《数据仓库ETL工具箱》读书笔记
在本书中,你将学习到以下内容:
规划&设计你的ETL系统
从多种可能的架构中选出最合适的
对实施过程进行管理
管理日常的操作
为ETL过程建立开发/测试/生产环境
理解不同的后台数据结构,包括平面文件、规范化框架、XML框架和星型连接(维度)框架
分析和抽取源数据
创建完整的数据清洗子系统
将数据结构化为维度框架,以便更有效提交给最终用户、商务智能工具、数据挖掘工具、OLAP立方体和分析应用系统
使用同一种技术将数据有效地提交到高度集中的或分布的数据仓库
调整个ETL过程使性能达到最优
以上观点是ETL系统中主要的大问题,但是尽可能的,我们还会提供更细层面上的技术细节:
针对列属性、结构、有效值和复杂业务规则实施数据清洗系统的关键执行步骤
将多个源的异构数据规格化为标准化的维表和事实表
创建可复用的ETL模块用于处理维表中自然时间变量,例如,三种类型的缓慢变化维(SCD)
创建可复用的ETL模块用于处理多值维和层次维,这两者都需要相应的桥接表
针对海量事实表的加载进行处理
优化ETL过程以适应加载时窗的要求
如何将批处理和面向文件的ETL系统转换为连续的流式实时ETL系统
数据仓库是一个将源系统数据抽取、清洗、规格化、提交到维度数据存储的系统,为决策的制定提供查询和分析功能的支撑与实现。
数据仓库的总体目标是,以简单的、可操作的格式将数据提交给最终用户和分析应用系统。
对于数据仓库项目来说,自动ETL处理显然是需要的,但是如何做呢?表加载的顺序和依赖关系是加载数据仓库成功的关键因素。
几个常用关键字:
- 数据仓库(Data Warehouse)
- 数据集市(Data Mart)
- 操作型数据存储(ODS, Operational Data Store)
- 企业数据仓库(EDW, Enterprise Data Warehouse)
- 集结区(Staging Area)
- 展现区(Presentation area)
每个ETL系统都必须将数据集结为各种永久性的或准永久性的格式。当我们提到“集结(Staging)”时,意味着写数据到磁盘,也正是由于这个原因,ETL系统有时称为集结区(staging area)。你可能注意到我们建议在每一格ETL主要步骤(抽取、清洗、规格化和提交)后都有几种形式的集结。
清洗的意思是确认和修复数据中的错误和缺失。规格化的意思是解决潜在不一致的数据间的标记(Labeling)冲突,以便它们能够在企业数据仓库中一起使用。
1 介绍
抽取-转换-加载(Extract-Transform-Load)系统是数据仓库的基础。一个设计良好的ETL系统从源系统抽取数据,执行数据质量和一致性标准,然后规格化数据,从而使分散的源数据可以集中在一起使用,最终再以可以展现的格式提交数据,以便应用开发者可以创建应用系统,也使最终用户可以制定决策。ETL能够:
- 消除数据错误并纠正缺失数据
- 提供对于数据可信度的文档化衡量
- 为保护数据获取相互作用的数据流程
- 把多个源数据整合到一起
- 将数据进行结构化供最终用户使用
ETL的规划和设计主线:

数据流主线:
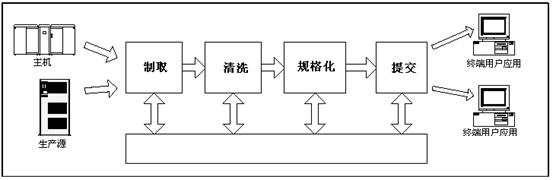
2
需求、现状和架构
2.1
需求可以分为:
业务需求、合规需求、数据评估、安全需求、数据集成、数据延迟、数据归档和数据线性化、最终用户提交界面、可用的技能、已有的许可证。
一切围绕需求
业务需求是数据仓库最终用户的信息需求。我们使用业务需求这个术语来狭义地表示最终用户作出决策所需的信息内容。
业务需求直接决定了数据源的选择。ETL小组的核心工作就是不断地理解和检验业务需求。
从更广泛的意义上讲,业务需求和数据源的内容都是不断变化的,需要不断地进行检验和讨论。
2.2架构需要考虑:
选用ETL工具还是编码?
数据仓库的前台和后台:

2.3
数据仓库的任务:
数据仓库的任务是发布企业的数据资产,用于支持更加有效的决策制定。该任务描述中的关键词是发布。正如传统的杂志发行,其成功的起点和终点是读者,数据仓库成功的起点和终点是其最终用户。由于数据仓库是一个决策支持系统,因此主要的成功标准是数据仓库是否为企业的最重要的决策制定过程提供了帮助。ETL系统在时间上面临的最大风险来自于未知的数据质量问题
数据仓库的吸引人之处就在于它具有真正集成的数据,同时也让用户从他们的角度查看维度。一致的维度和事实是企业数据仓库的基石。
3
ETL数据结构
数据仓库的后台部分经常被称为集结区(Staging
Area)。在这里的上下文中,数据的集结过程指的是写入磁盘,并且我们建议在ETL数据流的四个主要检查点都要有数据集结。ETL小组需要不同的数据结构来满足不同的数据集结需求。
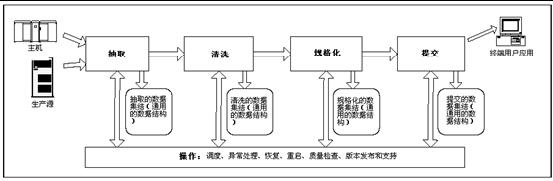
ETL系统中可能使用的几种重要数据结构类型:
- 平面文件
- XML数据集
- 关系表
- 独立的DBMS工作表
- 三范式实体/关系模型
- 非关系数据源
维度数据模型:从后台提交到前台的成果
事实表
维表
原子事实表和聚合事实表
代理键映射表
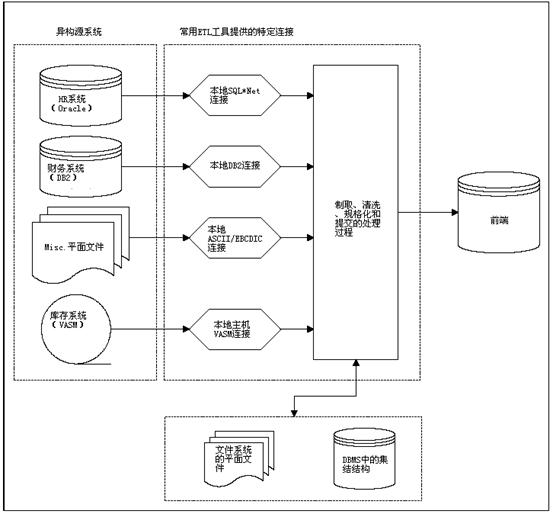
4 抽取
确认抽取是非常有价值的部分!可以通过一个数据评估工具来决定做或不做这一工作,工具将告诉你是否数据质量满足了业务目标。下一个大的步骤是准备连接到初始源数据到最终数据的逻辑数据映射。也许逻辑数据映射最重要的部分是应用在输入和输出之间的转换规则描述。当实际执行ETL系统时将会发生一些变化,因此应该经常检查并定期更新逻辑数据映射。如果维护的好,它可能是ETL系统中最有价值的描述。
只导出新数据、变化的数据甚至是已经删除的数据的方法。
5
清洗和规范化
清洗和规范化在ETL系统中是最富价值的的步骤。
建立三份重要的可提交内容:数据评估报告(data-profiling report),错误事件事实表(error event
fact table),审计维(audit
dimension)。围绕着这三份提交内容,你可以建立一个功能强大的清洗和规范化系统。
数据清洗和规范化的目标在于减少数据中的错误,提高数据的质量和可用性,并标准化整个企业共享的关键描述属性和量化度量。
数据质量技巧涵盖了从数据库级别校验单个字段的定义检查(列属性约束),到校查字段到字段之间的一致性(结构约束),再到数据的特定业务规则的检查(数据和值规则约束)。数据质量处理的最后阶段(规范化和去重复)也就实现了,在这一阶段解决跨越多个数据源的数据差异问题。
6提交维表
维表提供了事实表的上下文。虽然维表通常比事实表小得多,但它却是数据仓库的核心,因为它提供了查看数据的入口。我们经常说建立数据仓库其实就是建立维度。因此ETL团队在提交阶段的主要任务就是处理维表和事实表,将最有效的应用方式提交给最终用户。
7提交事实表
事实表装有企业的度量数据。事实表与度量的关系非常简单。如果存在一个度量,则它可以被模型化为事实表的行。如果事实表的行存在,则它就是一个度量。那么什么是度量呢?一个关于度量通用的定义是:通过工具或比例等级可以测量观察的数量值。
在维度建模时,我们有意识地围绕企业的数字度量创建我们的数据库。事实表包含度量,维表包含关于度量的上下文。这种关于事物的简单视图被一次又一次的证明是最终用户直观理解我们的数据仓库的方式。
事实表可以归入三种基础类型。我们强烈推荐在每次设计的时候坚持使用这三种简单的类型。
这三种事实表类型是:交易粒度,周期快照和聚合快照。
交易粒度表示的是在特定时间、空间点上的一次瞬间的测量。典型的例子是零售交易。
周期快照事实表表现的是一个时间段,或者规律性的重复。这类表非常适合跟踪长期的过程,例如银行账户和其他形式的财务报表。
聚合快照事实表用于描述那些有明确开始和结束的过程,例如合同履行,保单受理以及常见的工作流。聚合快照不适合长期连续的处理,如跟踪银行账户或者描述连续的生产制造过程,如造纸。
12、实时ETL系统
一些继续学习的资料:
- 《数据仓库(第四版)》
- 《数据仓库工具箱:维度建模权威指南》,作者Ralph Kimball and Margy Ross,Wiley出版社
- 《数据仓库工具箱:建立基于web的数据仓库》,作者Ralph Kimball and Richard Merz
,Wiley出版社2000年 - 点击流数据仓库的更多信息请参考一本优秀的图书《Clickstream Data Warehousing》,作者是Mark Sweiger, Mark R. Madsen, Jimmy Langston, and Howard Lombard,Wiley出版社2002年出版。
目标数据仓库优化:
Gary Dodge和Tim Gorman写的<<Essential
Oracle8i Data Warehousing:Designing,Building,and Maintaining Oracle
Data Warehuses>>一书。
参考资料:
http://blog.sina.com.cn/s/blog_7836e7a30100vzml.html
《数据仓库ETL工具箱》读书笔记的更多相关文章
- csapp读书笔记-并发编程
这是基础,理解不能有偏差 如果线程/进程的逻辑控制流在时间上重叠,那么就是并发的.我们可以将并发看成是一种os内核用来运行多个应用程序的实例,但是并发不仅在内核,在应用程序中的角色也很重要. 在应用级 ...
- CSAPP 读书笔记 - 2.31练习题
根据等式(2-14) 假如w = 4 数值范围在-8 ~ 7之间 2^w = 16 x = 5, y = 4的情况下面 x + y = 9 >=2 ^(w-1) 属于第一种情况 sum = x ...
- CSAPP读书笔记--第八章 异常控制流
第八章 异常控制流 2017-11-14 概述 控制转移序列叫做控制流.目前为止,我们学过两种改变控制流的方式: 1)跳转和分支: 2)调用和返回. 但是上面的方法只能控制程序本身,发生以下系统状态的 ...
- CSAPP 并发编程读书笔记
CSAPP 并发编程笔记 并发和并行 并发:Concurrency,只要时间上重叠就算并发,可以是单处理器交替处理 并行:Parallel,属于并发的一种特殊情况(真子集),多核/多 CPU 同时处理 ...
- 读书笔记汇总 - SQL必知必会(第4版)
本系列记录并分享学习SQL的过程,主要内容为SQL的基础概念及练习过程. 书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL i ...
- 读书笔记--SQL必知必会18--视图
读书笔记--SQL必知必会18--视图 18.1 视图 视图是虚拟的表,只包含使用时动态检索数据的查询. 也就是说作为视图,它不包含任何列和数据,包含的是一个查询. 18.1.1 为什么使用视图 重用 ...
- 《C#本质论》读书笔记(18)多线程处理
.NET Framework 4.0 看(本质论第3版) .NET Framework 4.5 看(本质论第4版) .NET 4.0为多线程引入了两组新API:TPL(Task Parallel Li ...
- C#温故知新:《C#图解教程》读书笔记系列
一.此书到底何方神圣? 本书是广受赞誉C#图解教程的最新版本.作者在本书中创造了一种全新的可视化叙述方式,以图文并茂的形式.朴实简洁的文字,并辅之以大量表格和代码示例,全面.直观地阐述了C#语言的各种 ...
- C#刨根究底:《你必须知道的.NET》读书笔记系列
一.此书到底何方神圣? <你必须知道的.NET>来自于微软MVP—王涛(网名:AnyTao,博客园大牛之一,其博客地址为:http://anytao.cnblogs.com/)的最新技术心 ...
- Web高级征程:《大型网站技术架构》读书笔记系列
一.此书到底何方神圣? <大型网站技术架构:核心原理与案例分析>通过梳理大型网站技术发展历程,剖析大型网站技术架构模式,深入讲述大型互联网架构设计的核心原理,并通过一组典型网站技术架构设计 ...
随机推荐
- Android基础开发归档
一.Android 基本组件汇总 1. Android中PackageManager使用示例 : http://blog.csdn.net/qinjuning/article/details/686 ...
- 神经网络和误差逆传播算法(BP)
本人弱学校的CS 渣硕一枚,在找工作的时候,发现好多公司都对深度学习有要求,尤其是CNN和RNN,好吧,啥也不说了,拿过来好好看看.以前看习西瓜书的时候神经网络这块就是一个看的很模糊的块,包括台大的视 ...
- electron+react
yarn create react-app electron-react cd electron-react yarn run eject // 修改react-app打包的路径 / -> ./ ...
- vue中使用html2canvas及解决html2canvas截屏图片模糊问题
最近在项目中用到了html2canvas插件,遇到的一些坑写下来,与大家共勉. html2canvas 官方网站http://html2canvas.hertzen.com/index.html 这 ...
- git最佳实践之feature和hotfix分支
先来复习一波,git的最佳分支管理流程: 再简单复习各个分支: master: 主分支,主要用来版本发布. develop:日常开发分支,该分支正常保存了开发的最新代码. feature:具体的功能开 ...
- 下载JDK开发工具包
实例说明 开发java程序必须有Java开发环境,即jdk开发工具包,这个工具包包含了编译.运行.调试等关键的命令.运行Eclipse.NetBeans等开发工具也需要有jdk或jre的支持. 关键技 ...
- 四、XML语言学习(2)
XML约束之DTD 1.XML都是用户自定义标签,若出现小小的错误,软件程序将不能正确地获取文件中的内容而报错.XML技术中,可以编写一个文档来约束一个XML的书写规范,这个文档称之为约束格式良好的X ...
- easyui combobox 去空格事件 去掉,结果输入空格体验不畅的感觉,让combobox能够输入空格
$("[comboname=name]").next("span").find("input.textbox-text").unbind(& ...
- css学习_css用户界面样式
1.css用户界面样式 a.鼠标样式(记住几个兼容性好的) cursor:default/pointer/move/text; b.轮廓 outline outline:2px solid red: ...
- SQL 查询嵌套使用
.查询: 各年级中 分数最高的学习信息 示例表如下: create table it_student( id int primary key auto_increment, -- 主键id ...