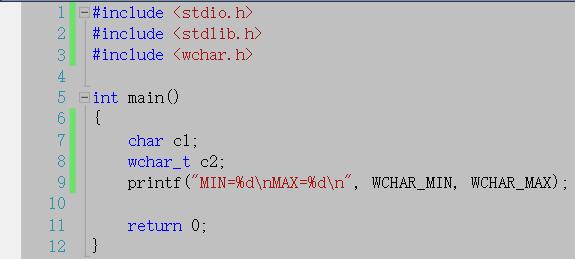
运行结果:

从上面的结果可以看出wchar_t为无符号数,因为wchar_t占两个字节,也就是16个比特(bit),最大值就是216-1=65535,到这里读者可以看出宽字符和窄字符最大的区别就是占字节大小的不同
宽字符 和 窄字符的赋值
关于窄字符char,大部分读者都知道赋值的方法 或者
或者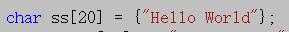
而宽字符的赋值就不太一样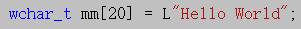 与窄字符相比,前面多了一个大写的L,这个L的作用就是告诉编译器,这个字符串按照宽字符来存储(一个字符占两个字节)
与窄字符相比,前面多了一个大写的L,这个L的作用就是告诉编译器,这个字符串按照宽字符来存储(一个字符占两个字节)
按照之前的说法宽字符中一个字符占2个字节,那么mm[20]应该占40个字节,长度应该为11,下面来验证一下
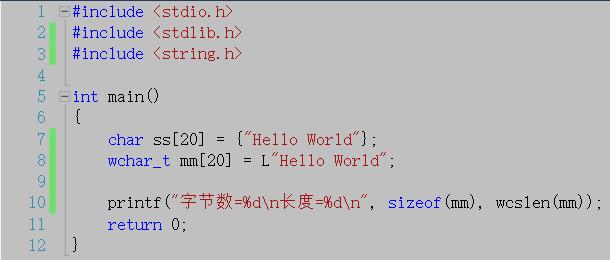
运行结果:
上面的代码中用到了一个函数wcslen(),这个函数和strlen()其实是一个作用,只不过strlen适用于窄字符,wcslen适用于宽字符(读者可以理解为wcslen是strlen对应的一个宽字符版本函数)
在C语言中的每个字符串处理函数都有对应的宽字符处理版本,下面列举一些常见的宽字符处理函数

(图片出处:https://www.cnblogs.com/mr-wid/archive/2012/10/07/2714392.html)
还有一点需要读者注意的是,宽字符不等于Unicode,Unicode 是宽字符编码的一种,只不过最常见的宽字符编码方式就是Unicode了,UTF-16和UTF-32都是Unicode编码。wchar_t也主要以这两种方式实现
( c/c++标准只是声明wchar_t是一个足够宽的变量类型,可以表示字符集中的任意一个字符)
Unicode 是一套字符集,而不是一套字符编码,严格来说,字符集和字符编码不是一个概念:
字符集定义了字符和二进制的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,
计算机显示文字或者存储文字,就是一个查表的过程。
而字符编码规定了如何将字符的编号存储到计算机中。如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符
到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码

Unicode最长是32位,也就是4个字节,因为UTF-8是1~6个字节来存储,当使用5或6字节存储时,就不属于Unicode编码了
(感兴趣的读者可以看一下:刨根问底:C++中宽字符类型(wchar_t)的编码一定是Unicode?长度一定是16位?)

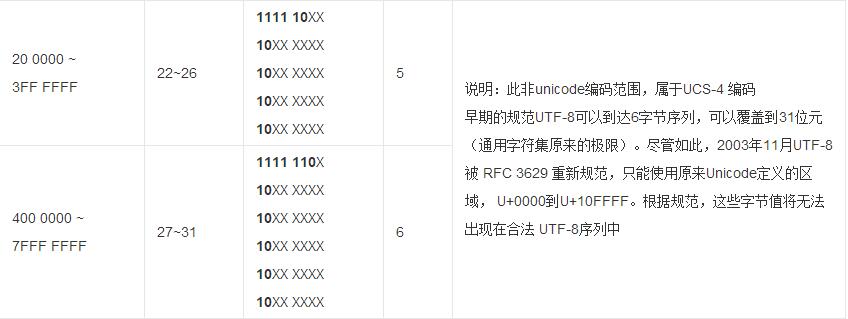
宽字符输出函数
wprintf
wprintf无非就是printf的一个变种,和fprintf差不多只是格式上稍有区别
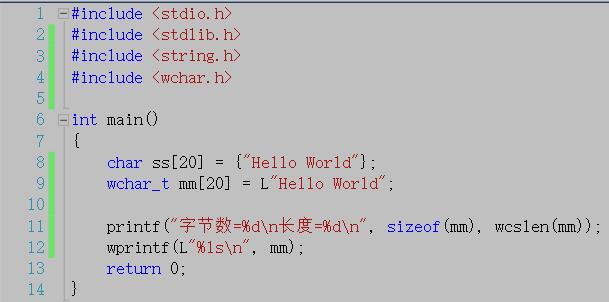
运行结果:

上面的代码中,wprintf使用的格式控制符是%ls,%ls意味着将对应的参数会被当作基于宽字符的字符串(wide chraracter string )看待,而%s则意味着对应的参数会被当作普通字符串(multi-byte string)看待,
不要因为上面一句话而错误的认为%s只用于printf,而%ls只用于wprintf,其实在windows下使用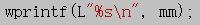 和
和 都是可以正常输出宽字符串的(其他操作系统下就不一定了)
都是可以正常输出宽字符串的(其他操作系统下就不一定了)
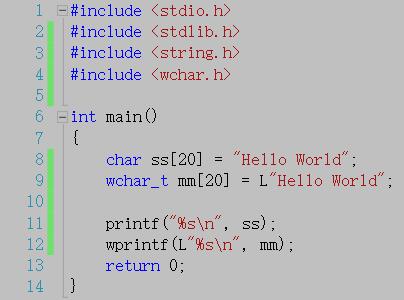
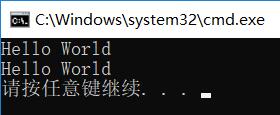
%s
当使用 printf() 时,按照单字符格式输出字符串
当使用 wprintf() 时,按照宽字符(两字节)格式输出字符串
%S
当使用 printf() 时,按照宽字符格式输出字符串
当使用 wprintf() 时,按照单字符格式输出字符串
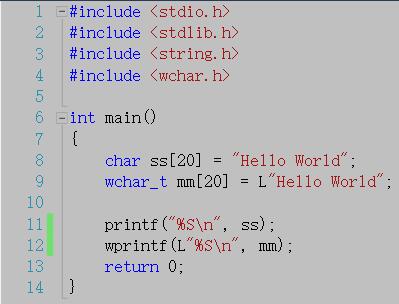
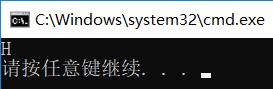
注意这个H是宽字符串mm中的H,而不是ss中的H,ss中的字符串中的每个字符占一个字节,printf如果按照宽字符的标准来输出就无法正常输出了,而wprintf为什么只输出了H呢,不是输出字符串吗,
下面我们用VS来看宽字符在内存中的存储


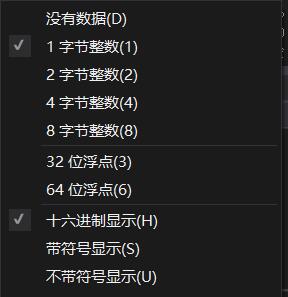
从上图就可以很清楚的看出“Hello World”这个宽字符串在内存中的存储情况了,因为是宽字符所以大写字母H用两个字节表示(48 00),48是16进制转成10进制就是72,刚好就是'H'的ASCII码值的大小,如果按照单字符格式输出(也就是一个字节一个字节的输出)就输出H,继续往后,编译器看到第二个字节00,就以为字符串已经到结束了,最后我们看到的结果就是只输出了大写字符H
(本来对%S没有什么疑问,就当成一个格式控制符记住就是,后来在微软的官方文档里找到了%S这个参数的解释,如下图)

上面这段话的意思大概是,%S这个格式说明符,表示使用与函数支持的默认宽度“相反”的字符宽度,有了这一段话,上面的就很好解释了,printf因为默认支持的宽度是单字符,而%S偏要使用相反的,那么就
使用宽字符格式输出,而wprintf默认支持的宽度是宽字节,%S偏要使用相反的,意思就是使用单字符格式输出,这样记起来就容易多了
如果想要输出宽字符的单个字符,需要使用格式控制符%lc
(要清楚%ls和%s的意义在于指明的参数是何种字符串,而printf和wprintf的区别在于所使用的是不同类型的stream,不要混用 char 和 wchar_t 版本的流操作函数,否则会导致这些函数运行异常)
putwchar
putwchar函数专门用来输出一个宽字符,它和 putchar 的用法类似
wchar_t ch = L'Z';
putwchar(ch);
运行结果:

宽字符wchar_t和窄字符char——putwchar、wprintf的更多相关文章
- C++ 宽字符(wchar_t)与窄字符(char)的转换
了解 长度 宽字符wchar_t的长度16位,可以用来显示中文等除英文外的其他文字, 窄字符 char 的长度 8 位,只能处理英文. 哪里可以见到 在VS2010, 2012, 2013 ...
- 宽字符wchar_t和窄字符char区别和相互转换
转自:http://blog.csdn.net/nodeathphoenix/article/details/7416725 1. 首先,说下窄字符char了,大家都很清楚,就是8bit表示的b ...
- GBK转utf-8,宽字符转窄字符
//GBK转UTF8 string CAppString::GBKToUTF8(const string & strGBK) { string strOutUTF8 = "" ...
- C语言小程序——推箱子(窄字符和宽字符)
C语言小程序——推箱子(窄字符Version) 推箱子.c #include <stdio.h> #include <conio.h> #include <stdlib. ...
- volatile,可变参数,memset,内联函数,宽字符窄字符,国际化,条件编译,预处理命令,define中##和#的区别,文件缓冲,位域
1.volatile: 要求参数修改每次都从内存中的读取.这种情况要比普通运行的变量需要的时间长. 当设置了成按照C99标准运行之后,使用volatile变量之后的程序运行的时间将比register的 ...
- 使用Unicode(宽字节字符集);多字节字符集中定义宽字节变量
2012-03-25 14:54 (分类:计算机程序) 2.2 宽字符和C 宽字符不一定是Unicode.Unicode是宽字符集的一种.然而,因为本书的焦点是Windows而不是C执行的理论,所以书 ...
- 计算字符串中每种字符出现的次数[Dictionary<char,int>泛型集合用法]
有一道经典的面试题: 统计 welcome to china中每个字符出现的次数,不考虑大小写. 第一个出现在脑海里的想法是: 1. 将字字符串转换成 char数组: 2. 用 for循环遍 ...
- strlen 字符型数组和字符数组 sizeof和strlen的区别 cin.get(input,Arsize)
strlenstrlen所作的仅仅是一个计数器的工作,它从内存的某个位置(可以是字符串开头,中间某个位置,甚至是某个不确定的内存区域)开始扫描,直到碰到第一个字符串结束符'\0'为止,然后返回计数器值 ...
- 有一字符串,包含n个字符。写一函数,将此字符串中从第m个字符开始的全部字符复制成为另一个字符串。
[提交][状态][讨论版] 题目描述 有一字符串,包含n个字符.写一函数,将此字符串中从第m个字符开始的全部字符复制成为另一个字符串. 输入 数字n 一行字符串 数字m 输出 从m开始的子串 样例输入 ...
随机推荐
- threading 多线程使用
实例 1import threading #线程import time def Say(n): print('Test %d' %n) time.sleep(2) if __name__ == '__ ...
- 学习node.js 第2篇 介绍node.js 安装
Node.js - 环境安装配置 如果愿意安装设置Node.js环境,需要计算机上提供以下两个软件: 一.文本编辑器 二.Node.js二进制安装包 文本编辑器 这将用来编写程序代码. 一些编辑器包括 ...
- 深入理解Java虚拟机之Java内存区域随笔
1.java内存区域与内存溢出异常 Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域:1.程序计数器,2.栈(虚拟机栈和本地方法栈 ),3.堆,4.方法区(包含 ...
- ABAP 省市县级联搜索帮助
在展示ABAP代码之前,先建立自建表ZCHENH006,表中包含两个关键字段 BELNR(地区编码),SDESC(地区描述). 编码规则参考:身份证前六位地区编码规则,可参考我另外一篇Blog导入系统 ...
- 引用计数——深拷贝&浅拷贝
下面是用代码实现: private: char *data; size_t use_count; public: //构造函数 String_rep() { if(str == NULL) { dat ...
- jieba分词/jieba-analysis(java版)
简介 支持分词模式Search模式,用于对用户查询词分词Index模式,用于对索引文档分词特性支持多种分词模式全角统一转成半角用户词典功能conf 目录有整理的搜狗细胞词库因为性能原因,最新的快照版本 ...
- 解决HighChart开发遇到的2个问题
需求很简单,显示一条24小时的变化曲线 写完代码效果是只有一条直线,连时间轴都没有 第1个错误 Highcharts error #12 当通过要绘制的点超过1000个时就会报这个错,我按分钟计算间 ...
- python 文件读写方式
一.普通文件读写方式 1.读取文件信息: with open('/path/to/file', 'r') as f: content = f.read() 2.写入文件中: with open('/U ...
- canvas(三) star- demo
/** * Created by xianrongbin on 2017/3/8. * 本例子使用渐变画出 璀璨星空 */ var dom = document.getElementById('clo ...
- linux下sort命令使用详解---linux将文本文件内容加以排序命令
转载自:http://www.cnblogs.com/hitwtx/archive/2011/12/03/2274592.html linux下sort命令使用详解---linux将文本文件内容加以排 ...