Hbase rowkey设计+布隆过滤器+STORE FILE & HFILE结构
Rowkey设计
Rowkey设计原则
Rowkey设计应遵循以下原则:
1.Rowkey的唯一原则
必须在设计上保证其唯一性。由于在HBase中数据存储是Key-Value形式,若HBase中同一表插入相同Rowkey,则原先的数据会被覆盖掉(如果表的version设置为1的话),所以务必保证Rowkey的唯一性
2. Rowkey的排序原则
HBase的Rowkey是按照ASCII有序设计的,我们在设计Rowkey时要充分利用这点。比如视频网站上对影片《泰坦尼克号》的弹幕信息,这个弹幕是按照时间倒排序展示视频里,这个时候我们设计的Rowkey要和时间顺序相关。可以使用"Long.MAX_VALUE - 弹幕发表时间"的 long 值作为 Rowkey 的前缀
3. Rowkey的散列原则
我们设计的Rowkey应均匀的分布在各个HBase节点上。拿常见的时间戳举例,假如Rowkey是按系统时间戳的方式递增,Rowkey的第一部分如果是时间戳信息的话将造成所有新数据都在一个RegionServer上堆积的热点现象,也就是通常说的Region热点问题, 热点发生在大量的client直接访问集中在个别RegionServer上(访问可能是读,写或者其他操作),导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用,常见的是发生jvm full gc或者显示region too busy异常情况,当然这也会影响同一个RegionServer上的其他Region。
通常有3种办法来解决这个Region热点问题:
ΩΩ1、Reverse反转
针对固定长度的Rowkey反转后存储,这样可以使Rowkey中经常改变的部分放在最前面,可以有效的随机Rowkey。
反转Rowkey的例子通常以手机举例,可以将手机号反转后的字符串作为Rowkey,这样的就避免了以手机号那样比较固定开头(137x、15x等)导致热点问题,
这样做的缺点是牺牲了Rowkey的有序性。
ΩΩ2、Salt加盐
Salting是将每一个Rowkey加一个前缀,前缀使用一些随机字符,使得数据分散在多个不同的Region,达到Region负载均衡的目标。
比如在一个有4个Region(注:以 [ ,a)、[a,b)、[b,c)、[c, )为Region起至)的HBase表中,
加Salt前的Rowkey:abc001、abc002、abc003
我们分别加上a、b、c前缀,加Salt后Rowkey为:a-abc001、b-abc002、c-abc003
可以看到,加盐前的Rowkey默认会在第2个region中,加盐后的Rowkey数据会分布在3个region中,理论上处理后的吞吐量应是之前的3倍。由于前缀是随机的,读这些数据时需要耗费更多的时间,所以Salt增加了写操作的吞吐量,不过缺点是同时增加了读操作的开销。
ΩΩ3、Hash散列或者Mod
用Hash散列来替代随机Salt前缀的好处是能让一个给定的行有相同的前缀,这在分散了Region负载的同时,使读操作也能够推断。确定性Hash(比如md5后取前4位做前缀)能让客户端重建完整的RowKey,可以使用get操作直接get想要的行。
例如将上述的原始Rowkey经过hash处理,此处我们采用md5散列算法取前4位做前缀,结果如下
9bf0-abc001 (abc001在md5后是9bf049097142c168c38a94c626eddf3d,取前4位是9bf0)
7006-abc002
95e6-abc003
若以前4个字符作为不同分区的起止,上面几个Rowkey数据会分布在3个region中。实际应用场景是当数据量越来越大的时候,这种设计会使得分区之间更加均衡。
如果Rowkey是数字类型的,也可以考虑Mod方法。
布隆过滤器在HBase中的应用
在讨论布隆过滤器在HBase中的应用之前,先介绍一下HBase的块索引机制。块索引是HBase固有的一个特性,因为HBase的底层数据是存储在HFile中的,而每个HFile中存储的是有序的<key, value>键值对,HFile文件内部由连续的块组成[1],每个块中存储的第一行数据的行键组成了这个文件的块索引,这些块索引信息存储在文件尾部。当HBase打开一个HFile时,块索引信息会优先加载到内存;HBase首先在内存的块索引中进行二分查找,确定可能包含给定键的块,然后读取磁盘块找到实际想要的键。
但实际应用中,仅仅只有块索引满足不了需求,这是因为,块索引能帮助我们更快地在一个文件中找到想要的数据,但是我们可能依然需要扫描很多文件。而布隆过滤器就是为解决这个问题而生。因为布隆过滤器的作用是,用户可以立即判断一个文件是否包含特定的行键,从而帮我们过滤掉一些不需要扫描的文件。如下图所示,块索引显示每个文件中都可能包含对应的行键,而布隆过滤器能帮我们跳过一些明显不包含对应行键的文件。
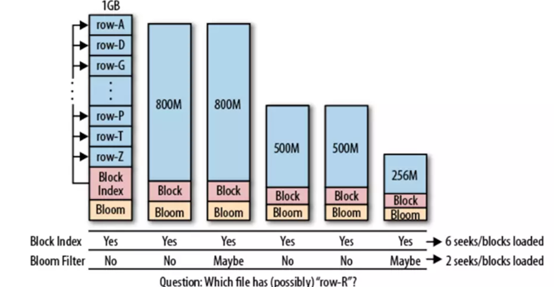
减少不必要的文件查找.png
如上图所示,布隆过滤器不能明确指出哪一个文件一定包含所查找的行键,布隆过滤器的结果有误差存在。当布隆过滤器判断文件中不包含对应的行时,这个答案是绝对正确的;但是,当布隆过滤器判断得到文件中包含对应行时,这个答案却有可能是错的。也就是说,HBase还是有可能加载了不必要的块。尽管如此,布隆过滤器还是可以帮助我们跳过一些明显不需要扫描的文件。另外,错误率可以通过调整布隆过滤器所占空间的大小来调整,通常设置错误率为1%。
需要注意的是,使用布隆过滤器,并不一定能立即提升个别的get操作性能,因为同一时间可能有多个客户端向HBase发送请求,当负载过大时,HBase的性能受限于读磁盘的效率。但是,使用了布隆过滤器之后,可以减少不必要的块加载,从而可以提高整个集群的吞吐率。并且,因为HBase加载的块数量少了,缓存波动也降低了,进而提高了读缓存的命中率。
然而,相比与布隆过滤器的优点,它的缺点显得如此微不足道,就是需要占用少量的存储空间。
在使用布隆过滤器时,需要注意两个问题:
- 什么时候应该使用布隆过滤器?根据上面的描述,布隆过滤器的主要作用,是帮助HBase跳过那些显然不包括所查找数据的底层文件。那么,当所查找的数据均匀分布在所有文件中(当用户定期更新所有行时,就可能导致这种情况),布隆过滤器的作用就微乎其微,反而浪费了存储空间。相反,如果我们查找的数据只包含在少部分的文件中,就应该果断使用布隆过滤器。
- 应该选择行级还是行加列级布隆过滤器?很显然,行加列级因为粒度更细,占用的存储空间也就越多。因此,如果用户总是读取整行的数据,行级布隆过滤器就够用了。在可以选择的情形下,尽可能使用行级布隆过滤器,因为它在额外的空间开销和利用过滤存储文件提升性能之间取得了更好的平衡。
注[1]: 注意这里的块不是HDFS的块,HBase块的默认大小是64KB。可以根据需要配置不同的大小,对于顺序访问较多的表,建议使用较大的块;随机访问较多的表,建议使用较小的块。
STORE FILE & HFILE结构
StoreFile以HFile格式保存在HDFS上。
附:HFile的格式为:
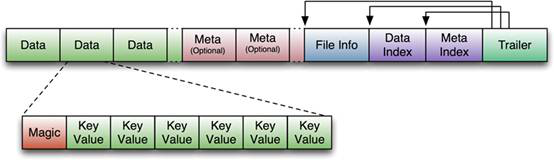
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer中有指针指向其他数 据块的起始点。
File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。
Data Index和Meta Index块记录了每个Data块和Meta块的起始点。
Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是 RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
HFile分为六个部分:
Data Block 段–保存表中的数据,这部分可以被压缩
Meta Block 段 (可选的)–保存用户自定义的kv对,可以被压缩。
File Info 段–Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index 段–Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
Meta Block Index段 (可选的)–Meta Block的索引。
Trailer–这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先 读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
目标Hfile的压缩支持两种方式:Gzip,Lzo。
Hbase rowkey设计+布隆过滤器+STORE FILE & HFILE结构的更多相关文章
- HBase Rowkey 设计指南
为什么Rowkey这么重要 RowKey 到底是什么 我们常说看一张 HBase 表设计的好不好,就看它的 RowKey 设计的好不好.可见 RowKey 在 HBase 中的地位.那么 RowKey ...
- Hbase Rowkey设计
转自:http://www.bcmeng.com/hbase-rowkey/ 建立Schema Hbase 模式建立或更新可以通过 Hbase shell 工具或者使用Hbase Java API 中 ...
- Hbase Rowkey设计原则
Hbase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这三个维度可以对HBase中的数据进行快速定位 ...
- Hbase rowkey设计一
转自 http://blog.csdn.net/lifuxiangcaohui/article/details/40621067 hbase所谓的三维有序存储的三维是指:rowkey(行主键),col ...
- HBase总结(十八)Hbase rowkey设计一
hbase所谓的三维有序存储的三维是指:rowkey(行主键),column key(columnFamily+qualifier),timestamp(时间戳)三部分组成的三维有序存储. 1.row ...
- hbase rowkey 设计
HBase中的rowkey是按字典顺序排序的,通过rowkey查询可以对千万级的数据实现毫秒级响应.然而,如果rowkey设计不合理的话经常会出现一个很普遍的问题----热点.当大量client的请求 ...
- hbase rowkey设计的注意事项
充分利用有序性 1.1 如果要scan操作,且不是很频繁,可以利用rowkey的有序性将需要一起扫描的数据放到一起.例如直接用时间戳.这样就可以按时间scan了.这个只要是简单的全表扫描都行. 1.2 ...
- HBase的rowkey设计(含实例)
转自:http://www.aboutyun.com/thread-7119-1-1.html 对于任何系统的数据设计,我们都想提高性能,达到资源最大化利用,那么对于hbase我们产生如下问题: 1. ...
- 布隆过滤器(Bloom Filter)原理以及应用
应用场景 主要是解决大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等. 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的 ...
随机推荐
- C# --- ??(空接合操作符)的一个案例
Nullable<Int32> x = null; Nullable<Int32> y = null; Nullable<Int32> z = null; Int3 ...
- Orchard是如何呈现内容的
首先Orchard是一个建立在ASP.NET MVC框架上的CMS应用框架.Orchard在呈现内容的时候也遵循MVC的规律,也是通过Controller来处理Url请求并决定用那个View来呈现那种 ...
- Python自学:第二章 Python之禅
>>print import <Python之禅>,提姆·彼得斯著 美胜于丑. 显式优于隐式. 简单胜于复杂. 复杂总比复杂好. 平的比嵌套的好. 稀疏胜于稠密. 可读性计数. ...
- .NET:bin 与 obj,Debug 与 Release ,区别与选择
bin 与 obj bin 目录:用来存放编译的结果. ( bin是二进制binrary的英文缩写,因为最初C编译的程序文件都是二进制文件 ) 编译的结果,有 Debug 和 Release 两个版本 ...
- css3-盒模型display:-webkit-box;的使用
提到移动布局不得不提到盒模型display:-webkit-box;这个属性,在移动布局中浮动已经不在重要,相反自适应成为主要的需求,所以display:-webkit-box;变得尤为重要. box ...
- 双列集合Map
1.双列集合Map,就是存储key-value的键值对. 2.hashMap中键必须唯一,值可以不唯一. 3.主要方法:put添加数据 getKey---通过key获取数据 keySet- ...
- mysql和mariadb支持insert delayed的问题
分析一个开源项目,往数据库里添加日志,为了避免写入日志信息影响正常业务,日志的插入方式采用了insert delayed的方式. 打印其数据库语句,复制到mysql执行报如下错误: ERROR 161 ...
- STL 小白学习(2) string
#include <iostream> using namespace std; #include <string> //初始化操作 void test01() { //初始化 ...
- བྱ་དེ་ཁྲུང་ཁྲུང་དཀར་པོ།།--洁白的仙鹤/仓央嘉措情歌--IPA--藏语
<<洁白的仙鹤>>, 也就是大家熟悉的仓央嘉措情歌之一.
- linux基本网络配置
-- linux基本网络配置管理 rhel6开始有一个networkmanger的网络配置服务(可以图形配置网络,拔号,无线连接,vpn等)但此服务开启会造成你的ip不固定(会dhcp获取),而且后期 ...