Flume架构
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统:
Flume 介绍
Flume是由cloudera软件公司产出的高可用、高可靠、分布式的海量日志收集系统、聚合和传输的系统、于2009年被捐赠了apache软件基金会,为Hadoop相关组件之一。Flume初始发行版本目前统称为Flume OG,2011年10月在完成了里程碑的改动:重构核心组件、核心配置以及代码架构之后、Flume NG 推出,它是Flume1.X版本的统称。
Apache Flume 是一个系统,用于从大量数据产生商那里移动海量数据到存储、索引或者分析数据的系统,它可以将数据的消费者和是生产者解耦,是的在一方不知情的情况下改变另外一方变得很容易,除了解耦还可而已提供故障隔离,并在生产商和存储系统之间添加一个额外的缓冲区,Flume支持在日志系统中定制各类数据的发送方,用于收集数据,如控制台、文件、Thrift—RPC、syslog日志系统等,也支持对数据进行简单的处理,并发送到各种数据接收方,如HDFS、Hbase等。
备注:Flume参考资料
官方网站: http://flume.apache.org/
用户文档: http://flume.apache.org/FlumeUserGuide.html
开发文档: http://flume.apache.org/FlumeDeveloperGuide.html
Flume 的特点
可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store
on
failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
flume的可恢复性
靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
Flume 架构
Client
生产数据,运行在一个独立线程
Event
Flume将数据表示成Event,数据结构很简单,具有一个主题和一个报头的集合、事件的主题是一个字节数组,通常通过Flume传送的负载。报头被称为一个map,其中有字符串key和字符串value,报头不是用来传输数据的,而是为了路由和跟踪发送事件的优先级和严重性。报头也可以用给事件增加事件ID或者UUUID。每个事件本质上必须是一个独立的记录,而不是记录的一部分。这也要求每个事件要适应Flume
Agent JVM的内存,如果使用File Channel
应该有足够的硬盘空间来支持。如果数据不能表示为多个独立记录,Flume可能不适用于这样的案例。
Agent
Flume运行的核心是Agent,Agent本身是一个Java进程,也是最小独立运行的单位,运行在日志收集节点Agent是一个完整的数据收集工具,含有三个核心组件,分别是Source、Channel、Sink,Flume基于数据流将进行设计,数据流由事件(Event)贯穿始终。事件作为Flume的基本数据单位,携带日志数据(以字节数组形式)并且携带有头信息,由Agent
外部的数据源如图中的Web Server 生成。
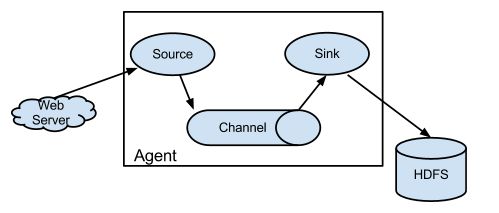
Source
Source是从一些生产数据的应用中接收数据的活跃组件。也有自己产生数据的Source,不过通常用于测试目的。Source可以监听一个或者多个网络端口,用于接收数据或者可以从本地文件系统读取数据,每一个Source必须至少链接一个Channel。基于一些标准,一个Source可以写入多个Channel,复制事件到所有或者部分的Channel。flume提供了很多内置的Source,
支持 Avro, log4j, syslog 和 http post(body为json格式)
| Source类型 | 描述 |
|---|---|
| Avro | 支持Avro协议,即Avro RPC,内置支持 |
| Thrift | 支持Thrift协议,内置支持 |
| Exec | 基于Unix的命令在标准输出上产生数据 |
| JMS | 从 JMS系统中读取数据 |
| Spooling Directory | 监控指定目录内数据变化 |
| Netcat | 监控某个端口,将流经端口的文本行数据作为Event输入 |
| Sequence Gennerator | 序列生产器的数据源,生产序列数据 |
| Syslog | 读取syslog数据,产生Event,支持UDP和TCP协议 |
| HTTP | 基于HTTP POST 或者GT 方式的数据源,支持JSON等格式 |
| Legacy | 兼容Flume OG 中的Source(0.9 x 版本) |
Avro源
| 属性名 | 默认值 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 类型名称Avro |
| bind | - | 需要监听的主机名或者ip |
| port | - | 需要监听端口 |
| threads | - | 工作线程最大线程数 |
| selector.type | ||
| selector.* | ||
| interceptors | - | 空格分隔的拦截器地址 |
| interceptors.* | ||
| compression-type | none | 压缩类型必须和AvroSource值相同 |
| ssl | false | 是否启用ssl加密同时还要配置keystroe和keystore-password |
| keystore | - | 为SSL提供java密钥文件所在路径 |
| keystore-password | – | 为SLL提供的java密钥文件 密码 |
| keystore-type | JKS | 密钥库类型可以是“JKS”或者”PKCS12” |
| exclude-protocols | SSLv3 | 空格指定分开的列表,用来指定在SSL/TLS协议中排除。SSLv3将总是被排除除了所指定的协议 |
| ipFilter | false | 如果需要为netty开启ip过滤,将此选项设置为true |
| ipFilterRules | – | 配netty的ip过滤设置表达式规则 |
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
exec 源
| 属性名 | 默认值 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 类型名称 exec |
| command | - | 要执行的命令 |
| shell | - | 用于执行命令的shell |
| restartThrottle | 1000 | 毫秒为单位,用于声明等待多久后尝试重试命令 |
| restart | false | 如果cmd挂了是否重启cmd |
| logStdErr | false | 无论是否是标准错误都应该被记录 |
| batchSize | 20 | 同时发送到通道中的最大行数 |
| batchTimeout | 3000 | 如果缓冲区没有满,经过多长时间发送数据 |
| selector.type | 复制还是多路复制 | |
| selector.* | 依赖于selector.type的值 | |
| interceptors | - | 空格分隔的拦截器列表 |
| interceptors.* |
示例:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
Channel
Channel一般地被认为是被动的组件,负责缓存Agent已经接收但尚未写出到另外一个Agent或者存储系统的数据,虽然他们可以为了清理或者垃圾回收运行自己的线程。Channel的行为很像是队列,Source把数据写入到他们,Sink从他们中读取数据,多个Source可以安全地写入到相同的Channel,并且多个Sink可以从相同的Channel进行读取,一个Sink只能从一个Channel,多个Sink可以从相同的Channel读取,它可以保证只有一个Sink 会从Channel读取一个指定的事件。
| Channel类型 | 描述 |
|---|---|
| Memory | Event数据存储在内存中 |
| JDBC | Event数据存储在持久化存储中 |
| File | Event数据存储在磁盘文件中 |
| Spilable Memory | Event数据存储在内存和硬盘上,当内存队列已满,将持久化到磁盘文件(不建议生产环境使用) |
| Pseudo Transaction | 测试用途 |
| Customm | 自定义 |
memory Channel
| 属性名称 | 默认值 | 描述 |
|---|---|---|
| type | – | 名称memory |
| capacity | 100 | 存储在channel中的最大容量 |
| transactionCapacity | 100 | 从一个source中去或者给一个sink,每个事务中最大的事件数 |
| keep-alive | 3 | 对于添加或者删除一个事件超时的秒钟 |
| byteCapacityBufferPercentage | 20 | 对于添加或者删除一个事件的超时的秒钟 |
| byteCapacity | see description | 最大内存所有事件允许的总字节数 |
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
JDBC Channel
Sink
连续轮询各自的Channel来读取和删除事件,Sink将事件提送到下一阶段,(RPC Sink 的情况下,)活到最终目的地.一旦在下一阶段或其目的地中的数据是安全的,Sink通过的事务提交通知Channel,可以从Channel中删除这些事件。
| Sink类型 | 描述 |
|---|---|
| HDFS | 数据写入HDFS |
| Hbase | 数据写入HBase |
| Logger | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Avro | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC | 数据在IRC上进行回收 |
| File Roll | 数据存储到本地文件系统 |
| Null | 丢弃所有数据 |
| Morphine Solor | 数据发送到Solr搜索服务器(集群) |
| ElasticSearch | 数据发送到ElasticSearch搜索服务器(集群) |
| Custome sink | 自定义 |
HDFS sink
| channel | - | 描述 |
|---|---|---|
| type | - | HDFS |
| hdfs.path | - | 写入hdfs的路径,需要包含文件系统表示,比如:hdfs://namenode/flume/webdata/ 可以使用flume提供日期及%{host}表达式 |
| hdfs.filePrefix | FlumeData | 写入hdfs的文件名前缀,可以使用flume提供的日期及%{host}表达式 |
| hdfs.fileSuffix | - | 写入hdfs的文件名后缀,比如:: .lzo .log |
| hdfs.inUsePrefix | - | 临时文件的文件名前缀,hdfs sink 会先往 目标目录中写临时文件再根据相关规则重命名成最终文件 |
| hdfs.inUseSuffix | .tmp | 临时文件的后缀名 |
| hdfs.rollInterval | 30 | hdfs sink 间隔多长时间将临时文件滚动成最终文明考吗,再根据相关的明明规则重命名为最终目标文件 |
| hdfs.rollSize | 1024 | 当临时文件达到该大小(单位:bytes)时,滚动成为目标文件,如果设置成0,则表示不根据临时文件大小来滚动文件 |
| hdfs.rollCount | 10 | 当events数据达到该数量时候,将临时文件滚动成为目标文件;如果设置为0,则表示部根据临时文件大小来滚动该文件 |
| hdfs.idleTimeout | 0 | 当目前被打开的临时文件在该参数指定的事件秒内没有任何数据写入,则将该临时文件关闭并重新命名。 |
| hdfs.batchSize | 100 | 每个批次刷新到hdfs上的events 数量 |
| hdfs.codeC | - | 文件的压缩格式,包括:gzip,bzip lzo lzop snappy |
| hdfs.fileType | SequenceFile | 文件格式 包括:SequenceFile, DataStream ,CompressedStream,当使用DataStream的时候,文本不会被压缩,不需要设置hdfs.codeC,当使用CompressedStream的时候必须设置一个正确的hdfs.codeC的值 |
| hdfs.maxOpenFiles | 5000 | 最大允许打开的HDFS文件数,当打开的文件数到达该值,最早打开的文件将会被关闭 |
| hdfs.minBlockReplicas | - | 写入HDFS文件块的最小副本数,该参数会影响文件的滚动配置,一般将该参数设置成1,才可以按照配置正确滚动文件。 |
| hdfs.writeFormat | Writable | 写入sequence文件的格式。包括:Text Writable(默认) |
| hdfs.callTimeout | 10000 | 执行HDFS操作的超时时间(单位:毫秒) |
| hdfs.threadsPoolSize | 10 | hhdfs sink 启动的操作 HDFS的线程数 |
| hdfs.rollTimerPoolSize | 1 | HDFS sink 启动的根据事件滚动文件的线程数 |
| hdfs.kerberosPrincipal | - | HDFS 安全认证kerberos配置 |
| hdfs.kerberosKeytab | - | HDFS 安全认证kerberos配置 |
| hdfs.proxyUser | 代理用户 | |
| hdfs.round | false | 是否启用时间上的“舍弃”,这里的“舍弃”类似于“四舍五入”后面在介绍。如果启用,则会很影响除了除了%t的其他所有时间的表达式。 |
| hdfs.roundValue | 1 | 时间上进行舍弃的值 |
| hdfs.roundUnit | second | 单位值 -秒 分 时 |
| hdfs.timeZone | Local Time | 解析文件路径的时区名称,例如:美国/洛杉矶 |
| hdfs.closeTries | 0 | hdfs sink 关闭文件的尝试次数;如果设置为1,当一次关闭文件失败后,hdfs sink 将不会在尝试关闭文件,这个为未关闭的文件,将会一直留在那,并且时打开状态,设置为0,当一次关闭失败后,hdfs sink会继续尝试下一次关闭,直到成功 |
| hdfs.retryInterval | 180 | hdfs sink 尝试关闭文件的时间间隔,如果设置为0,表示不尝试,相当于将hdfs.closeTries设置为1 |
| serializer | TEXT | 序列化类型。其他的还有:avro_event或者是实现了EventSerializer.Builder的类名 |
| serializer.* |
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
分区和拦截器
大型的数据集常常被组织为分区(Partition),这样做的好处是,如果查询仅涉及到数据集的某个子集,查询过程就可以被限制在特定的分区范围内。Flume 事件的数据通常按时间件来分区,因此,我们可以定期运行某个进程来对已经完成分区进行各种数据转换处理(例如,删除重复的数据)
agent.sinks.sink1.hdfs.path=/tmp/flume/year=%Y/month=%m/day=%d
此处,我们选择天作为分区粒度,不过也可是使用其他级别的分区粒度,结果将导致不同的文件目录布局方案,在Flume与HDFS sink相关的文件提供了格式转义序列的完整,一个Flume时间将被写入那个分区是由时间的header中的timestamp(时间戳)决定的,在默认的情况下 事件header 并没有timestamp,但是他可以通过Flume 拦截器(interceptor)来添加,拦截器是一种能够对事件流中的事件进行修改或者删除的组件,他们连接source并在事件被传递到channel之前对时间进行处理。下面的两行卑职用于source1增加一个时间拦截器,它将为source产生的每个时事件添加一个timestamp header:
agent1.sources.source1.interceptors = interceptor1
agent1.sources.source1.interceptors = interceptor1.type = timestamp
事件拦截器可以确保这些是时间戳能够如实反映事件穿件的事件,对于某些数据由时间戳就已经足够了,如果存在多层Flume多层代理,那么事件事件的创建事件和吸入的事件之间可能会存在有明显的差异,尤其是当代理出现停机的情况,针对这种情况我们可以对HDFS sink 中的hdfs。useLocalTimeStamp属性进行设置,以便使用用HDFS Sink的Flume 代理所产生的时间戳。
文件格式
一般而言,使用二进制来存储数据比使用文本格式的文件更小 HDFS sink使用的文件格式由hdfs.fileAType属性及其他一些属性的组合控制。
默认的Hdfs.fileType文件格式为SequenceFile,把事件写入到一个顺序文件,在这个文件中,键的数据类型为LongWritable,它包括的是事件的时间戳(如果事件的header中没有时间戳,就使用当前事件)。值得数据类型为BytesWritable,其中包含的是事件的body。如果hdfs.writeFormat被设置为Text,那么顺序文件中的值就变成Text数据类型
针对Avro文件所使用的配置;収不同它的Hdfs。filetype的属性被设置为DataStream,就像纯文本一样,此外,serializer(之一前面没有前缀hdfs.)必须设置为avro_event。如果想要启动压缩则需要设置serializer.compressionCodes属性。
扇出
指的是从一个source向多个channel,亦即向多个sink传递事物。
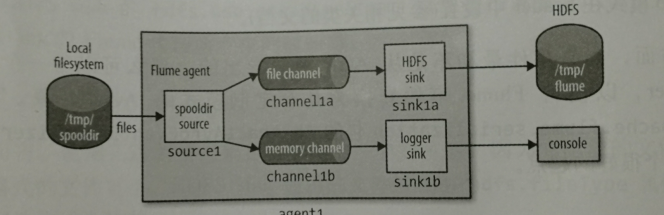
案例演示:将事件同时传递到HDFS sink和logger sink。 注意:如上图channel1a,sink1a是到达HDFS,channel1b,sink1b是到达logger agent1.sources = source1
agent1.sinks= sink1a sink1b #多个sink,中间用空格
agent1.channels=channel1a channel1b #多个channel中间同样空格分割
agent1.sources.source1.channels = channnel1a channel1b
agent1.sinks.sink1a.channnel = channel1a
agent1.sinks.sink1b.channnel =channel1b
agent1.sources.source1.type = spoodir
agnet1.sources.source1.spooDir = /tmp/spooldir
agent1.sinks.sink1a.type =hdfs
agent1.sinks.sink1a.hdfs.path=/tmp/flume
agent1.sinks.sink1a.hdfs.fileType = DataStream #默认类型是SequenceFile,顺序文件,dataStream类似纯文本。
agent1.channels.channel1a.type =file
agent1.channels.channel1b.type = memory #注意:上面两个channel配置类型不一样,一个是file,一个是memory。如果同一个机器上,配置两个channel都是file channel。
那么则必须要通过配置使得它们分别指向不同的数据存储目录和检查点目录(因为默认情况下,filechannel 具有持久性,数据会被写入到本地系统,
而默认情况下file channel写入的目录都是用户主目录中的同一个默认文件夹),否则会出现数据重叠覆盖的情况。
交付保证
Flume 使用独立的事物来负责从Spooling Directory source到每一个channel的每批事件的传递,在本例中有一个事物负责从source到链接HDFS sink 的channel的事件交付,另外一个负责从source到链接logger sink的channel 的同一批事件的交付,若其中有任何一个事物失败(例如 channel满溢),这些事件都不会从source中删除,而是等待稍后重试。
复用和复用选择器
正常扇出流是向所有的channel复制事件,但有些时候,人们有更多的行为方式选择,从而使某些事件被发送到这一个channel,而另外一些事件被发送到另外一个channel。
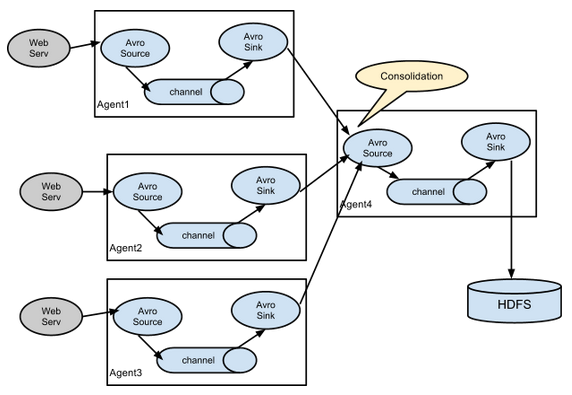
Flume的拓扑结构
lume Agent连接

单source,多channel、sink

Flume负载均衡

Flume Agent聚合
Flume架构的更多相关文章
- flume架构初接触
flume优点 1.存储数据到任何中央数据库 2.进入数据速率大于写出速率,可以起到缓存作用,保证流的平稳 3.提供文本式路由 4.支持事务 5.可靠.容错.可伸缩.可定制.可管理 put的缺点 1. ...
- 海量日志采集系统flume架构与原理
1.Flume概念 flume是分布式日志收集系统,将各个服务器的数据收集起来并发送到指定地方. Flume是Cloudera提供的一个高可用.高可靠.分布式的海量日志采集.聚合和传输的系统.Flum ...
- Flume架构以及应用介绍[转]
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出 ...
- Flume架构以及应用介绍
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引 ...
- hadoop flume 架构及监控的部署
1 Flume架构解释 Flume概念 Flume是一个分布式 ,可靠的,和高可用的,海量的日志聚合系统 支持在系统中定制各类的数据发送方 用于收集数据 提供简单的数据提取能力 并写入到各种接受方 ...
- Flume架构及运行机制
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用.Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 clo ...
- 1.1-1.5 flume架构概述及安装使用
一.flume架构概述 1.flume简介 Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据.它具有基于流数据流的简单灵活的架构.它具有可靠的可靠性机制和许多故障转移和 ...
- Flume架构以及应用介绍(转)
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出 ...
- flume 架构设计优化
对于企业中常用的flume type 概括如下:ource(获取数据源): exec (文件) spoolingdir (文件夹) taildir(文件夹及文件的变动) kafka syslog ht ...
随机推荐
- NFS服务与crond服务
NFS服务:用于linux系统之间,基于TCP/IP协议层,可以将远程的计算机磁盘挂载到本地,像本地磁盘一样操作. ------------------------------------------ ...
- python之函数入门
python之函数入门 一. 什么是函数 二. 函数定义, 函数名, 函数体以及函数的调用 三. 函数的返回值 四. 函数的参数 五.函数名->第一类对象 六.闭包 一,什么是函数 函数: 对代 ...
- redis-cluster配置
为什么要用redis-cluster 1.并发问题 redis官方生成可以达到 10万/每秒,每秒执行10万条命令假如业务需要每秒100万的命令执行呢? 2.数据量太大 一台服务器内存正常是16~25 ...
- Oracle数据库统一审核的启用测试与关闭
环境:windows server 2008.Oracle 12c R2 下面的步骤,连接为sysdba,除非指定了其它方式. (1)运行如下查询,确定统一审核是否启用了: select value ...
- centos7.4 可远程可视化桌面安装
先啰嗦一下VNC是什么( Virtual Network Computing)VNC允许Linux系统可以类似实现像Windows中的远程桌面访问那样访问Linux桌面.本文配置机器是兴宁市网络信息中 ...
- 关于maven环境变量的配置问题
开始使用“MAVEN_HOME”配置完环境变量后,在cmd中输入mvn -v提示不是内部命令,后直接在PATH 路径里面添加maven所在的位置+\bin,比如,maven的路径为E:\maven\a ...
- angular5理解生命周期
先来看下文档: 按照顺序有八个: 1.ngOnChanges()=>简单理解为当数据绑定输入属性的值发生变化时调用: 2.ngOnInit() => 在调用完构造函数.初始化完所有输入属性 ...
- 100道Java基础面试题收集整理(附答案)
不积跬步无以至千里,这里会不断收集和更新Java基础相关的面试题,目前已收集100题. 1.什么是B/S架构?什么是C/S架构 B/S(Browser/Server),浏览器/服务器程序 C/S(Cl ...
- Dubbo透传traceId/logid的一种思路
前言: 随着dubbo的开源, 以及成为apache顶级项目. dubbo越来越受到国内java developer欢迎, 甚至成为服务化自治的首选方案. 随着微服务的流行, 如何跟踪整个调用链, 成 ...
- des加密破解
在爬取某些网站时, 登录等重要操作的返回结果是des加密后的. 如何破解 1, Python 语言采用 pyDes 作为 DES 加解密处理的包. 2,通过请求 http://tool.chacuo. ...