深度兴趣网络DIN-SIEN-DSIN
看看阿里如何在淘宝做推荐,实现“一人千物千面”的用户多样化兴趣推荐,首先总结下DIN、DIEN、DSIN:
- 传统深度学习在推荐就是稀疏到embedding编码,变成稠密向量,喂给NN
- DIN引入attention机制,捕获候选商品和用户浏览过的商品之间的关系(兴趣)
- DIEN在DIN基础上引入序列概念,将用户历史行为序列纳入到网络内
- DSIN将行为序列划分为session,更符合RNN概念
大多推荐场景下数据下都包含如下信息,用户内在属性信息、用户行为信息、商品信息、上下文信息,一个明显不同的不同用户的行为信息差异很大。
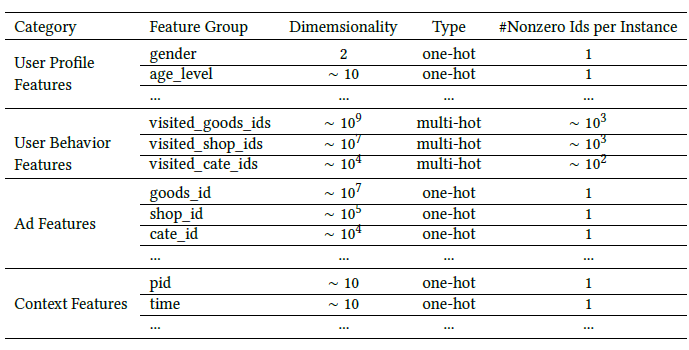
深度学习在推荐系统一般做法:
稀疏向量 -- embedding -- fixed-length稠密向量 --- MLP
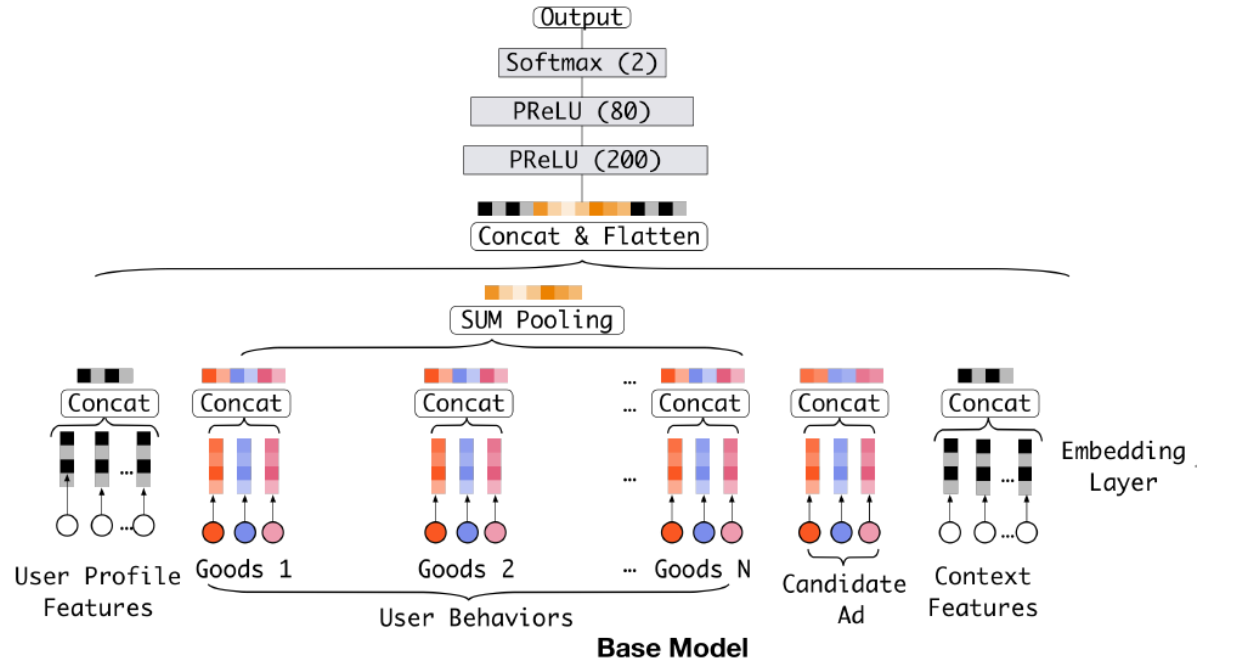
这样做有什么问题?
一个明显的问题是不同用户的行为序列长度是不同的,fixed-length信息表达不全面
用户最终的行为只和历史行为中的部分有关,因此对历史序列中商品相关度应有区分
- DIN
根据上述问题,有两个解决思路:
- 对不同用户尝试不同维度的向量,导致训练困难
- 如何在有限的维度表示用户的差异化兴趣?
DIN从第二个问题出发,引入局部激活单元,对特定的ad自适应学习用户兴趣表示向量。即同一用户在获选ad不同时,embedding向量不同。
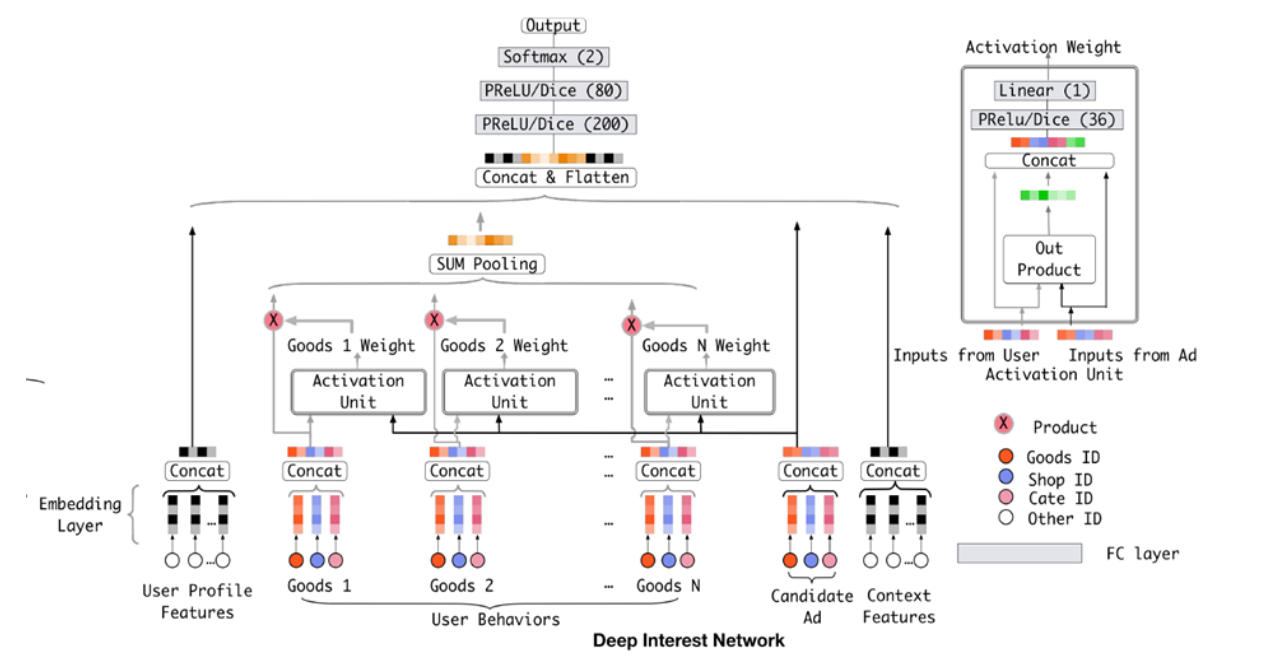
key idea
使用attention机制捕获ad和用户行为序列商品之间的关系
看结果
- 和ad相似度搞得物品拥有更高的权重
- 不相关物品的相似度低
下面是两个小tricks,对结果提升有帮助:
Mini-batch Aware Regularization
Dice Activation Function
tricks的细节可以参考原论文。
- DIEN
DIEN使用了GRU来建模用户行为序列,在DIN基础上考虑序列信息
- 使用GRU建模序列信息,即用GRU最后时刻的隐状态表示序列
- 修改GRU为AUGRU
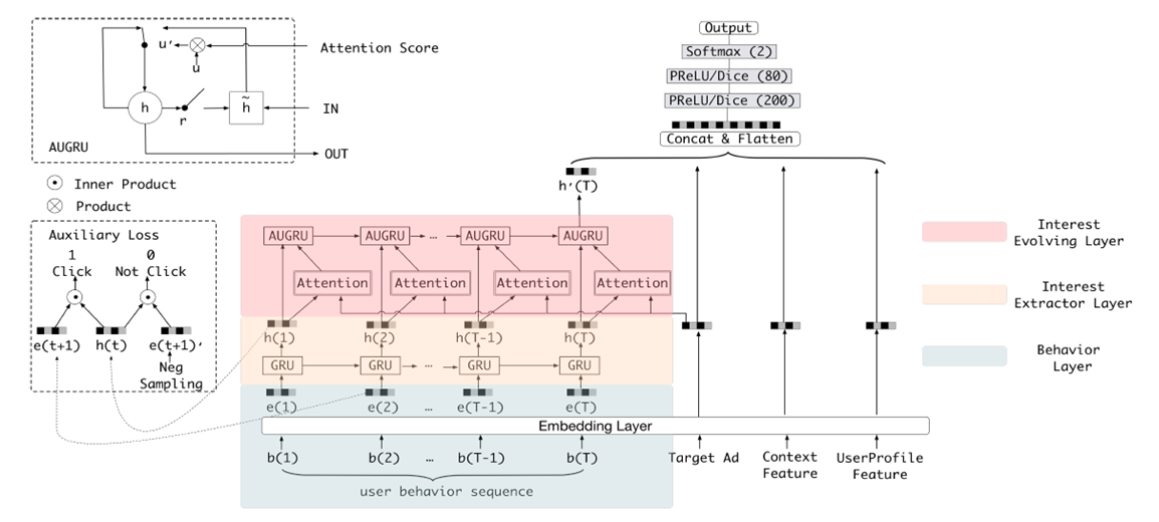
看下AUGRU部分:
\[
a_{t}=\frac{\exp \left(\mathbf{h}_{t} W \mathbf{e}_{a}\right)}{\sum_{j=1}^{T} \exp \left(\mathbf{h}_{j} W \mathbf{e}_{a}\right)}
\]
\[
\begin{aligned}&\tilde{\mathbf{u}}_{t}^{\prime}=a_{t} * \mathbf{u}_{t}^{\prime}\\&\mathbf{h}_{t}^{\prime}=\left(1-\tilde{\mathbf{u}}_{t}^{\prime}\right) \circ \mathbf{h}_{t-1}^{\prime}+\tilde{\mathbf{u}}_{t}^{\prime} \circ \tilde{\mathbf{h}}_{t}^{\prime}\end{aligned}
\]
根据attention score控制更新门。
看模型,直观的思考貌似很合理,但是有两个问题:
- 序列信息包含多长?即短期兴趣还是长期兴趣的问题
- 序列连续否?不同时期的兴趣不一样,序列间隔过大相关性可能很低
- 用户是否一定服从严格的序列?先点那个和后点那个的区别大吗
1.DIEN使用过去14天信息行为序列,从RNN角度来说可能短期内行为信息更重要,但长期信息是否引入了噪音?
2.过去14天内用户需求会变。比如第一天买了衣服、可能十天后买的是书
3.用户点击顺序不一定重要,自己想一想好像是
关于使用RNN是否合适,RNN只关心t-1(上一步)和t(当前步),而没有涉及t-1和t之间的时间间隔。没涉及不代表不重要,反而是因为其使用前提就是假定各步骤之间是等间距的,见维基百科。
A time series is a series of data points indexed (or listed or graphed) in time order. Most commonly, a time series is a sequence taken at successive equally spaced points in time"
以上部分内容摘自[3].
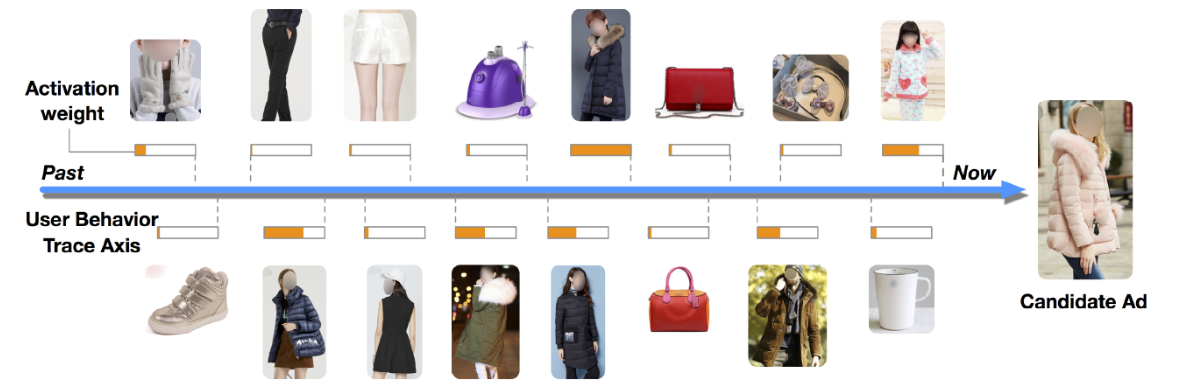
- DSIN
DSIN进一步做出优化,在每个会话中的行为是相近的,而在不同会话之间差别是很大的,如下图的例子:

模型架构
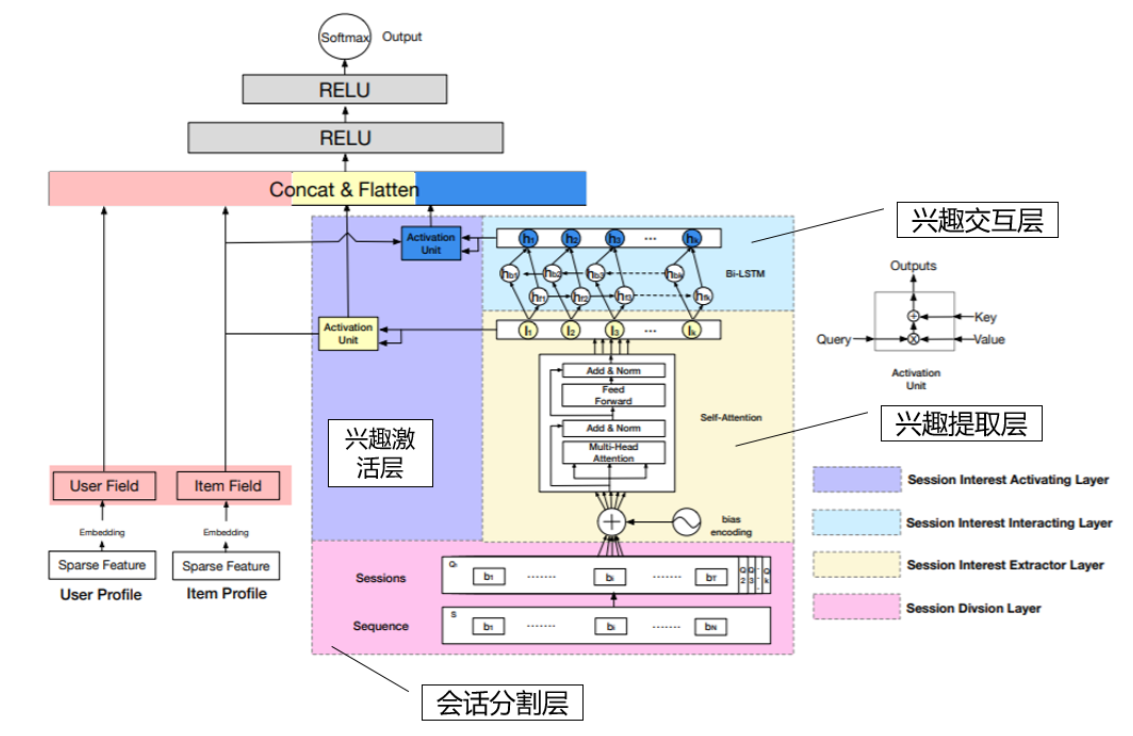
- 会话分割层
将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min,就进行切分。
- 兴趣提取层
用Tansformer编码用户行为序列,简单来说就是输入一个序列,输出一个对应的embedding序列。
引入了偏置编码(Bias encoding),实质上是对序列中位置信息的编码
原始做法:
\[
\begin{aligned}&P E_{(\text {pos}, 2 i)}=\sin \left(\text {pos} / 10000^{2 i / d_{\text {model}}}\right)\\&P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{2 i / d_{m o d e l}}\right)\end{aligned}
\]
bias encoding:
\[
\mathbf{B E}_{(k, t, c)}=\mathbf{w}_{k}^{K}+\mathbf{w}_{t}^{T}+\mathbf{w}_{c}^{C}
\]
第一项表示处于第几个session,第二项表示session的第几个行为,第三项表示整体位置的embedding。关于这三项其实不是很明确,知道的同学麻烦帮忙解答下,贴上原图

- 兴趣交互层
捕获序列的顺序关系,文中使用Bi-LSTM
- 兴趣激活层
和DIN中一样,使用attention捕捉商品相关性
模型思想大概就这么多,细节部分可以参考原论文。
具体应用
充分了解领域数据特点,根据场景定制适合具体问题的网络结构
需要有丰富的特征
references:
[1]Deep Interest Network for Click-Through Rate Prediction,https://arxiv.org/pdf/1706.06978.pdf ,KDD2018
[2]Deep Interest Evolution Network for Click-Through Rate Prediction, https://arxiv.org/pdf/1809.03672.pdf. AAAI 2019
[3]也评Deep Interest Evolution Network . https://zhuanlan.zhihu.com/p/54838663.
[4]Deep Session Interest Network for Click-Through Rate Prediction. https://arxiv.org/pdf/1905.06482.pdf . IJCAI 2019
深度兴趣网络DIN-SIEN-DSIN的更多相关文章
- 推荐系统---深度兴趣网络DIN&DIEN
深度学习在推荐系统.CTR预估领域已经有了广泛应用,如wide&deep.deepFM模型等,今天介绍一下由阿里算法团队提出的深度兴趣网络DIN和DIEN两种模型 paper DIN:http ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列
[阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 目录 [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 0x00 摘要 0x01 DIN 需要什么数据 0x02 如何产生数据 2 ...
- [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构
[阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 目录 [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x0 ...
- 推荐系统中的注意力机制——阿里深度兴趣网络(DIN)
参考: https://zhuanlan.zhihu.com/p/51623339 https://arxiv.org/abs/1706.06978 注意力机制顾名思义,就是模型在预测的时候,对用户不 ...
- 阿里深度兴趣网络模型paper学习
论文地址:Deep Interest Network for Click-Through Rate ... 这篇论文来自阿里妈妈的精准定向检索及基础算法团队.文章提出的Deep Interest Ne ...
- [论文阅读]阿里DIEN深度兴趣进化网络之总体解读
[论文阅读]阿里DIEN深度兴趣进化网络之总体解读 目录 [论文阅读]阿里DIEN深度兴趣进化网络之总体解读 0x00 摘要 0x01论文概要 1.1 文章信息 1.2 基本观点 1.2.1 DIN的 ...
- [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本
[阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 目录 [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 0x00 摘要 0x01 背景 1.1 代码进化 1.2 Deep ...
- Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.3
Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.3 http://blog.csdn.net/sunbow0 第二章Deep ...
随机推荐
- oracle函数 TO_MULTI_BYTE(c1)
[功能]将字符串中的半角转化为全角 [参数]c1,字符型 [返回]字符串 [示例] SQL> select to_multi_byte('高A') text from dual; test -- ...
- SDUT-2449_数据结构实验之栈与队列十:走迷宫
数据结构实验之栈与队列十:走迷宫 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 一个由n * m 个格子组成的迷宫,起 ...
- Python基础:17类和实例之一(类属性和实例属性)
1:类通常在一个模块的顶层进行定义.对于Python来说,声明与定义类是同时进行的. 2:类属性仅与其类相绑定,类数据属性仅当需要有更加“静态”数据类型时才变得有用,这种属性是静态变量.它们表示这些数 ...
- 使用属性position:fixed的时候如何才能让div居中
css: .aa{ position: fixed; top: 200px; left: 0px; right: 0px; width: 200px; height: 200px; margin-le ...
- Linux 端口进程查看
netstat -lnp|grep 80
- 2018-12-25-SourceYard-制作源代码包
title author date CreateTime categories SourceYard 制作源代码包 lindexi 2018-12-25 9:43:7 +0800 2018-12-09 ...
- java基本数据类型和包装类相互转换
把基本数据类型 → 包装类: 通过对应包装类的构造方法实现 除了Character外,其他包装类都可以传入一个字符串参数构建包装类对象. 包装类 → 基本数据类型 包装类的实例方法xxxValue() ...
- 符合阿里巴巴代码规范的checkstyle检测文件
一.安装与简介 eclipse和idea都有对应的插件,找到插件安装界面.搜索checkstyle,点击安装后,重启IDE即可.(网上有很多安装教程,就不重复制造轮子了) 二.导入配置文件 在chec ...
- 2018-7-31-C#-判断两条直线距离
title author date CreateTime categories C# 判断两条直线距离 lindexi 2018-07-31 14:38:13 +0800 2018-05-08 10: ...
- 2018-2-13-C#-通配符转正则
title author date CreateTime categories C# 通配符转正则 lindexi 2018-2-13 17:23:3 +0800 2018-2-13 17:23:3 ...