spark编程入门-idea环境搭建
原文引自:http://blog.csdn.net/huanbia/article/details/69084895
1、环境准备
idea采用2017.3.1版本。
创建一个文件a.txt

2、构建maven工程
点击File->New->Project…
点击Next,其中GroupId和ArtifactId可随意命名

点击Next
点击Finish,出现如下界面:
3、书写wordCount代码
请在pom.xml中的version标签后追加如下配置
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2-beta-5</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<maniClass></maniClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.3.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>false</includeProjectDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.dt.spark.SparkApps.App</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId> <configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>
点击右下角的Import Changes导入相应的包

点击File->Project Structure…->Moudules,将src和main都选为Sources文件
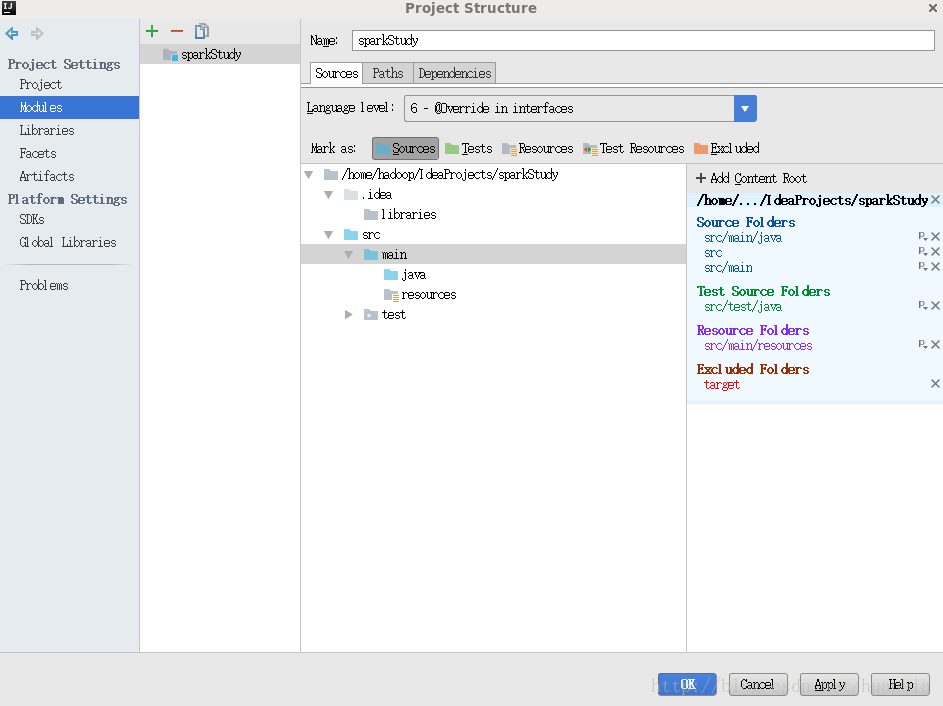
在java文件夹下创建SparkWordCount java文件
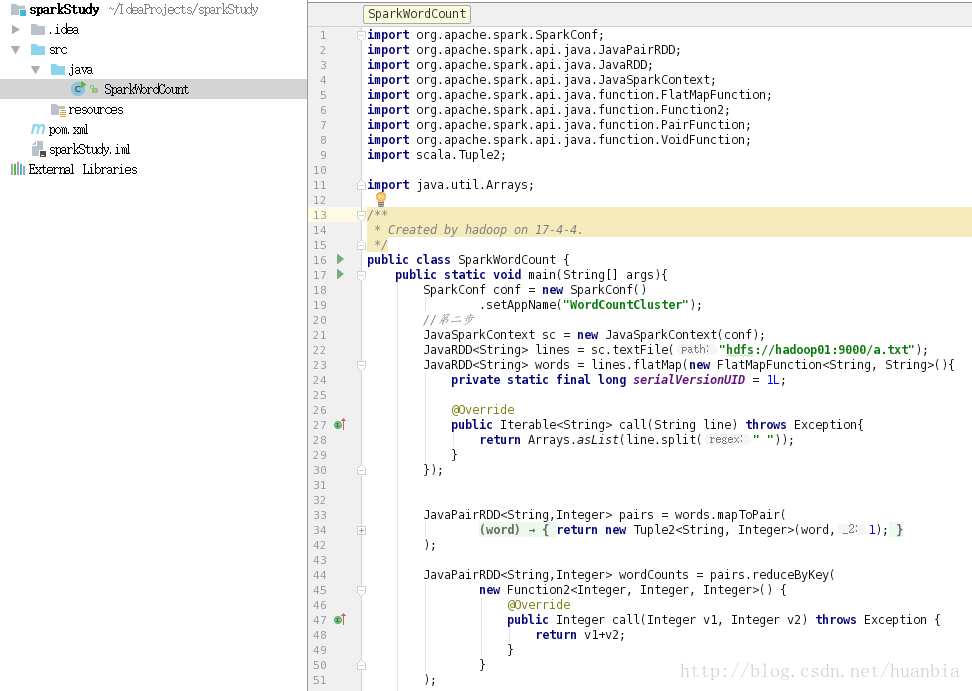
该文件代码为:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2; import java.util.Arrays; /**
* Created by hadoop on 17-4-4.
*/
public class SparkWordCount {
public static void main(String[] args){
SparkConf conf = new SparkConf()
.setAppName("WordCountCluster");
//第二步
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://hadoop01:9000/a.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>(){
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception{
return Arrays.asList(line.split(" "));
}
}); JavaPairRDD<String,Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word,1);
}
}
); JavaPairRDD<String,Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
); wordCounts.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1+" : "+ wordCount._2 );
}
}); sc.close(); }
}
打包:
执行
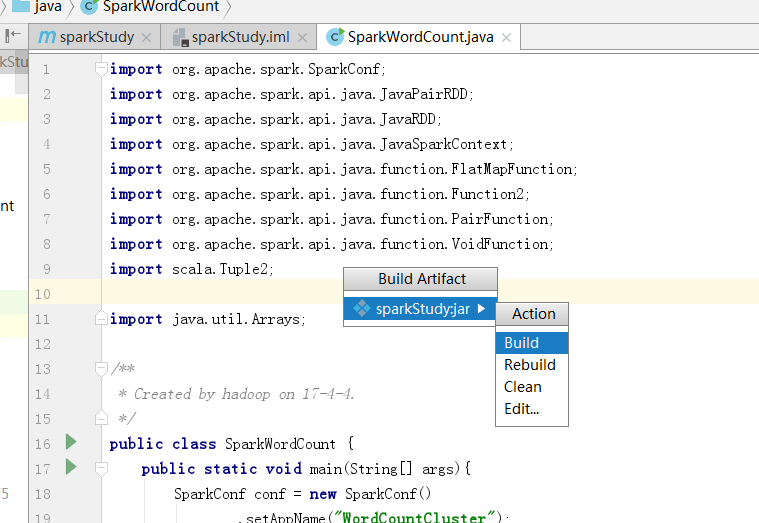
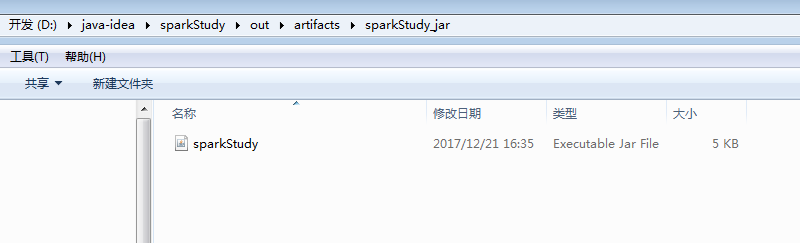
会在output目录下 生成可执行jar包 sparkStudy
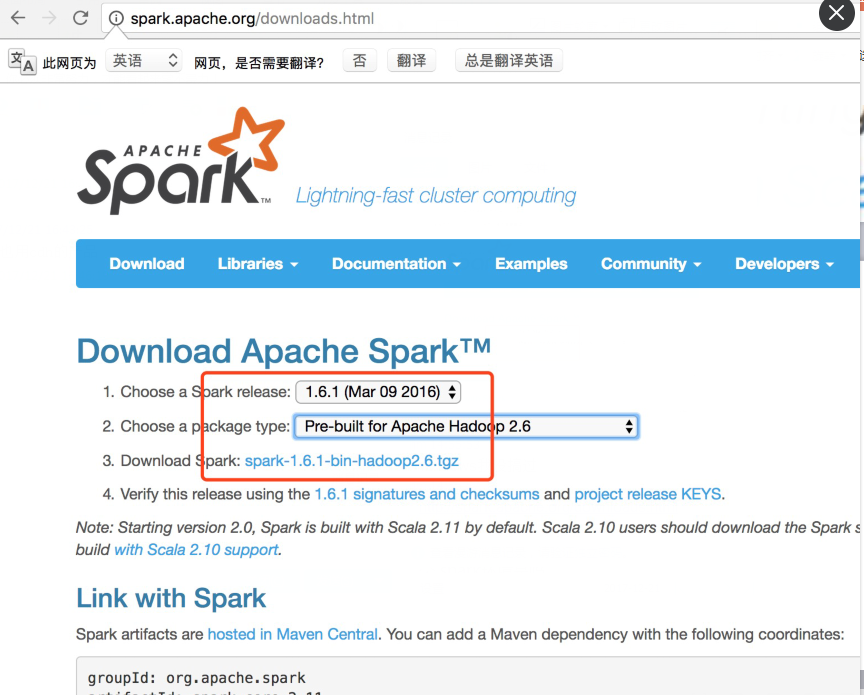
4、jar包上传到集群并执行
从spark官方网站 下载spark-1.6.1-bin-hadoop2.6.tgz
Spark目录:
bin包含用来和Spark交互的可执行文件,如Spark shell。
examples包含一些单机Spark job,可以研究和运行这些例子。
Spark的Shell:
Spark的shell能够处理分布在集群上的数据。
Spark把数据加载到节点的内存中,因此分布式处理可在秒级完成。
快速使用迭代式计算,实时查询、分析一般能够在shells中完成。
Spark提供了Python shells和Scala shells。
解压

这里需要先启动集群:
启动master: ./sbin/start-master.sh
启动worker: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
这里的地址为:启动master后,在浏览器输入localhost:8080,查看到的master地址

启动成功后,jps查看进程:
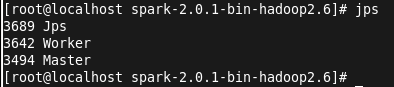
接下来执行提交命令,将打好的jar包上传到linux目录,jar包在项目目录下的out\artifacts下。
提交作业: ./bin/spark-submit --master spark://localhost:7077 --class WordCount /home/lucy/learnspark.jar
可以在4040端口查看job进度:
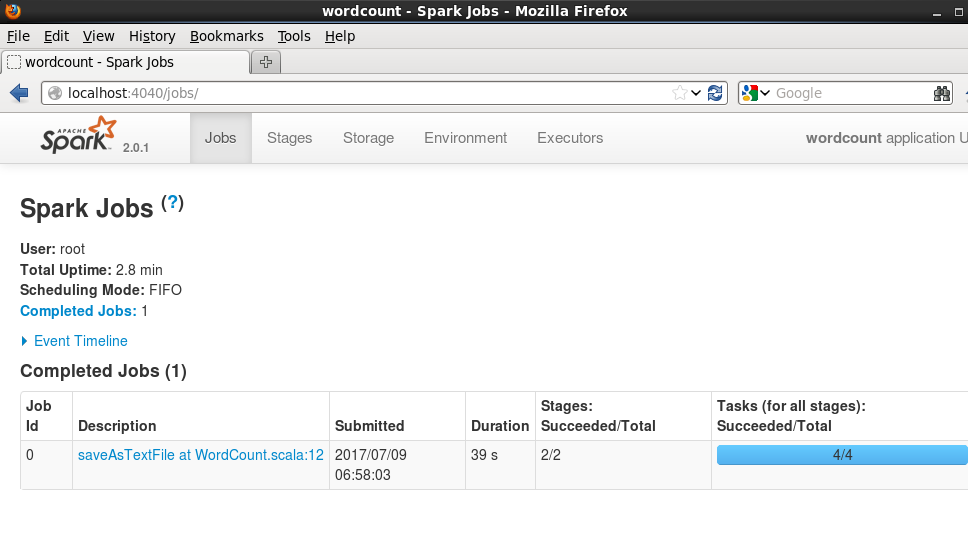
将执行的包上传到服务器上,封装执行的脚本。


然后执行脚本,执行结果如下:
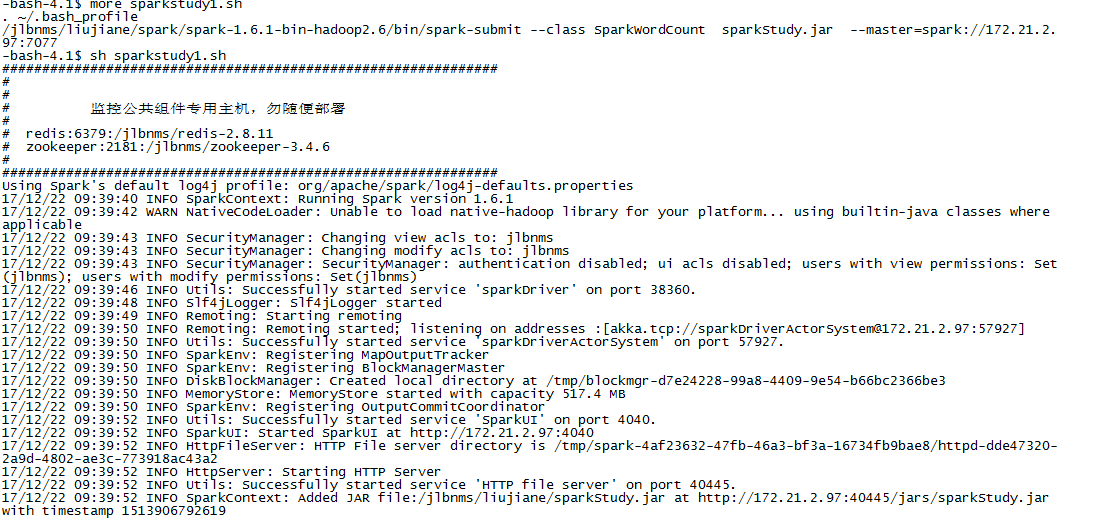
任务执行结束。
spark编程入门-idea环境搭建的更多相关文章
- Minecraft Forge编程入门一 “环境搭建”
什么是Forge Minecraft Forge is a Minecraft application programming interface (API) which allows almost ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- 【个人笔记】003-PHP基础-01-PHP快速入门-03-PHP环境搭建
003-PHP基础-01-PHP快速入门 03-PHP环境搭建 1.客户端(浏览器) IE FireFox CHROME Opera Safari 2.服务器 是运行网站的基本 是放置程序代码的地方 ...
- Android入门之环境搭建
欢迎访问我的新博客:http://www.milkcu.com/blog/ 原文地址:http://www.milkcu.com/blog/archives/1376935560.html 原创:An ...
- scala 入门Eclipse环境搭建
scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld IDE选择并下载: scala for eclipse 下载: http://scala-ide.org/downloa ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
随机推荐
- Unable to resolve dependency for ':app@debug/compileClasspath': Could not resolve com.android.support:appcompat-v7:26.1.0
android studio 3.0 出现此问题可能是因为 你的android studio 时脱机状态 无法下载资源 这时候你可以点击左上角分File->Other Settings-> ...
- 十二. for of 示例 (可以解决大多数应用场景)
for of entries() 可以同时拿到数组的索引跟值 因此可以使用解构的语法: for of 示例 1. 求和 2.字符串
- python 九九乘法口诀
for i in range(1,10): for j in range(1,i+1): print(j,"*",i,"=",i*j,&qu ...
- 免费带你体验阿里巴巴旗舰大数据计算产品MaxCompute
什么是MaxCompute? 众所周知,MaxCompute是阿里云推出的承载EB级的数据存储能力,百PB级的单日计算能力,公共云覆盖国内外十几个国家和地区,专有云包含城市大脑在内部署超过100+套的 ...
- expect离线安装
expect5.45.4.tar.gz和tcl8.4.11-src.tar.gz压缩包请前往以下链接下载: https://download.csdn.net/download/gangzi221/1 ...
- H5页面在手机上查看 使用手机浏览自己的web项目
参考:http://www.browsersync.cn/#install 首先全局安装BrowserSync : npm install -g browser-sync 其次在项目文件夹下运行: b ...
- 牛客多校第四场 J Free 最短路
题意: 求最短路,但是你有k次机会可以把路径中某条边的长度变为0. 题解: 跑k+1次迪杰斯特拉,设想有k+1组dis数组和优先队列,第k组就意味着删去k条边的情况,每次松弛操作,松弛的两点i,j和距 ...
- iserver中的服务数据迁移
今天需要将iserver测试服务器上的空间数据服务(数据源是Oracle Plus)迁移到客户的正式服务器,原想需要很大的工作量,其实是这样简单: 一.保证客户的iserver环境都已安装正确.对于o ...
- fatal error U1087: cannot have : and :: dependents for same target Stop.
转自VC错误:http://www.vcerror.com/?p=72 问题描述: 完成后编译,发现有错误 D:\WinDDK\7600.16385.1\bin\makefile.new(7117) ...
- iOS开发之SceneKit框架--加载多个模型.dae/.scn文件
1.通过SCNGeometry或子类SCNParametricGeometry创建 相关链接:iOS开发之SceneKit框架--SCNGeometry.h iOS开发之SceneKit框架--SCN ...