PythonStudy——阶段总结
- 每个数据类型的最大特点是什么?
(1)int整型:用于存放整形对象,是不可变类型。若将一个整数赋值给一个变量名,python可自动将其设置为int型。
例如:age = 30 这里的age对象的type即为 int。
(2)float浮点型:用于存放浮点型对象,是不可变类型。若将一个浮点数(带小数点的数)赋值给一个变量名,python可自动将其设置为float型。
例如:angle = 45.0 这里的angle(角度)对象的type即为 float。
(3)str字符串类型:用于存放字符串型对象,是不可变类型。一切以单引号、双引号、复合引号表达的字符赋值给一个对象,其类型始终为str。另外,在py3中,input()函数默认返回一个字符串赋值给变量,是我们常用的键入字符串的方法。
(4)bool布尔型:常见的形式是True、False,又因为其是由整型的子类实现的,所以他们在逻辑判断表达式中常常会以1或0(真或假)的形式存在。主要用于逻辑判断。
Python内部数据从某种形式上可以分为两种:
原子性数据类型:int,float,str
非原子性的(按有序性分):
有序的:list, tuple
无序的:set, dict
# int、float、complex、str类型的定义(使用内置方法)及之间的转化:
int(x [,base]) 将x转换为一个整数
float(x ) 将x转换到一个浮点数
complex(real [,imag]) 创建一个复数
str(x) 将对象x转换为字符串
eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s) 将序列s转换为一个元组
list(s) 将序列s转换为一个列表
chr(x) 将一个整数转换为一个字符
unichr(x) 将一个整数转换为Unicode字符
ord(x) 将一个字符转换为它的整数值
repr(x) 将对象x转换为表达式字符串
bin(x) 将一个整数转换为一个二进制字符串
hex(x) 将一个整数转换为一个十六进制字符串
oct(x) 将一个整数转换为一个八进制字符串
list 、tuple 、dict 、set 四大集合(容器)数据类型:
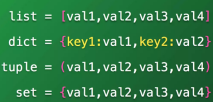
str 字符串类型:
方法:

- list 列表:
定义方法:
(1)直接定义 :用逗号分隔的不同的数据项使用方括号“[ ]”括起来即可创建列表。
例如:list_1 = [1,2,3]
list_2 = [] # 定义一个空的list
List_3 = [1, ‘a’, [ 2 , ’b’ ] ] # 允许一次性循环嵌套定义
(2)调用定义函数 list()
源码:list() -> new empty list # 直接返回一个空的列表
如:list_1 = list() print(list_1) 输出:[ ]
list(iterable) -> new list initialized from iterable's items
使用一个可迭代对象进行新列表构造
如: list_2 = list(“abcd”[:]) 输出:['a', 'b', 'c', 'd']
方法:
list.append(x): 在列表的末尾添加元素x,等价于a(len(a):) = [x]。
list.extend(L): 在列表末尾加入指定列表L中所有的元素,
等价于a[len(a):] = L 或 a+L:把一个列表合并到另外一个列表里面
list.insert(i,X): 在给定的位置添加元素,也就是在位置i插入x,其余元素依次向后退list.remove(x): 移除列表中值为 x 的元素,如果没有x就会报错。
list.pop([i]):删除列表中指定位置i的元素,并返回该元素。
若不指定索引值(list.pop),则移除并返回列表中的最后一个元素。
list.clear(): 删除列表中所有的元素,等价于:del a[:]
list.index(x):返回列表中值为x的位置索引,若不存在就会出错。
list.count(x):返回x在列表中出现的次数。
list.sort(key=None,reverse=False):对列表中的元素排序,默认为升序。
list.reverse():将列表中的元素顺序反转。
list.copy(): 返回列表的浅复制(返回的也是列表),等价于 a[:]
注意:上面的 insert(),list.remove(),sort()方法仅仅是修改列表而不返回修改的结果,即返回值为默认的值 None
索引取值:list[index] 返回值是列表索引位置上的元素
s1 = [1, 3, 2]
print(s1[0]) # 输出:1
print(s1[-1]) # 输出:2
切片:
list1[start : end : step] 以指定步长切片位置索引为start-end的子列表
返回一个新的字列表(为可迭代对象)
list_2 = [1,2,3,4,5,6,7]
print(list_2[0:7:1])
# 输出:[1, 2, 3, 4, 5, 6]
求长度:len(list) 返回列表长度(int型)
拼接: list_1 + list_2 返回一个新的拼接后的列表
list_1 = [ 1, 2 ]
list_2 = [ 3, 4 ]
print(list_1 + list_2)
# 输出:[ 1 , 2 , 3 , 4]
复制:list * num 返回一个新的累加后的列表
list_1 = [ 1, 2 ]
print(list_1 * 5)
# 输出: [1, 2, 1, 2, 1, 2, 1, 2, 1, 2]
删除:del(index) 删除列表中位置索引为i的元素,无返回值
最大值: max(list1) 返回列表中最大的值
TypeError: '>' not supported between instances of 'dict' and 'int'
TypeError: '>' not supported between instances of 'str' and 'int'
TypeError: '>' not supported between instances of 'set' and 'int'
TypeError: '>' not supported between instances of 'tuple' and 'int'
数字和数字之间比较值,以上类型无法转化为数字。
最小值:min(list1) 返回列表中最小的值,注意事项同上。
特点:
(1)可以存放多个元素,元素类型可任意
(2)有序(index),可按索引取值
(3)可变类型,内部元素可替换
(4)List 可直接变为tuple、set
注:由于tuple、set是由list发展而来的,所以有list所没有的方法和特性。
构造(Cpython底层实现):
参考:
http://python.jobbole.com/82549/
https://blog.csdn.net/Yuyh131/article/details/83592608
Python中list是用底层的C语言的结构来表示的。ob_item是用来保存元素的指针数组,allocated是ob_item预先分配的内存总容量。
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
可以看出list列表是由对其它对象的引用组成的连续数组。指向这个数组的指针及其长度被保存在一个列表头结构中。这意味着,每次添加或删除一个元素时,由引用组成的数组需要该标大小(重新分配)。幸运的是,Python在创建这些数组时采用了指数分配,所以并不是每次操作都需要改变数组的大小。但是,也因为这个原因添加或取出元素的复杂度较低。在CPython中,列表被实现为长度可变的数组。
不幸的是,在普通链表上“代价很小”的其它一些操作在Python中计算复杂度相对过高。
利用 list.insert方法在任意位置插入一个元素——复杂度O(n),指针偏移
利用 list.delete或del删除一个元素——复杂度O(N),指针偏移
List的算法效率: (O括号里面的值越大代表效率越低)
可以采用时间复杂度来衡量:
index() O(1)
append O(1)
pop() O(1)
pop(i) O(n)
insert(i,item) O(n)
del operator O(n)
iteration O(n)
contains(in) O(n)
get slice[x:y] O(k)
del slice O(n)
set slice O(n+k)
reverse O(n)
concatenate O(k)
sort O(nlogn)
multiply O(nk)
可以说,list是python中最强大集合(容器)数据类型,兼容性非常强,是tuple的鼻祖。
- tuple 元组:(只读列表)
元组是不可以改变的,创建后不能再做任何的修改。元组的主要作用是作为参数传递给函数调用或者从函数调用那里获得参数时,保护其内容不被外部接口修改(数据保护)(类比Java封装)。
定义方法:
(1)直接定义
tuple_1 = (1,2,3)
t = ‘a’ , ’b’ , ’c’ print(t) # 输出:('a', 'b', 'c') 元组打包(tuple packing)
u = t,(1,2,3,4,5) # 元组允许嵌套
# 输出:(('a', 'b', 'c', 'd'), (1, 2, 3, 4, 5))
tuple = 'hello', print(tuple)
# 加逗号后,tuple实际上是包含一个元素'hello'的元组
# 输出: ('hello',)
(2)调用定义函数 tuple_1 = tuple()
源码:
tuple() -> empty tuple
tuple(iterable) -> tuple initialized from iterable's items
从可迭代的项初始化元组
元组的基本操作:
tup[i] 求索引为i的元素
tup[i:j:k] 切片求tup的位置索引为i~j~k的子元组
tup1 + tup2 将 tup1与tup2连接
tup * 2 或者 2* tup 将 tup复制2次
len(tup) 求tup的长度
for <var> in tup 对tup元素循环
del tup 删除元组
max(tup) 返回元组中最大的值
min(tup) 返回元组中最小的值
cmp(tup1,tup2) 比较两个元组元素
不能向元组增加元素,元组没有append或extend方法
不能从元组删除元素,元组没有remove或pop方法
不能在元组中查找元素,元组没有index方法
概括:
元组没有增删改,只有查找。
但是,元组内的可变对象的值是可以增删改查的。
——tuple.index(obj): 从元组中找出某个值第一个匹配项的索引值
tuple_2 = 'hello',1,3,
print(tuple_2.index(3)) # 输出: 2
——tuple.count(obj): 统计某个元素在元组中出现的次数
tuple_2 = 'hello',1,3,1,
print(tuple_2.count(1)) # 输出: 2
List 与 tuple的 对比:
list:list底层也是用数组实现,与str不同的是,list的数组储存的不是对象本身,而是对象的引用,这种数组叫做引用型结构(referential array)。也因为list是引用型数组,所以list可以存储任何对象。(实际上list存储的是引用)。每次创建一个新list对象,会分配比需要多一些的内存,以供list的增加(append,extend)之用。如果一个list对象的内存占满了还要继续增加,Python就会开辟一块新内存,然后把之前的复制过来,让引用指向新的内存。list是mutable的含义是其中每个元素的内容(引用)可以改变,这样对于单个元素的更改就不必像str一样开辟新内存。
tuple:tuple也是引用型数组,与list的不同是tuple是immutable(不可变类型)。
参考:Data Structures and Algorithms in Python, WILEY
- dict 字典类型
字典包含了一个索引的集合,称为键和值的集合。
key:value一一对应,这种关系称为键值对或称为项。
简单地说,字典就是用花括号包裹的键值对的集合。
dict可以存放多个值
通过已知的key对value进行取值
key为不可变类型,value为任意类型
无索引,无序
为可变类型
每个键值对用冒号“:”分割,每对之间用逗号“,”分割
定义方法:
(1)直接定义 :
dict1 = {'key1':'1','key2':'2'}
dict2 = {} # 创建空字典
(3)调用定义函数 dict()
dict_1 = dict([('sape',3429),('guido',2890),('jack','190)]) print(dict_1)
# 输出:{'sape': 3429, 'guido': 2890, 'jack': '190'}
构造方法源码:
dict() -> new empty dictionary
# 新的空字典
dict(mapping) -> new dictionary initialized from a mapping object's(key, value) pairs
# 从映射对象(键、值)对初始化的新字典
dict(iterable) -> new dictionary initialized as if via:
d = {}
for k, v in iterable:
d[k] = v
#用可迭代对象新字典初始化
dict(**kwargs) -> new dictionary initialized with the name=value pairs
in the keyword argument list. For example: dict(one=1, two=2)
# 使用key = value初始化的新字典。例如:dict(1 =1, 2 =2)
实现细节:
CPython使用伪随机探测(pseudo-random probing)的散列表(hash table)作为字典的底层数据结构。由于这个实现细节,只有可哈希(hashable)的对象才能作为字典的键。
Python中所有不可变的内置类型都是可哈希的。
可变类型(如list,dict和set)就是不可哈希(unhashable)的,因此不能作为字典的键。
dict中建立的hash表如下:
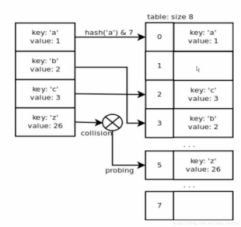
hash表的查询:
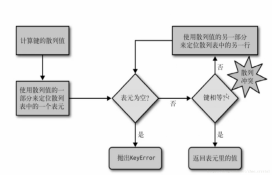
注意点:
(1) dict的key 或者 set的值都必须是可hash的。
不可变对象:都是可hash的,有str,fronzenset, tuple, 自己实现的类(带有__hash__魔法函数)
(2) dict的内存花销大(hash简单的来说即映射,如图1所示,映射之后,不可能是连续的存在内存空间中的,总有一些内存时空的,当发现内存空间中的“空”只有1/3时,便会触发扩容操作,以免引起hash冲突),但是查询速度快。自定义的对象,或者python内部的对象都是dict包装的。
(3)dict的存储顺序和元素的添加顺序有关
(4)添加的数据有可能改变已有的数据顺序(扩容时,需要将原来的dict,复制移动到新的内存空间,此时将“挤出”已有的“空”,所以每个key的偏移可能改变)
dict 与 list 对比:
(1)dict的查找性能远远大于list
(2)在list中,随着list数据量的增大,查找的时间也会增大; 在 dict中,查找元素的时间不会随着数据量的增大而增大,其时间复杂度为O(1)
方法:
dict.keys() 返回包含字典所有key的列表
dict.values 返回包含字典所有.value的列表
dict.items() 返回包含所有(键,值)项的列表
dict.clear() 删除字典中所有的项或元素,无返回值
dict.copy() 返回字典浅复制副本
dict.get(key,default=None) 返回字典中key对应的值,若key不存在,则返回default的值(default默认为None)
dict.pop(key[,default]) 若字典中存在key,则删除并返回key对应的value;如果key不存在,且没有给出default值,则引发KeyError异常 dict.setdefault(key,default=None) 若字典中不存在key,则由dict[key]=default为其赋值
dict.update(dict2) 将字典dict2中的键值对添加到字典dict中
官方文档:



字典的缺点和替代方案:
使用字典的常见陷阱就是,它并不会按照键的添加顺序来保存元素的顺序。在某些情况下,字典的键是连续的,对应的散列值也是连续值(例如整数),那么由于字典的内部实现,元素的实现可能和添加的顺序相同。
- set 集合类型:
集合是一种鲁棒性很好的数据结构,当元素顺序的重要性不如元素的唯一性和测试元素是否包含在集合中的效率时,大部分情况下这种数据结构极其有用。
定义方法:
创建新集合:
set_1={,}
由字符串创建:用函数 set(str) 将str中的字符拆开以形成集合。
s1 = set('helloPython')
# 输出: {'h', 'e', 'l', 'n', 'y', 'o', 'P', 't'}
由列表或元组创建:用函数set(seq)创建集合,参数可以是列表或元组。
s1 = set([1,'name',2,'age','hobby'])
# 输出: {1, 2, 'hobby', 'age', 'name'}
s2 = set((1,2,3))
# 输出:{1, 2, 3}
由于集合内部存储的元素是无序的,因此输出顺序和原列表的顺序有可能是不同的。
set 与 dict、list的对比:
集合(set)是不重复元素的无序集,它兼具了列表和字典的一些性质。
集合类似字典的特点:
用花括号“{}”来定义,其元素是非序列类型的数据,也就是没有序列,并且集合中的元素不可重复,也必须是不变对象,类似于字典中的键。
集合的内部结构与字典很相似,区别是“只有键没有值”。另一方面,集合也具有一些列表的特点:
持有一系列元素,并且可原处修改。
由于集合是无序的,不记录元素位置或者插入点,因此不支持索引、切片或其他类序列的操作。
实现细节:
CPython中集合和字典非常相似。事实上,集合被实现为带有空值的字典,只有键才是实际的集合元素。此外,集合还利用这种没有值的映射做了其它的优化。
由于这一点,可以快速的向集合中添加元素、删除元素、检查元素是否存在。平均时间复杂度为O(1),最坏的事件复杂度是O(n)。
set()去重的原理:
set的去重是通过两个函数__hash__和__eq__结合实现的。
1、当两个变量的哈希值不相同时,就认为这两个变量是不同的
2、当两个变量哈希值一样时,调用__eq__方法,当返回值为True时认为这两个变量是同一个,应该去除一个。返回FALSE时,不去重。
方法:


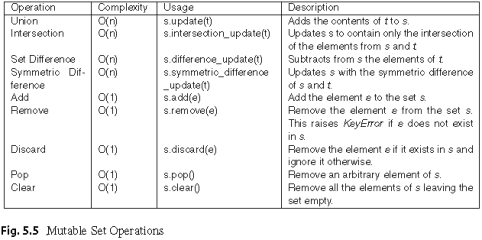
dict与set的实现原理:
dict与set实现原理是一样的,都是将实际的值放到list中。唯一不同的在于hash函数操作的对象,对于dict,hash函数操作的是其key,而对于set是直接操作的它的元素,假设操作内容为x,其作为因变量,放入hash函数,通过运算后取list的余数,转化为一个list的下标,此下标位置对于set而言用来放其本身,而对于dict则是创建了两个list,一个list该下表放此key,另一个list中该下标方对应的value。
其中,我们把实现set的方式叫做Hash Set,实现dict的方式叫做Hash Map/Table(注:map指的就是通过key来寻找value的过程)
set() ----> Hash Set
dict() ----> Hash Map/Table
2,哪些数据类型之间可以相互转换,以及转换的方式或方法?
字符串转换成整数 int(s,[base])
>>> int('1001',2)
9
>>> int('FF', 16)
255
>>> int('23', 8)
19
>>> int('12', 5)
7
字符串转浮点数 float(s)
>>> e = float('3.14159')
>>> e
3.14159
>>> type(e)
<type 'float'>
数值类型转字符串 str(X)
>>> str(3.14149)
'3.14149'
>>> str(123456)
'123456'
>>> str(add)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'add' is not defined
>>> str(123L)
'123'
列表或字符串转元组 tuple(s) s可以为列表或字符串
>>> tuple([1, 3, 5])
(1, 3, 5)
>>> tuple('Hello World')
('H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd')
>>> tuple(123)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>>
元组或字符串转列表 list(s) s可以为元组或字符串
>>> list((1, 2, 3))
[1, 2, 3]
>>> list('Hello')
['H', 'e', 'l', 'l', 'o']
>>> list(abc)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'abc' is not defined
>>> list(123)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
到集合的转换 set(l) l可以为列表,元组或字符串
>>> set([11, 3, 7])
set([3, 11, 7])
>>> set((11, 3, 7))
set([3, 11, 7])
>>> set('Hello')
set(['H', 'e', 'l', 'o'])
>>> set(123)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
到字典的转换 dict(s) s必须是以键值对的形式组合的列表或元组
>>> dict([('name', 'xiao'), ('age', 28)])
{'age': 28, 'name': 'xiao'}
>>> dict((('name', 'xiao'), ('age', 28)))
{'age': 28, 'name': 'xiao'}
>>> dict((['name', 'xiao'], ['age', 28]))
{'age': 28, 'name': 'xiao'}
>>> dict('age', 28)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: dict expected at most 1 arguments, got 2
>>> dict(['age', 28])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: dictionary update sequence element #0 has length 3; 2 is required
>>> dict([('age', 28)])
{'age': 28}
>>> dict((('age', 28)))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: dictionary update sequence element #0 has length 3; 2 is required
>>> dict([['age', 28]])
{'age': 28}
3. utf-8,utf-16两种的存储数据方式,都在哪运用?为什么要这么做?
utf-8:
英文:1个字符存放
汉字:3|6个字节存放,
大量数据交互和延迟影响的情况下,utf-8相对于utf-16以2个字节存放英文,在传输的时候效率会更高,更节省空间
utf-16:
所有符号都是以2个字节在存放,读取数据都是以固定2个字节来读取,不用再次计算,读取的时候效率会更高
PythonStudy——阶段总结的更多相关文章
- 【基于WPF+OneNote+Oracle的中文图片识别系统阶段总结】之篇一:WPF常用知识以及本项目设计总结
篇一:WPF常用知识以及本项目设计总结:http://www.cnblogs.com/baiboy/p/wpf.html 篇二:基于OneNote难点突破和批量识别:http://www.cnblog ...
- 你真的会玩SQL吗?之逻辑查询处理阶段
你真的会玩SQL吗?系列目录 你真的会玩SQL吗?之逻辑查询处理阶段 你真的会玩SQL吗?和平大使 内连接.外连接 你真的会玩SQL吗?三范式.数据完整性 你真的会玩SQL吗?查询指定节点及其所有父节 ...
- Openfire阶段实践总结
从3月开始研究Openfire,其实就是要做一套IM系统,也正是这个原因才了解到Openfire.之前还真没想过有这么多的开源产品可以做IM,而且也没想到XMPP这个协议竟然如何强大.看来还是标准为先 ...
- 【Win 10应用开发】分阶段进行数据绑定
使用x:Bind扩展标记进行数据绑定,是在编译阶段完成,至于说性能优化方面,大概主要是优化CPU资源的使用,因为免去了运行阶段进行绑定的过程.当然,使用这个标记仅仅是绑定上的优化,并不包括数据源.数据 ...
- 【基于WPF+OneNote+Oracle的中文图片识别系统阶段总结】之篇二:基于OneNote难点突破和批量识别
篇一:WPF常用知识以及本项目设计总结:http://www.cnblogs.com/baiboy/p/wpf.html 篇二:基于OneNote难点突破和批量识别:http://www.cnblog ...
- 【基于WPF+OneNote+Oracle的中文图片识别系统阶段总结】之篇三:批量处理后的txt文件入库处理
篇一:WPF常用知识以及本项目设计总结:http://www.cnblogs.com/baiboy/p/wpf.html 篇二:基于OneNote难点突破和批量识别:http://www.cnblog ...
- 【基于WPF+OneNote+Oracle的中文图片识别系统阶段总结】之篇四:关于OneNote入库处理以及审核
篇一:WPF常用知识以及本项目设计总结:http://www.cnblogs.com/baiboy/p/wpf.html 篇二:基于OneNote难点突破和批量识别:http://www.cnblog ...
- 阶段一:用Handler和Message实现计时效果及其中一些疑问
“阶段一”是指我第一次系统地学习Android开发.这主要是对我的学习过程作个记录. 本来是打算继续做天气预报的优化的,但因为某些原因,我要先把之前做的小应用优化一下.所以今天就插播一下用Handle ...
- 阶段一:为View设置阴影和弹出动画(天气应用)
“阶段一”是指我第一次系统地学习Android开发.这主要是对我的学习过程作个记录. 上一篇阶段一:通过网络请求,获得并解析JSON数据(天气应用)完成了应用的核心功能,接下来就要对它进行优化.今天我 ...
随机推荐
- angular-cli.json配置参数解释,以及依稀常用命令的通用关键参数解释
一. angular-cli.json常见配置 { "project": { "name": "ng-admin", //项目名称 &quo ...
- galera+mycat高可用集群部署
环境描述 10.30.162.29 client 环境描述 10.30.162.29 client 10.30.162.72 mysql1 10.30.162.73 mysql2 10.30.162 ...
- Docker:bash: vi: command not found
在使用docker容器时,有时候里边没有安装vim,敲vim命令时提示说:vim: command not found,这个时候就需要安装vim 操作步鄹: 1.apt-get update 2.ap ...
- 基于虹软的Android的人脸识别SDK使用测试
现在有很多人脸识别的技术我们可以拿来使用:但是个人认为还是离线端的SDK比较实用:所以个人一直在搜集人脸识别的SDK:原来使用开源的OpenCV:最近有个好友推荐虹软的ArcFace, 闲来无事就下来 ...
- vxlan中vtep角色,以及通过GRE隧道进行流镜像
1. 交换机上建立gre隧道,对端ip为ip12. 交换机上报gre隧道的OF逻辑端口port id,这里gre tunnel的id实际就是OF逻辑端口id3. 控制器建立流ipflow1的镜像配置, ...
- linux软件管理之rpm管理rpm包
使用RPM工具管理RPM包 ====================================================================================需要 ...
- 7.10 其他面向对象设计原则1: 开-闭原则OCP
其他面向对象设计原则1: 开-闭原则OCP Open-Closed Principle (OCP)5.1 设计变坏的前兆 Signs of Rotting Design 僵硬性 Rigidit ...
- windows service 2008 R2 安装net4.6环境失败,windows service 2008 R2 升级sp1问题
一.错误 1.因为我的程序是以vs2017开发的,在windows service 2008 R2 IIS部署项目文件报出错误,因此要安装net4.6的环境. 2.windows service 2 ...
- Shiro集成web环境[Springboot]-认证与授权
Shiro集成web环境[Springboot]--认证与授权 在登录页面提交登陆数据后,发起请求也被ShiroFilter拦截,状态码为302 <form action="${pag ...
- 实践:搭建基于Load Balancer的MySql Cluster
服务器规划: 整套系统全部在rhel5u1 server 64位版本下,由基于xen的虚拟机搭建,其中集群管理节点*2.SQL节点*2.数据节点*4.Web服务节点*2组成,其中数据节点做成2个组,每 ...