软件工程 week 02
一、地址链接
1、作业地址:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110
2、git仓库地址:https://git.coding.net/kefei101/wf.git
二、需求分析
通过对题目要求的分析,我共看到了以下需求:
!判断输入格式,共有6种输入格式,分别进入4种不同的处理方法,得到不同的排序输出。其中(3)(4)可算作一种,(5)(6)可算作一种。
(1)wf -c 文件名 进入直接读取txt方法,并顺序输出词频;
(2)wf -f 文件路径 进入读取文件夹的方法,再读取按照字典排序最靠前的txt文件,并按照字典排序输出单词词频;
(3)wf -c 文件名 -n 数量 进入直接读取txt方法,并按照词频和字典排序输出;
(4)wf -n 数量 -c 文件名 进入直接读取txt方法,并按照词频和字典排序输出;
(5)wf -f 文件路径 -n 数量 进入读取文件夹的方法,再读取按照字典排序最靠前的txt文件,并按照词频和字典排序输出;
(6)wf -n 数量 -f 文件路径 进入读取文件夹的方法,再读取按照字典排序最靠前的txt文件,并按照词频和字典排序输出.
三、功能设计
1、根据用户输入的参数格式,读取指向的文件或文件路径,统计得到txt文本文件的单词词频结果。
2、此处实现附加功能:在小程序中,可以任意输入多次,永久判断;输入格式中的首位单词 wf 即是保存该小程序的文件夹名,若将其放入不同的文件夹,只需将 wf 变为文件夹名即可。
注:为了避免中文乱码问题,我将注释及程序提示都改成英文显示。
四、设计实现
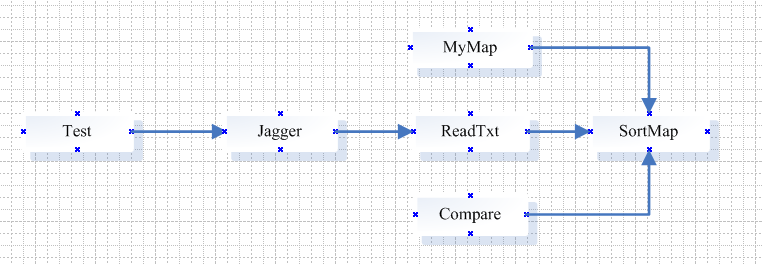
我共设计6个类,如图:

Test类:主类,负责接收输入格式的参数启动程序;
Jagger类:负责根据输入格式的参数不同,分别进入不同的处理方法;
ReadTxt类:负责读取txt文本文件,以及读取文件路径;
SortMap类:负责根据需求的跟能不同,进入不同的排序方法;
Compare类:实现Comparator接口,实现功能(3)--(6)的排序方式(先按照词频排序,再按照字典排序);
MyMap类:是SortMap类中功能三所需要用到的类,用自定义Map类实现list与Map转换的简单性。
5个类的相互关系为:
比较重要的函数有:
Jagger类 :JaggerFormat():判断输入格式,主要是逻辑
ReadTxt类:txtToString():读取txt文件,一行一行读取处理
directoryToTxt():读取文件路径,选择按字典排序最靠前的txt文件,进而调用txtToString()读取txt文件内容
SortMap类:orderPrint():顺序输出txt文件单词词频
sortMap(Map map):按字典顺序输出txt文件单词词频
sortMap(Map map,int num):先按词频排序,再按字典顺序排序
Compare类: compare():实现Comparator接口,重写Compare方法,指定排序方法
函数间的逻辑关系:JaggerFormat()----[directoryToTxt()]----txtToString()----orderPrint()/sortMap(Map map)/[sortMap(Map map,int num)----compare()]
五、测试运行
1、输入正确的格式,即可运行功能一二三


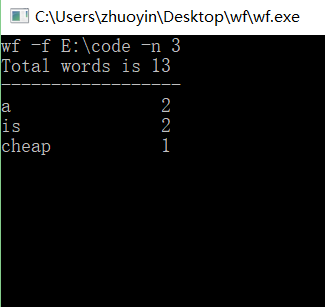
2、测试测试txt

六、重要代码展示
1、主方法main()测试:
- import java.io.IOException;
- import java.util.*;
- /**
- * Class main
- * Author: houst
- * Date: 2018/9/17
- * Time: 15:50
- */
- public class Test {
- /**
- * Main Method
- * @param args args
- * @throws IOException
- */
- public static void main(String args[]) throws IOException {
- while (true) {
- Scanner scanner = new Scanner(System.in);
- String order= scanner.nextLine();//Input format
- //Judging the input format,entering different processing methods.
- Jagger jagger = new Jagger();
- jagger.JaggerFormat(order);
- }
- }
- }
Test
2、Jagger 类中 JaggerFormat()方法:判断输入格式
- import java.io.File;
- import java.util.ArrayList;
- import java.util.LinkedHashMap;
- import java.util.StringTokenizer;
- /**
- * Jagger Class
- * Author: houst
- * Date: 2018/9/20
- * Time: 20:15
- * Judging input
- */
- public class Jagger {
- /**
- * Judging the input format, entering different processing methods.
- * @param order order
- */
- public void JaggerFormat(String order){
- //Use stringTokenizer split input format string,deposit in list.
- StringTokenizer stringTokenizer = new StringTokenizer(order, " \n");
- ArrayList<String> list = new ArrayList<String>();
- while (stringTokenizer.hasMoreElements()) {
- list.add(stringTokenizer.nextToken());
- }
- //Judging whether the first word in the input format is the same as the item name.
- String project = System.getProperty("user.dir");
- project = project.substring(project.lastIndexOf('\\') + 1, project.length());
- if (!list.get(0).equals(project)) {
- System.out.println("Input format error, please input again!");
- } else {
- LinkedHashMap<String, Integer> map = new LinkedHashMap<String, Integer>();
- SortMap sortMap = new SortMap();
- //Function one or two
- if (list.size() == 3) {
- String fileName = list.get(2);
- File file = new File(fileName);//File name or folder name
- String suffix = fileName.substring(fileName.lastIndexOf(".") + 1);//Suffix name
- //Function one: number of non repeated words in statistical documents
- // Judging input format -c File name.txt
- if (list.get(1).equals("-c") && suffix.equals("txt")) {
- //Determine whether text files exist.
- if (file.isFile() && file.exists()) {
- //Read text file (.txt), statistics all word frequency, sequential output.
- ReadTxt readTxt = new ReadTxt();
- map = readTxt.txtToString(file);//Read txt and return to LinkedHashMap type.
- sortMap.orderPrint(map);//order output
- } else{
- System.out.println("There is no such file!");
- }
- //Function two: Specify the file directory, count the number of words
- // that are not duplicated in the most advanced text file in the dictionary order.
- // Judging input format -f file path
- } else if (list.get(1).equals("-f") && !fileName.contains(".")) {
- //Determine whether a folder exists.
- if (file.isDirectory() && file.exists()) {
- //Read the most prioritized text file (.txt) sorted by dictionary in the folder
- // and count all word frequencies.
- ReadTxt readTxt = new ReadTxt();
- map = readTxt.directoryToTxt(file);
- if(!map.isEmpty()){
- sortMap.sortMap(map);//Word frequency sorting
- }
- } else System.out.println("No folder exists!");
- } else {
- System.out.println("Input format error, please input again!");
- }
- //Function three or four
- } else if (list.size() == 5) {
- String fileName = null;//File name or folder name
- String num = null;//input n
- String type = null;//input -c or -f symbol
- //Judging input format type:(-c file name.txt -n number) 或 (-f folder name -n number)
- if ((list.get(1).equals("-c") && list.get(3).equals("-n")) || (list.get(1).equals("-f") && list.get(3).equals("-n") )) {
- type = list.get(1);
- fileName = list.get(2);
- num = list.get(4);
- //Judging input format type:(-n number -c file name.txt) 或 ( -n number -f folder name)
- } else if ( (list.get(1).equals("-n")) && (list.get(3).equals("-c"))|| list.get(1).equals("-n") && (list.get(3).equals("-f") )) {
- type = list.get(3);
- fileName = list.get(4);
- num = list.get(2);
- }
- int no = Integer.parseInt(num);//input num = no
- String suffix = fileName.substring(fileName.lastIndexOf(".") + 1);//get suffix name
- File file = new File(fileName);
- //Function three: the most frequent occurrences of the first N words in statistical documents.
- //Judging input format -c file name.txt -n number
- if (type.equals("-c") && suffix.equals("txt") && num.matches("^[0-9]*$")) {
- //Judging whether text files exist.
- if (file.isFile() && file.exists()) {
- //Read txt and count the top n high-frequency words.
- ReadTxt readTxt = new ReadTxt();
- map = readTxt.txtToString(file);//Read txt and return to LinkedHashMap type.
- sortMap.sortMap(map,no);//Word frequency sorting with numbers.
- } else System.out.println("不存在此文件!");
- //Function 3: Specify the file catalog, count the first N words in the text file
- // with the highest number of non-repetitions in the dictionary order.
- // Judging input format -f File path -n number
- } else if (type.equals("-f") && !fileName.contains(".") && num.matches("^[0-9]*$")) {
- //Judging whether a folder exists.
- if (file.isDirectory() && file.exists()) {
- //Read the file name in the folder sorted by dictionary first file (. txt),
- // and statistics the first n high-frequency words, sorting output
- ReadTxt readTxt = new ReadTxt();
- map = readTxt.directoryToTxt(file);//read folder
- if(!map.isEmpty()){
- sortMap.sortMap(map,no);//word frequency sorting with numbers
- }
- } else System.out.println("No folder exists!");
- } else {
- System.out.println("Input format error, please input again!");
- }
- }
- }
- }
- }
JaggerFormat
这个方法逻辑需要很清晰,每一步怎么走,会有什么结果,想了很久,也是在这里比较多bug,调试的时间大概是4小时。
3、ReadTxt类中 txtToString():读取txt文件,一行一行读取处理
- /**
- * Read (.Txt) files with behavior units
- * @param file file
- * @return return
- * Return type:LinkedHashMap
- */
- public LinkedHashMap<String,Integer> txtToString(File file) {
- BufferedReader reader = null;
- LinkedHashMap<String, Integer> map = new LinkedHashMap<String, Integer>();
- try {
- String string = null;
- reader = new BufferedReader(new FileReader(file));
- //Read txt files from line to line
- while ((string = reader.readLine()) != null) {
- //Convert non alphanumeric symbols into spaces, case sensitive,
- // and intercept words by spaces.
- string = string.replaceAll("[^a-zA-Z0-9]", " ");
- string = string.toLowerCase();
- StringTokenizer stringTokenizer = new StringTokenizer(string, " ");
- //Then use the LinkedHashMap to store words and word frequency.
- while (stringTokenizer.hasMoreTokens()) {
- String word = stringTokenizer.nextToken();
- //Intercept the first letter of a word. Does a regular expression determine whether it is a number
- String first = word.substring(0, 1);
- if (!first.matches("[0-9]{1,}")) {
- //Statistical word frequency
- if (!map.containsKey(word)) {
- map.put(word, new Integer(1));
- } else {
- int newNum = map.get(word).intValue() + 1;
- map.put(word, new Integer(newNum));
- }
- }
- }
- }
- if(map.isEmpty()){
- System.out.println("The content of the text file (.txt) is empty.");
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- return map;
- }
txtToString
功能一的难点,也是后续功能二、功能三、功能四的重中之重,在这里大概花了2小时。
4、ReadTxt类中 directoryToTxt():读取文件路径,选择按字典排序最靠前的txt文件,进而调用txtToString()读取txt文件内容
- /**
- * Find the most advanced text file in the folder according to the dictionary order (.txt).
- * @param file file
- * @return return
- */
- public LinkedHashMap<String,Integer> directoryToTxt(File file){
- ArrayList<String> list = new ArrayList<String>();
- // //方法一 file.list()
- // String[] fileList = file.list();
- // for(int i=0;i<fileList.length;i++){
- // String fileName = file.getPath()+"\\"+fileList[i];
- // System.out.println("111"+fileName);
- // File mFile = new File(fileName);
- // String suffix = fileList[i].substring(fileList[i].lastIndexOf(".") + 1);
- // System.out.println("222"+suffix);
- // if(!mFile.isDirectory()&&suffix.equals("txt")){
- // System.out.println("333"+mFile.getPath());
- // list.add(mFile.getPath());
- // }
- // }
- //方法二 file.listFiles()
- //list folder
- File[] fileList = file.listFiles();
- for(int i=0;i<fileList.length;i++){
- String fileName = fileList[i].getName();
- String suffix = fileName.substring(fileName.lastIndexOf(".") + 1);
- //Is it a .txt file to add txt files to list?
- if(!fileList[i].isDirectory()&&suffix.equals("txt")){
- list.add(fileList[i].getAbsolutePath());
- }
- }
- LinkedHashMap<String,Integer> map = new LinkedHashMap<String,Integer>();
- if(!list.isEmpty()){
- Collections.sort(list);
- File finallyFile = new File(list.get(0));
- map = txtToString(finallyFile);
- return map;
- }
- else {
- System.out.println("There is no txt file in this folder!");
- return map;
- }
- }
directoryToTxt
功能二功能四的难点,要先读取文件路径,再进行后续操作,在这里大概花了1小时。
5、SortMap类中 orderPrint() : 顺序输出txt文件单词词频
- /**
- * Function one :output
- * txt file order
- * @param map map
- */
- public void orderPrint(HashMap map){
- //HashMap type data is converted to collection type, and map iterator is obtained.
- Iterator iterator = map.entrySet().iterator();
- System.out.println("total " + map.size());
- System.out.println();
- while(iterator.hasNext()){
- //Instantiate the Map.Entry object, and then output the word frequency.
- Map.Entry word = (Map.Entry) iterator.next();
- System.out.printf("%-12s",word.getKey());
- System.out.printf("%5d\n",word.getValue());
- }
- System.out.println();
- }
orderPrint
6、SortMap类中 sortMap(Map map):按字典顺序输出txt文件单词词频
- /**
- * Function two : output
- * txt files are sorted in dictionaries.
- * @param map map
- */
- public void sortMap(Map map){
- //Remove the words from map and put them in list.
- Collection<String> keys = map.keySet();
- List<String> list = new ArrayList<String>(keys);
- Collections.sort(list);
- //sort out output frequency by dictionaries
- System.out.println("total " + list.size() + " words");
- for(int i=0;i<list.size();i++){
- System.out.printf("%-12s",list.get(i));
- System.out.printf("%5d\n",map.get(list.get(i)));
- }
- System.out.println();
- }
sortMap(Map map)
7、SortMap类中 sortMap(Map map,int num):先按词频排序,再按字典顺序排序
- /**
- * Function three
- * txt file sorting
- * @param map map
- * @param num num
- */
- public void sortMap(Map map,int num){
- List<MyMap<String,Integer>> list = new ArrayList<MyMap<String,Integer>>();
- //HashMap type data is converted to collection type, and map iterator is obtained.
- Iterator iterator = map.keySet().iterator();
- while (iterator.hasNext()){
- //The words in the Map iterator are stored in list by using MyMap class.
- MyMap<String,Integer> word = new MyMap<String,Integer>();
- String key = (String) iterator.next();
- word.setKey(key);
- word.setValue((Integer) map.get(key));
- list.add(word);
- }
- //sort
- Collections.sort(list,new Compare());
- //Output word frequency
- System.out.println("Total words is " + list.size());
- System.out.println("------------------");
- //Output the specified top n word frequency.
- for(int i=0;i<num;i++){
- MyMap<String,Integer> word = list.get(i);
- System.out.printf("%-12s",word.getKey());
- System.out.printf("%5d\n",word.getValue());
- }
- System.out.println();
- }
sortMap(Map map,int num)
这三类排序方法对应功能一、功能二、功能三四的排序方法,难点在sortMap(Map map,int num) 。共花了最多时间,一直再改改改,大概15个小时,因为是几天的时间。
8、Compare类中 compare():实现Comparator接口,重写Compare方法,指定排序方法
- /**
- * override First compare word frequency, the same word frequency, and then follow the dictionary order.
- * @param o1 01
- * @param o2 02
- * @return return
- */
- public int compare(MyMap<String, Integer> o1, MyMap<String, Integer> o2) {
- if(o1.getValue().equals(o2.getValue())){
- return o1.getKey().compareTo(o2.getKey());
- }else{
- return o2.getValue()-o1.getValue();
- }
- }
compare
找资料,基本上我需要用什么就去查什么,学会百度关键词也是很重要的,这也是历届学长学姐教我的。在找资料的过程中,去搜寻别人写过的博客,看他们的代码,有涉及到的函数都要去搜索,看看它们的原理是什么,看懂以后,再自己敲一遍,印象深刻+。这也是我为什么写作业这么慢的一个原因吧......
七、PSP
| sp2.1 | 任务内容 | 计划共完成需要时间(min) | 实际完成需要的时间(min) |
| Planing | 计划 | 2160 | 4080 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 2160 | 3480 |
| Development | 开发 | 1860 | 3660 |
| Analysis | 需求分析 | 300 | 480 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审(和同事审核设计文档) | 0 | 0 |
| Coding Standard | 代码规范()为目前的开发制定合适的规范 | 0 | 0 |
| Design | 具体设计 | 300 | 480 |
| Coding | 具体编码 | 900 | 1200 |
| Code Review | 代码复审 | 120 | 300 |
| Test | 测试(自我测试,修改代码,提交修改) | 240 | 1200 |
| Reporting | 报告 | 300 | 420 |
| Test Report | 测试报告 | 180 | 300 |
|
Size Measurement Postmortem & Process Improvement Plan |
计算工作量,事后总结,并提出过程改进计划 | 120 | 120 |
| 功能模块 | 具体阶段 | 预计时间(min) | 实际时间(min) |
| 功能一 |
具体设计 具体编码 测试完善 |
30 120 150 |
80 150 400 |
| 功能二 |
具体设计 具体编码 测试完善 |
120 200 300 |
180 450 500 |
| 功能三 |
具体设计 具体编码 测试完善 |
150 200 290 |
220 600 600 |
以上只是我大概估计,因为是好几天才做出来的,难免有些不准确,但通过上面两个表格对比,能够看出,我的写代码能力真的是...... 效率太低下啦!这样子的人,有哪个公司敢要呀?即使是期间夹杂着自学,理解函数的时间,也不应该花这么多时间做作业呀。再次证明,缺实践!!!
八、总结
这次项目说实在,说简单也不简单,说难也不难,原本以为一两天就可以搞定,实际上花了整整4天时间做这个小程序。其实做这个项目我并没有完整按照构造之法的软件开发步骤去做。但在看到这个作业的时候,我会先看有什么要求,想了很多怎么分类,怎么构造方法,怎么让它们联系起来。所以我是在前期花了快8个小时的构思。接着我便开始上手敲代码,先从本类开始,判断输入格式。根据输入格式的不同,我先写直接处理txt文件的方法,把第一个功能实现,慢慢的再把第二个功能实现,一步步做下去。期间因为看着作业的布置,有些细节的地方没有注意到,导致到后面代码是改了又改,写了又写,深刻体会到程序员的痛苦(一旦用户的需求改变,就会内心奔腾吧)。
通过做这次作业,我其实感触挺大的。在之前,我一直认为,啊,我待在工作室里做了几个小项目,挺厉害的,这次作业那么简单,我肯定一两天就写完了。但其实我在做作业写代码的时间要比其他人多得多。不得不说,在实力上,我受到了一定的打击。其实我不比别人好多少,甚至别人会比我更加努力,更加厉害。
在做这个作业的时候,我其实是想实现更多的功能的,以此证明自己,也就想着慢慢写,每天写一点,总能写完,一定要细心,把作业完美的展现出来。这种想法是不对的。看我在截至时间最后一秒交作业就知道了,效率会很低下,没有紧凑感,又怎么能锻炼自己写代码的能力呢?现在这种小程序还好说,不会有什么损失。如果是以后到了公司,让你写个app,写个系统啥的,你也能保证最后交给甲方的是最完美的?所以,我要改变我的看法了,写代码这种事,是不能拖拉的。我们应该在有限的时间内写出高效代码。
最后,我想说,虽然做作业拖拉了,但总体还是比较完美的,自己花了4天写完的统计词频小程序,也让我感受到投入做一件事,努力让它变得完美,专注,钻研,这种感觉很好。同时,也让我意识到自己的实力水平远比想象中的低。我也是时候好好提升自学、写代码的能力了,勿好高骛远,踏踏实实走好每一步,加油!
软件工程 week 02的更多相关文章
- 软件工程 #02# Entity Relationship Diagram VS. 用 UML 中的类图表示 E-R 图
不同的老师叫我们画 E-R 图居然是不一样的,于是我仔细研究了一番.. 通常所说的 E-R 图(外文全称 Entity Relationship Diagram,简称 ERD)长这个样子: 而有时候它 ...
- [软件工程基础]2017.11.02 第六次 Scrum 会议
具体事项 燃尽图 每人工作内容 成员 已完成的工作 计划完成的工作 工作中遇到的困难 游心 #10 搭建可用的开发测试环境:#9 阅读分析 PhyLab 后端代码与文档:#8 掌握 Laravel 框 ...
- 软件工程(FZU2015)增补作业
说明 张老师为FZU软件工程2015班级添加了一次增补作业,总分10分,deadline是2016/01/01-2016/01/03 前11次正式作业和练习的迭代评分见:http://www.cnbl ...
- 集大1513 & 1514班 软件工程第一次作业评分与点评
谢谢大多数同学按时完成了作业,同学态度都比较端正,没有为了完成作业或者讨好老师而说一些假话空话. 很多同学选择CS之前并没有从兴趣或者擅长出发.这是一个普遍的现象,十年前我们是这样,十年后的孩子们还是 ...
- 软件工程(FZU2015) 增补作业
SE_FZU目录:1 2 3 4 5 6 7 8 9 10 11 12 13 说明 张老师为FZU软件工程2015班级添加了一次增补作业,总分10分,deadline是2016/01/01-2016/ ...
- 软件工程课堂作业(五)——终极版随机产生四则运算题目(C++)
一.升级要求:让程序能接受用户输入答案,并判定对错.最后给出总共对/错的数量. 二.设计思想: 1.首先输入答案并判断对错.我想到的是定义两个数组,一个存放用户算的结果,另一个存放正确答案.每输出一道 ...
- 软件工程第六组U-Helpβ版使用说明
软件工程第六组U-Helpβ版使用说明 U-help ——告别取件烦恼 produced by 六扇门 源代码下载地址:https://github.com/U-Help/Version-1.0 安装 ...
- BUAA_2020_软件工程_个人项目作业
作业抬头(1') 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 个人项目作业 我在这个课程的目标是 了解软件工程的技术,掌握工程化开发的能力 这 ...
- Kotlin中变量不同于Java: var 对val(KAD 02)
原文标题:Variables in Kotlin, differences with Java. var vs val (KAD 02) 作者:Antonio Leiva 时间:Nov 28, 201 ...
随机推荐
- COCO数据集格式互换
poly->compacted RLE: seg=np.array([312.29, 562.89, 402.25, 511.49, 400.96, 425.38, 398.39, 37 ...
- onchange 事件
Event 对象 定义和用法 onchange 事件会在域的内容改变时发生. 语法 onchange="SomeJavaScriptCode" 参数 描述 SomeJavaScri ...
- Maven项目下servlet异常
今天新建了一个maven项目,导入包的时候红线报错,提示程序包不存在 在网上找了几个方法试过都无效,想起idea自带提示功能,点击红色报错的地方 同时按下Alt+Enter键,选择add maven ...
- 谈谈如何给下拉框option添加点击事件?
我们在用到下拉列表框select时,需要对选中的<option>选项触发事件,其实<option>本身没有触发事件方法,我们只有在select里的onchange方法里触发. ...
- js获取css样式封装
封装 function getStyle(obj , attr){ return obj.currentStyle?obj.currentStyle[attr]:getComputedStyle(ob ...
- elementUI
开始学习elementUI了. 怎么可以快速的学习一个UI框架,是我们的值得思考的事情. 博客,重点,记忆. <el-button @click="visible = true&quo ...
- haoop fs 命令
Hadoop fs 命令详解 参考文档:https://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-common/FileSy ...
- HTML辅助方法
顾名思义,HTML辅助方法(HTML Helper)就是用来辅助产生HTML之用,在开发View的时候一定会面对许多HTML标签,处理这些HTML的工作非常繁琐,为了降低View的复杂度,可以使用HT ...
- Luffy之购物车页面搭建
前面已经将一些课程加入购物车中,并保存到了后端的redis数据库中,此时做购物车页面时,我们需要将在前端向后端发送请求,用来获取数据数据 购物车页面 1.首先后端要将数据构建好,后端视图函数如下代码: ...
- css实现响应式布局的相关内容
所以我就在做自适应的时候查了一些资料 首先我发现一个问题:有响应式布局和自适应布局两种布局效果 简单来说,响应式布局就是不同的设备无论大小 布局都自动调整大小 页面布局都一样 可以保证无论什么设备 用 ...