论文阅读笔记(二十三)【ECCV2018】:Robust Anchor Embedding for Unsupervised Video Person Re-Identification in the Wild
Introduction
当前主要的非监督方法都采用相同的训练数据集,这些数据集在不同摄像头中是对称的,即不存在单个行人的错误项,这些方法将在实际场景中效果下降。在本方法中,作者引入了非对称数据,如下图所示,提出了一个在真实环境下的非监督深度神经网络。

提出一个标签估计方法:a novel Robust Anchor Embeding (RACE) framework。
Proposed Method
(1)概述:

通俗来说,先固定几个序列,给这几个序列加上标签作为anchor,然后输入一个未标签序列,找出距离最近的若干个anchor,用这些anchor加权表示出这个未标签序列,这样既得到了相似距离又得到了权重,我们希望距离越近越好,权重越大越好,综上计算出最佳的anchor,作为预测的标签,循环这个过程得到所有的标签。
(2)Anchor初始化:
【注】anchor表示不同行人的身份,但在假设下并不严谨,两个anchor也可能属于同一个人。
随机抽选 m 个anchor序列  传入预训练的ImageNet模型,分别表示不同的行人,即:
传入预训练的ImageNet模型,分别表示不同的行人,即: ,其中
,其中 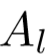 表示帧级特征向量的集合,l 表示对应的初始化标签。
表示帧级特征向量的集合,l 表示对应的初始化标签。
在本文中,采用classification loss(Person re-identification: Past, present and future. 提出)来作为训练的基础结构。【待阅读】
(3)标签估计:
① 鲁棒的Anchor嵌入方法:
定义未标签的视频序列为: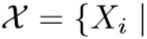
 。初始的帧级特征向量集合采用平均池化或者最大池化转化为单向量特征。考虑到一些帧存在跟踪偏差,即产生了离群帧(outlier frame),作者采用了regularized affine hull(RAH,From point to set: Extend the learning of distance metrics提出)【待阅读】,理解为对帧进行加权,得到 d 维的特征向量,即:
。初始的帧级特征向量集合采用平均池化或者最大池化转化为单向量特征。考虑到一些帧存在跟踪偏差,即产生了离群帧(outlier frame),作者采用了regularized affine hull(RAH,From point to set: Extend the learning of distance metrics提出)【待阅读】,理解为对帧进行加权,得到 d 维的特征向量,即:
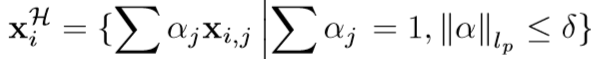
对于标签估计,首先学习embedding向量(姑且叫做嵌入向量)wi, 用于衡量未标签的特征序列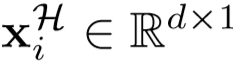 和anchor集合
和anchor集合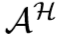 间的关系。学习到第 i 个未标签序列的最近的 k 个anchors,即
间的关系。学习到第 i 个未标签序列的最近的 k 个anchors,即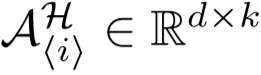 ,k 远远小于 m,用这 k 个anchors来联合表示该未标签序列,即定义如下系数学习问题(Robust AnChor Embeding问题,RACE):
,k 远远小于 m,用这 k 个anchors来联合表示该未标签序列,即定义如下系数学习问题(Robust AnChor Embeding问题,RACE):

该公式的第一项为embedding term,旨在限制未标签项与anchors之间的差异;
第二项为smoothing term,旨在权重越大的anchor距离越近,其中 d<i> 为相似度,理解为到各个anchor的距离,⊙ 为对应元素相乘,该项计算为:
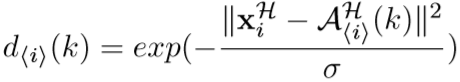
RACE问题将高维的CNN表征转为低维的权重映射,来降低算力损耗。
该问题为标准二次规划问题,优化方法:
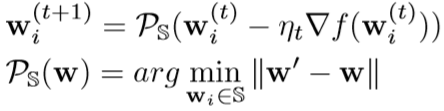
具体求解见:
Efficient projections onto the l 1-ball for learning in high dimensions
Large graph construction for scalable semi-supervised learning
From point to set: Extend the learning of distance metrics
【待阅读】
(4)top-k count 标签估计:
如果两个视频序列属于同一个行人,那么它们在不同的衡量维度上需要非常接近。具体来说,如果未标签序列 xi 属于行人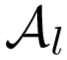 ,需要满足两个条件:
,需要满足两个条件:
① 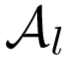 应当是距离 xi 最近的部分anchor之一,定义为:
应当是距离 xi 最近的部分anchor之一,定义为: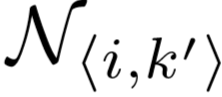 ;
;
② 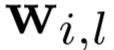 应当足够大。
应当足够大。
定义预测的标签为:
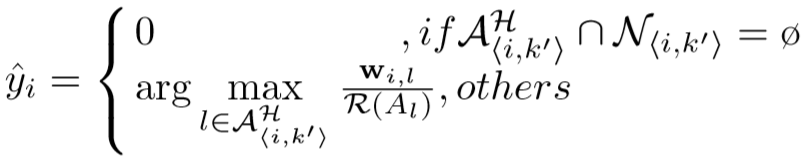
其中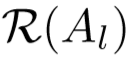 表示
表示 在
在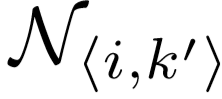 中的排名。
中的排名。
【疑问:已经是最近的 k 个最近的anchor了,为什么还要判断是不是最近的 k' 个?】
Experimental Results
(1)实验设置:
① 数据集:PRID-2011,iLIDS-VID,MARS;
② 参数设置:dropou = 0.5;图片resize = 128*256;learning rate(MARS)= 0.003,learning rate(PRID-2011, iLIDS-VID) = 0.01,并每20个epoch下降0.1;k = 15,k’ = 1;λ = 0.1。
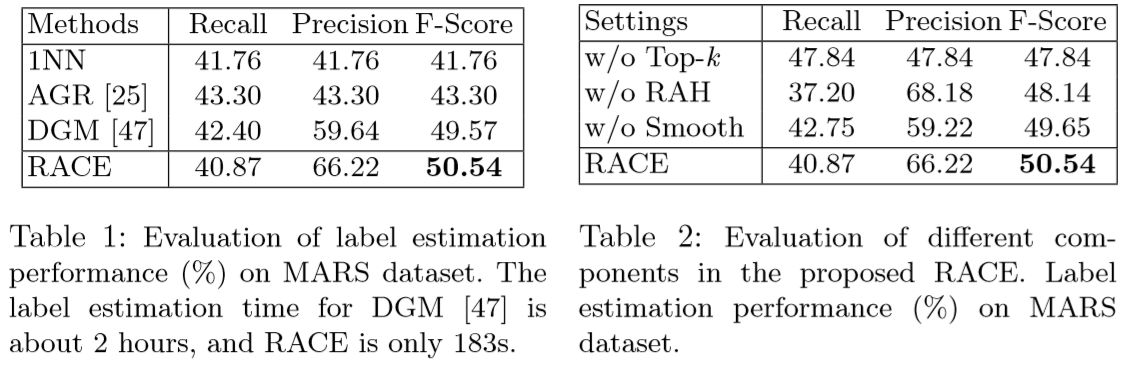
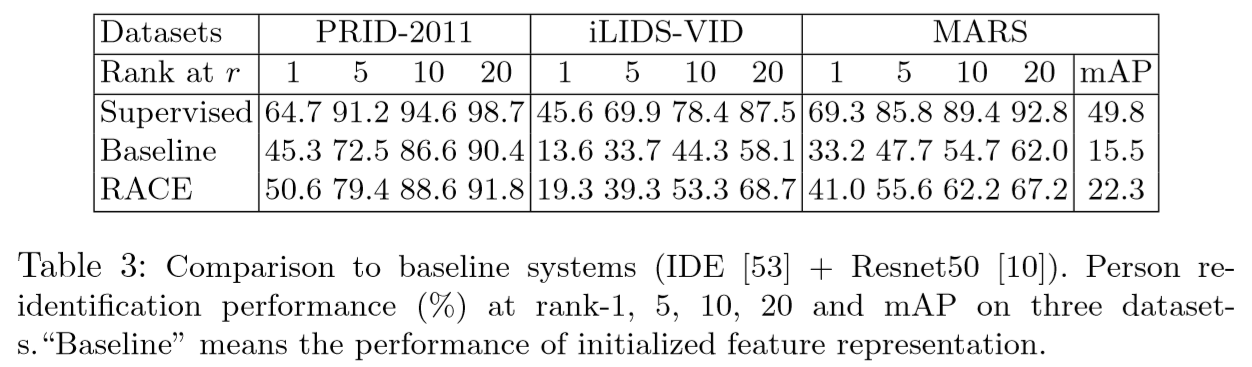
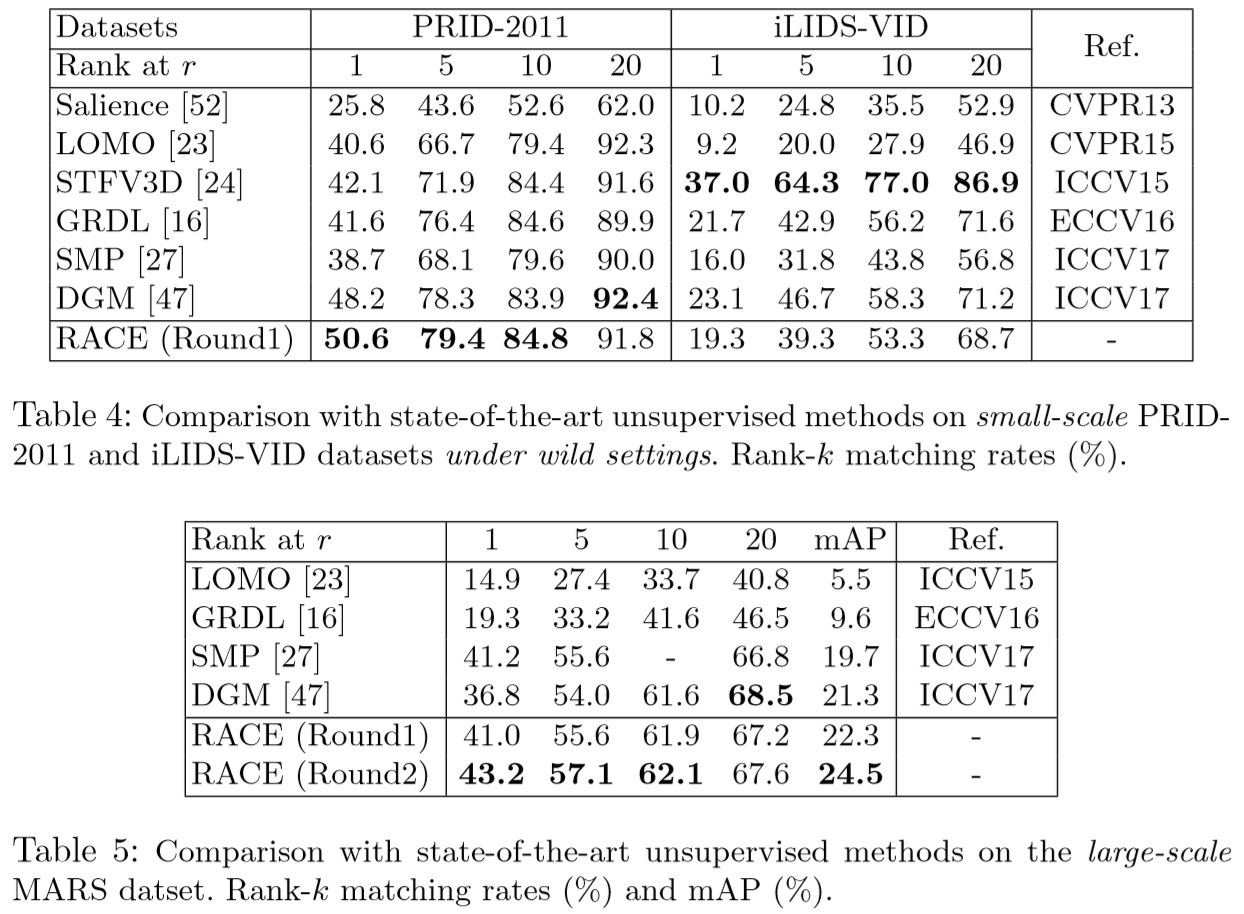
(2)实验结果:
论文阅读笔记(二十三)【ECCV2018】:Robust Anchor Embedding for Unsupervised Video Person Re-Identification in the Wild的更多相关文章
- 论文阅读笔记二十三:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR2017)
论文源址:https://arxiv.org/abs/1709.04609 摘要 该文提出了基于深度学习的实例分割框架,主要分为三步,(1)训练一个基于ResNet-101的通用模型,用于分割图像中的 ...
- 论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)
论文源址:https://arxiv.org/abs/1506.01497 tensorflow代码:https://github.com/endernewton/tf-faster-rcnn 室友对 ...
- 论文阅读笔记三十三:Feature Pyramid Networks for Object Detection(FPN CVPR 2017)
论文源址:https://arxiv.org/abs/1612.03144 代码:https://github.com/jwyang/fpn.pytorch 摘要 特征金字塔是用于不同尺寸目标检测中的 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- 论文阅读笔记二十一:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS(ICRL2016)
论文源址:https://arxiv.org/abs/1511.07122 tensorflow Github:https://github.com/ndrplz/dilation-tensorflo ...
- 论文阅读笔记六十三:DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling(CVPR2017)
论文原址:https://arxiv.org/abs/1703.10295 github:https://github.com/lachlants/denet 摘要 本文重新定义了目标检测,将其定义为 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- 论文阅读笔记四十三:DeeperLab: Single-Shot Image Parser(CVPR2019)
论文原址:https://arxiv.org/abs/1902.05093 github:https://github.com/lingtengqiu/Deeperlab-pytorch 摘要 本文提 ...
随机推荐
- DISCUZ 如何为主题帖列表页添加头像,显示发帖者头像
只显示名字的代码 ```php<em style=" font-size:14px;"> <!--{if $thread['authorid'] &&am ...
- 理解和运用Java中的Lambda
前提 回想一下,JDK8是2014年发布正式版的,到现在为(2020-02-08)止已经过去了5年多.JDK8引入的两个比较强大的新特性是Lambda表达式(下文的Lambda特指JDK提供的Lamb ...
- 🔥SpringBoot图文教程2—日志的使用「logback」「log4j」
有天上飞的概念,就要有落地的实现 概念+代码实现是本文的特点,教程将涵盖完整的图文教程,代码案例 文章结尾配套自测面试题,学完技术自我测试更扎实 概念十遍不如代码一遍,朋友,希望你把文中所有的代码案例 ...
- 使用小书匠及markdown here编辑博客和微信公众号
1. 使用小书匠连接Evernote并发布笔记到博客园 1.1 小书匠初探 我平时的信息收集的主要方法是采用Pocket+Evernote. 简单来说: 如果访问到非常有用,而且是必须要立刻记录的内容 ...
- ThinkPHP5.1学习笔记 数据库操作
数据库 参见<Thinkphp5.1完全开发手册>学习 Mirror王宇阳 数据库连接 ThinkPHP采用内置抽象层对数据库操作进行封装处理:且基于PDO模式,可以适配各种数据库. 数据 ...
- Vscode开发Python环境安装
VSCode 开发 Python 使用python,主要是做一些工具和爬虫的操作,语法简单,功能复杂,入手很快. 我们通过在 VSCode 中搜索 Python 插件,发现,开发 python 的话, ...
- TCP协议可靠性是如何保证之滑动窗口,超时重发,序列号确认应答信号
原创文章首发于公众号:「码农富哥」,欢迎收藏和关注,如转载请注明出处! TCP 是一种提供可靠性交付的协议. 也就是说,通过 TCP 连接传输的数据,无差错.不丢失.不重复.并且按序到达. 但是在网络 ...
- 自己用C语言写NXP S32K116 serial bootloader
了解更多关于bootloader 的C语言实现,请加我QQ: 1273623966 (验证信息请填 bootloader),欢迎咨询或定制bootloader(在线升级程序). 每次我有了新的EVA ...
- finalshell连接工具
FinalShell功能特点: 1.多平台支持Windows,Mac OS X,Linux2.多标签,批量服务器管理.3.支持登录Ssh和Windows远程桌面.4.漂亮的平滑字体显示,内置100多个 ...
- 《自拍教程29》Sublime_小脚本编写首选
Sublime Sublime 是一个轻量.简洁.高效.跨平台的编辑器, 最新的是Sublime Text 3. Sublime对Python支持非常好,如果只是简单的编写批处理脚本编写, 或者小范围 ...