深度学习论文翻译解析(六):MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications
论文标题:MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications
论文作者:Andrew G.Howard Menglong Zhu Bo Chen .....
论文地址:https://arxiv.org/pdf/1704.04861.pdf (https://arxiv.org/abs/1704.04861)
代码地址:
参考地址:https://blog.csdn.net/u011974639/article/details/79199306
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真学习论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。

摘要
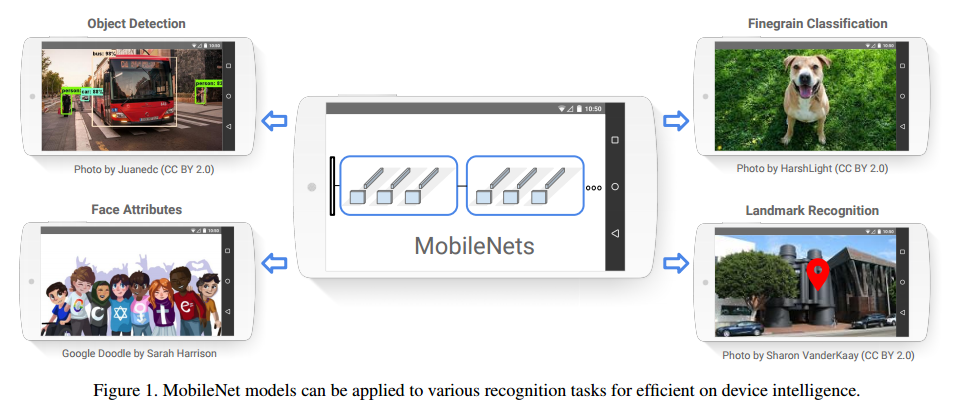
我们提出一个在移动端和嵌入式应用高效的分类模型叫做MobileNets,MobileNets基于流线型架构(streamlined),使用深度可分类卷积(depthwise separable convolutions,即Xception 变体结构)来构建轻量级深度神经网络。我们介绍两个简单的全局超参数,可有效的在延迟和准确率之间做折中。这些超参数允许我们依据约束条件选择合适大小的模型。论文测试在多个参数量下做了广泛的实验,并在ImageNet分类任务上与其他先进模型做了对比,显示了强大的性能。论文验证了模型在其他领域(对象检测,人脸识别,大规模地理定位等)使用的有效性。


1,引言
自从AlexNet [19]通过赢得ImageNet挑战:ILSVRC 2012 [24]来推广深度卷积神经网络以来,卷积神经网络就已经在计算机视觉中变得无处不在。 总的趋势是建立更深,更复杂的网络以实现更高的准确性[27、31、29、8]。 但是,这些提高准确性的进步并不一定会使网络在大小和速度方面更加高效。 在许多现实世界的应用程序中,例如机器人技术,自动驾驶汽车和增强现实,识别任务需要在计算受限的平台上及时执行。
本文介绍了一种有效的网络体系结构和两个超参数集,以建立非常小的,低延迟的模型,这些模型可以轻松地与移动和嵌入式视觉应用的设计要求匹配。 第2节回顾了构建小型模型的先前工作。 第3节介绍了MobileNet体系结构以及两个超参数宽度因子和分辨率因子,以定义更小,更高效的MobileNet。 第4节介绍了ImageNet上的实验以及各种不同的应用程序和用例。 第5节以总结和结论结束。


之前的工作
在最近的文献中,人们对建立小型高效的神经网络越来越感兴趣,[16,34,12,36,22]。 通常可以将许多不同的方法归类为压缩预训练网络或直接训练小型网络。 本文提出了一类网络架构,允许模型开发人员专门为其应用选择与资源限制(延迟,大小)相匹配的小型网络。 MobileNets主要专注于优化延迟,但也会产生小型网络。 关于小型网络的许多论文只关注规模,却不考虑速度。
MobileNets主要是从深度方向可分卷积中构建的,该方法最初在[26]中引入,随后在Inception模型[13]中使用,以减少前几层的计算量。 扁平化网络[16]由完全分解的卷积构建网络,并显示了高度分解的网络的潜力。 独立于本文之外,分解网络[34]引入了类似的分解卷积以及拓扑连接的使用。 随后,Xception网络[3]演示了如何按比例扩展深度可分离滤波器以执行Inception V3网络。 另一个小型网络是Squeezenet [12],它使用瓶颈方法设计了一个非常小的网络。 其他简化的计算网络包括结构化转换网络[28]和deep fried convnets[37]。
获得小型网络的另一种方法是收缩,分解或压缩预训练的网络。在文献中已经提出了基于乘积量化[36],散列[2]以及修剪,矢量量化和霍夫曼编码[5]的压缩。 另外,已经提出了各种因式分解来加速预训练的网络[14、20]。 训练小型网络的另一种方法是蒸馏[9],该方法使用较大的网络来教授较小的网络。 它是我们方法的补充,在第4节的某些用例中进行了介绍。另一种新兴方法是低位网络[4、22、11]。

3, MobileNet架构
在本节中,我们首先描述MobileNet所基于的核心层,它们是深度可分离的过滤器。 然后,我们描述MobileNet网络结构,并以两个模型缩减超参数宽度因子和分辨率因子的描述作为结束。


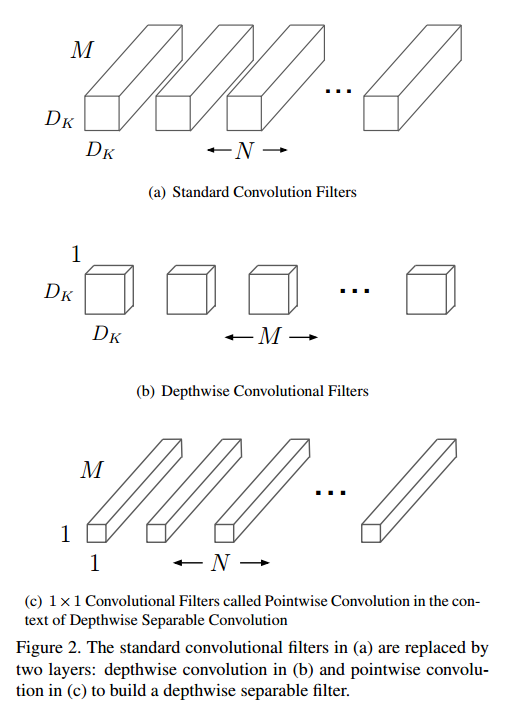
MobileNet模型基于深度可分离卷积,它是分解卷积的一种形式,它将标准卷积分解为深度卷积和称为点向卷积的1×1卷积。 对于MobileNet,深度卷积将单个滤波器应用于每个输入通道。 然后逐点卷积应用1×1卷积以组合输出深度卷积。 一个标准的卷积既可以过滤又可以将输入合并为一组新的输出。 深度可分离卷积将其分为两层,一个用于过滤的单独层和一个用于合并的单独层。 这种分解具有极大地减少计算和模型大小的效果。 图2显示了如何将标准卷积2(a)分解为深度卷积2(b)和1×1点向卷积2(c)。
标准卷积层将DF×DF×M特征图F作为输入,并生成DF×DF×N特征图G,其中DF是正方形输入特征图的空间宽度和高度,M是输入通道的数量(输入深度),DG是方形输出特征图的空间宽度和高度,N是输出通道的数量(输出深度)

标准卷积层由大小为DK×DK×M×N的卷积核K进行参数化,其中DK是假定为正方形的核的空间尺寸,M是输入通道数,N是输出通道数,如先前定义 。
假设跨度为1和填充为标准卷积的输出特征图,计算公式为:

其中计算成本乘以输入通道数M,输出通道数 N,内核大小 Dk*Dk 和特征图大小DF * DF 。MobileNet模型解决了这些术语中的每一个及其相互作用。首先,它使用深度可分类卷积来打破输出通道数与内核大小之间的相关作用。


标准卷积运算具有对基于卷积核的特征进行过滤并组合特征以产生新表示的效果。可以通过使用称为深度可分离卷积的因式分解将滤波和组合步骤分为两步,以进行实质性还原 在计算成本上。
深度可分离卷积由两层组成:深度卷积和点卷积。 我们使用深度卷积对每个输入通道(输入深度)应用单个滤波器。 然后使用逐点卷积(简单的1×1卷积)来创建深度层输出的线性组合。 MobileNets对这两个层都使用了batchnorm和ReLU非线性。


简单来说,每个输入通道(输入深度)带有一个滤波器的深度卷积可以写成下面:

其中Khat表示深度卷积,卷积核为(Dk, Dk, l, M),其中 mth 个卷积核应用在F中第 mth 个通道上,产生 Ghat 上第 mth个通道输出。
深度卷积计算量为:Dk*Dk*M*Df*Df
相对于标准于标准卷积,深度卷积非常有效。但是,它仅过滤输入通道,不会将他们组合以创建新功能。因此,需要额外的一层来计算通过 1*1 卷积的深度卷积输出的线性组合,以便生出这些新特征。
深度卷积和 1*1 (点向)卷积的组合被称为深度可分离卷积,最初在[26]中引入的。
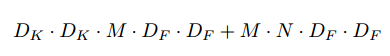
上面是深度卷积和1*1点卷积的总和。
通过将卷积表示为过滤和组合的两步过程,我们减少了以下计算:
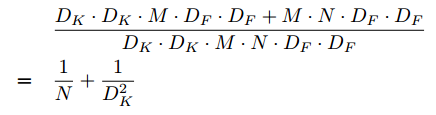
MobileNet使用 3*3 深度可分离卷积,使用的计算量比标准卷积稍8到9倍,而准确率仅略有降低,如第四节所述。
在空间维度上进行额外的因式分解(例如在[16, 31])不会节省太多额外的计算,因为在深度卷积中只花费了很少的计算。


3.2,网络结构与训练
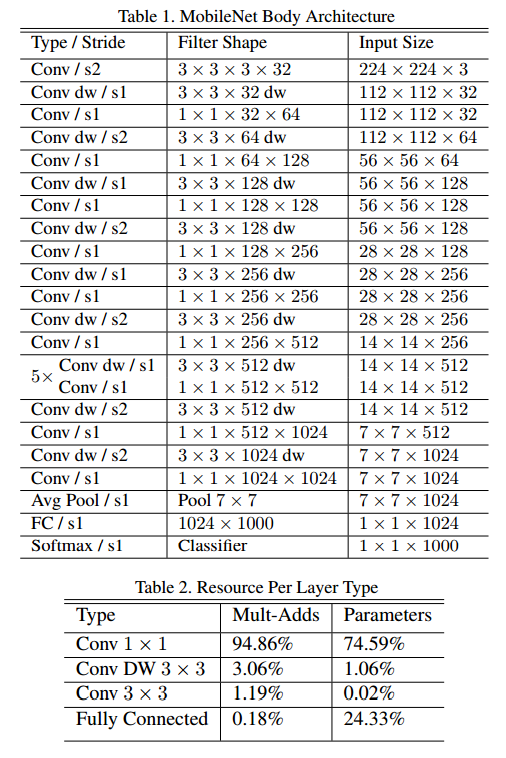
如前一节所述,MobileNet结构建立在深度可分离卷积之上,第一层是完整卷积。通过以如此简单的术语定义网络,我们能够轻松地探索网络拓扑以找到一个好的网络。表1中定义了MobileNet体系结构。所有层后面都带有一个batchnorm [13]和ReLU非线性,最后一个完全连接的层除外,该层没有非线性,并馈入softmax层进行分类。图3将具有常规卷积,batchnorm和ReLU非线性的层与具有深度卷积,1×1点式卷积以及每个卷积层后的batchnorm和ReLU的分解层进行了对比。下采样是在深度卷积以及第一层中通过跨步卷积处理的。最终平均池在完全连接的层之前将空间分辨率降低为1。将深度和点积卷积计为单独的层,MobileNet有28层。
仅用少量的Mult-Adds定义网络是不够的。确保这些操作可以有效实施也很重要。例如,直到非常高的稀疏度,非结构化稀疏矩阵运算通常不比密集矩阵运算快。我们的模型结构将几乎所有计算都放入密集的1×1卷积中。这可以通过高度优化的通用矩阵乘法(GEMM)函数来实现。卷积通常由GEMM实现,但需要在内存中进行名为im2col的初始重新排序,才能将其映射到GEMM。例如,这种方法在流行的Caffe软件包中使用[15]。 1×1卷积不需要在内存中进行重新排序,可以直接使用GEMM(这是最优化的数值线性代数算法之一)来实现。如表2所示,MobileNet将其95%的计算时间花费在1×1卷积中,其中也包含75%的参数。几乎所有其他参数都位于完全连接的层中。
使用RMSprop [33]在TensorFlow [1]中使用与Inception V3 [31]类似的异步梯度下降训练了MobileNet模型。但是,与训练大型模型相反,我们使用较少的正则化和数据增强技术,因为小型模型的过拟合麻烦较小。在训练MobileNets时,我们不使用侧边或标签平滑,并且通过限制大型Inception训练中使用的小作物的大小来减少失真的图像数量[31]。另外,我们发现,对深度过滤器进行很少或几乎没有权重衰减(l 2正则化)是很重要的,因为它们中的参数太少了。对于下一部分中的ImageNet基准,无论模型的大小如何,所有模型都使用相同的训练参数进行训练。



3.3,宽度参数:更小的模型
尽管基本的MobileNet体系结构已经很小且延迟很低,但很多情况下特定用例或应用可能要求模型变得更小,更快。为了构建这些更小且计算成本更低的模型,我们引入了一个非常简单的参数 alpha,称为 width乘数。宽度乘数 alpha 的作用是使每一层的网络均匀变薄。对于给定的层和宽度乘数 alpha,输入通道的数量变为 alphaM,而输出通道的数量N变为 alphaN。具有宽度乘数 alpha 的深度可分离卷积的计算成本为:
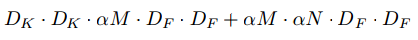
其中α∈(0,1],典型设置为1、0.75、0.5和0.25。α= 1是基准MobileNet,α<1是减少的MobileNets。宽度乘数具有减少计算成本和二次方参数数量的作用宽度乘数可以应用于任何模型结构,以合理的精度,等待时间和大小折衷来定义新的较小模型,用于定义需要从头开始训练的新的简化结构。
下图为MobileNet的网络构成,它的95%的时间是在 1*1 conv层上消耗的,另外 1*1 的conv参数也占了所有可训练参数的 75%.


3.4,分辨率因子:减少表示
减少神经网络计算成本的第二个超参数是分辨率乘数ρ。我们将其应用于输入图像,然后通过相同的乘数来减少每一层的内部表示。实际上,我们通过设置输入分辨率来隐式设置ρ。现在,我们可以将网络核心层的计算成本表示为具有宽度乘数α和分辨率乘数ρ的深度可分离卷积:
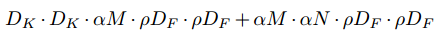
其中ρ∈(0,1]通常是隐式设置的,因此网络的输入分辨率为224、192、160或128。ρ= 1是基准MobileNet,而ρ<1是简化的计算MobileNets。将计算成本降低ρ2的效果。
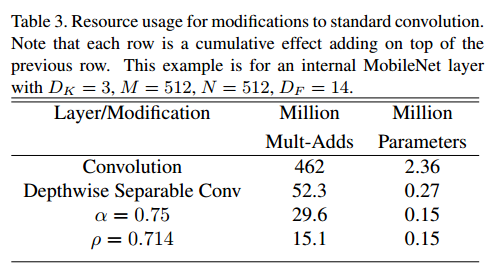
作为示例,我们可以查看MobileNet中的典型层,并了解深度可分离卷积,宽度乘数和分辨率乘数如何减少成本和参数。表3显示了将体系结构收缩方法依次应用于该层时该层的参数的计算和数量。第一行显示了完整卷积层的Mult-Adds和参数,输入特征图的大小为14×14×512,内核K的大小为3×3×512×512。我们将在下一部分中详细介绍在资源和准确性之间进行权衡。


4,实验
实验部分主要研究以下部分:深度卷积的影响;宽度因子的影响‘两个超参数的权衡;与其他模型对比;
(翻译意思:在本节中,我们首先研究深度卷积的影响以及通过减少网络的宽度而不是层数来选择收缩的方法。然后,我们基于两个超参数(宽度因子和分辨率因子)显示减少网络的权衡,并将结果与许多留下的模型进行比较。然后,我们研究了MobileNets应用于许多不同的应用程序。)
4.1,模型选择
首先,我们展示了与具有完整卷积的模型相比,局域深度可分离卷积的MobileNet的结果。在表4中,我们看到与完全卷积相比,使用深度可分离卷积仅能在ImageNet上降低 1% 的精度,但是计算量和参数量降低了一个数量级。
接下来,我们将比较使用宽度因子的较薄模型与使用较少图层的较浅模型的结果。为了使MobileNet变浅,表1中删除了五层特征尺寸为 14*14*512 的可分离滤波器。表5显示,在类似的计算和参数数量下,使MobileNets变薄比使他们变浅好 3%。
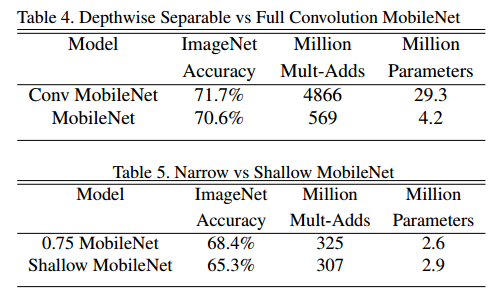


4.2 模型收缩超参数
表6显示了使用宽度因子 alpha 缩小 MobileNet 体系结构的精度,计算和尺寸折中。精度会平稳下降,直到架构缩小到 alpha=0.25为止。
表7表示了通过训练具有降低的输入分辨率的MobileNet来获得不同分辨率因子的精度,计算和尺寸的折中。精度在整个分辨率上都会下降。
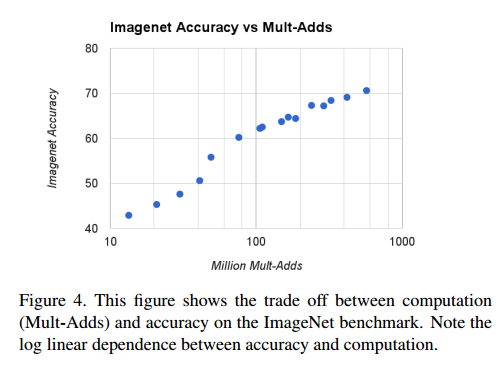
图4显示了用宽度因子 α∈{1、0.75、0.5、0.25}与分辨率{224、192、160、128}的叉积制成的16个模型在ImageNet精度和计算之间的权衡。当模型在α= 0.25时变得很小时,结果呈对数线性增长。
图5显示了使用宽度因子α∈{1,0.75,0.5,0.25}和分辨率{224,192,160,128}的叉积制成的16个模型的ImageNet精度和参数数量之间的权衡。
表8将完整的MobileNet与原始的GoogleNet [30]和VGG16 [27]进行了比较。 MobileNet的准确度几乎与VGG16一样,但要小32倍,而计算复杂度却要低27倍。它比GoogleNet更准确,但体积更小,计算量减少了2.5倍以上。
表9比较了减少后的MobileNet(宽度因子α= 0.5和降低后的分辨率160×160)。减少后的MobileNet比AlexNet [19]好4%,而计算量却比AlexNet小45倍,少9.4 倍。在大约相同的大小和22倍以下的计算量下,它也比Squeezenet [12] 好4%。


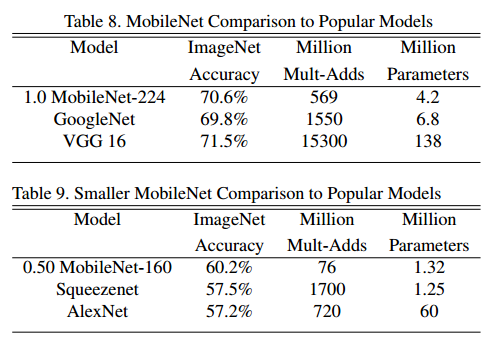

4.3 精细分类
我们在Stanford Dogs dataset上训练MobileNet进行细粒度识别[17]。 我们扩展了[18]的方法,并从网络上收集了比[18]更大甚至更嘈杂的训练集。 我们使用嘈杂的网络数据来预训练细粒度的狗识别模型,然后在斯坦福狗训练集中对模型进行微调。 Stanford Dogs测试集的结果在表10中。通过大大减少的计算,MobileNet几乎可以以大大减少的计算量和大小几乎达到[18]的相同的精度。
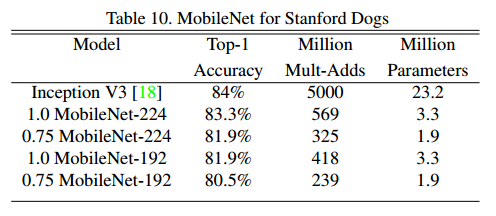


4.4 大规模地理定位
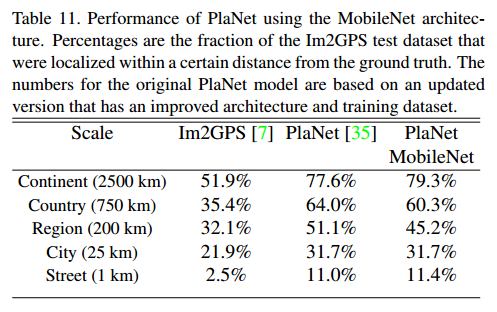
PlaNet 是做大规模地理分类任务,该任务是确定照片在哪里被分类。该方法将地球划分用作目标类别的地理单元网格,并在数百万张带有地理标签的照片上训练卷积神经网络。PlaNet已被证明可以成功地定位各种照片,并且胜过了解决同一任务的Im2GPS[6, 7]。
我们使用MobileNet的框架重新设计了PlaNet ,对比如下:基于Inception V3架构的PlaNet有5200万参数和574亿的mult-adds,而基于MobileNet的PlaNet只有1300万参数(300个是主体参数,1000万是最后分类层参数)和58万的mult-adds,相比之下,只是性能稍微受损,但还是比原Im2GPS效果好多了。

4.5,人脸属性分类
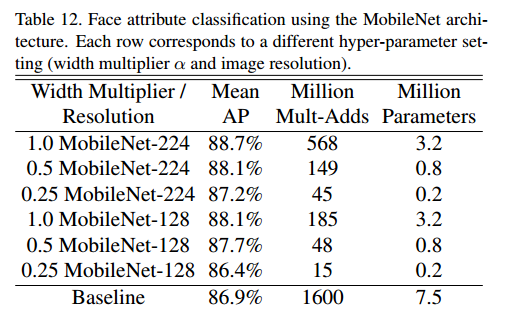
MobileNet的另一个用例是使用未知或深奥的训练程序压缩大型系统。在人脸属性分类任务中,我们演示了MobileNet与蒸馏[9](一种用于深度网络的知识转移技术)之间的协同关系。我们力求减少具有7500万个参数和16亿个Mult-Adds的大型面部属性分类器。分类器在类似于YFCC100M [32]的多属性数据集上训练。
我们使用MobileNet架构提炼出人脸属性分类器。蒸馏[9]通过训练分类器来模拟较大模型的输出2而不是地面真实标签,从而可以从大型(可能无限)的未标记数据集中进行训练。终端系统结合了蒸馏训练的可扩展性和MobileNet的简约参数化功能,不仅不需要规范化(例如重量衰减和提前停止),而且还展示了增强的性能。从Tab可以明显看出。 12基于MobileNet的分类器可以抵御激进的模型收缩:它在属性(平均AP)上实现了与内部相似的平均平均精度,而仅消耗了1%的Multi-Adds。


4.6,目标检测
MobileNet也可以部署为现代对象检测系统中的有效基础网络。我们基于赢得2016年COCO调整【10】的最新工作,报告了针对COCO数据进行对象检测训练的MobileNet的结果。在表13中,在Faster-RCNN [23]和SSD [21]框架下,将MobileNet与VGG和Inception V2 [13]进行了比较。 在我们的实验中,对SSD的输入分辨率为300(SSD 300),并将Faster-RCNN与输入分辨率分别为300和600(FasterRCNN300,Faster-RCNN 600)进行了比较。 Faster-RCNN模型每个图像评估300个RPN建议框。 在不包括8k最小图像的情况下,在COCO train + val上训练模型,并在最小上进行评估。 对于这两种框架,MobileNet都可以在计算复杂度和模型大小上实现一小部分的结果,与其他网络相比。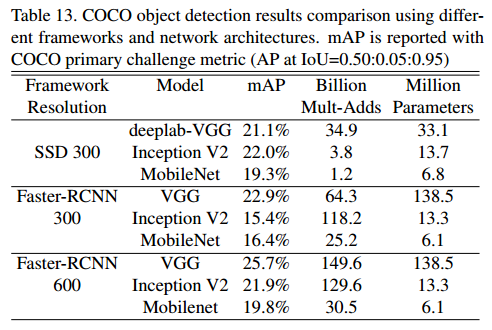



4.7 人脸识别
FaceNet 是现阶段最先进的人脸识别模型【25】,它基于三重态损失(tripleloss)构建面部嵌入。为了建立移动FaceNet模型,我们使用蒸馏来通过最小化 FaceNet和MobileNet在训练数据上的输出的平方差来进行训练。 基于MobileNet和蒸馏技术训练出结果如下:


5,总结
我们提出了一种基于深度可分离卷积的新模型架构,称为MobileNets。我们调查了一些导致有效模型的重要设计决策。然后,然后,我们演示了如何通过权衡合理的精度以减少大小和延迟来使用宽度因子和分辨率因子来构建更小,更快的MobileNet。然后,我们将不同的MobileNet与流行的模型进行了笔记,这些模型展示了出色的尺寸,速度和准确性特征。最后,我们演示了MobileNet在应用于各种任务时的有效性。为了帮助采用和探索MobileNets的下一步,我们计划在TensorFlow中发布模型。
参考文献:
https://www.zhihu.com/search?type=content&q=mobilenet
https://arxiv.org/pdf/1704.04861.pdf
https://blog.csdn.net/u011974639/article/details/79199306
深度学习论文翻译解析(六):MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Appliications的更多相关文章
- 深度学习论文翻译解析(十七):MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文标题:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 论文作者:Andrew ...
- 【论文翻译】MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 论文链接:https://arxi ...
- [论文阅读] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (MobileNet)
论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 本文提出的模型叫Mobi ...
- 论文笔记——MobileNets(Efficient Convolutional Neural Networks for Mobile Vision Applications)
论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications MobileNet由Go ...
- [论文理解] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications Intro MobileNet 我 ...
- 【网络结构】MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications论文解析
目录 0. Paper link 1. Overview 2. Depthwise Separable Convolution 2.1 architecture 2.2 computational c ...
- Paper | MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
目录 1. 故事 2. MobileNet 2.1 深度可分离卷积 2.2 网络结构 2.3 引入两个超参数 3. 实验 本文提出了一种轻量级结构MobileNets.其基础是深度可分离卷积操作. M ...
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
1. 摘要 作者提出了一系列应用于移动和嵌入式视觉的称之为 MobileNets 的高效模型,这些模型采用深度可分离卷积来构建轻量级网络. 作者还引入了两个简单的全局超参数来有效地权衡时延和准确率,以 ...
- 【MobileNet-V1】-2017-CVPR-MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications-论文阅读
2017-CVPR-MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications Andrew H ...
随机推荐
- PyCharm indexing goes into infinite loop pycharm 不同的indexing
https://stackoverflow.com/questions/24955896/pycharm-indexing-goes-into-infinite-loop 5 1 I opened u ...
- win10 uwp win2d CanvasVirtualControl 与 CanvasAnimatedControl
本文来告诉大家 CanvasVirtualControl ,在什么时候使用这个控件. 在之前的入门教程win10 uwp win2d 入门 看这一篇就够了我直接用的是CanvasControl,实际上 ...
- H3C DHCP服务器基本配置
- Spring Boot Admin-应用健康监控后台管理
Spring Boot Admin 用于监控基于 Spring Boot 的应用,它是在 Spring Boot Actuator 的基础上提供简洁的可视化 WEB UI. 1. 什么是Spring ...
- BAT 脚本判断当前系统是 x86 还是 x64 系统
本文告诉大家在写 BAT 脚本的时候,如何判断当前的系统是 32 位系统的还是 64 位系统 通过注册表进行判断方法 @echo OFF reg Query "HKLM\Hardware\D ...
- JMETER+JENKINS接口测试持续集成
FIDDER+ANT+JENKINS+JMETER+SVN+tomcat接口测试集成 操作流程: 1.测试人员通过FIDDER过滤抓取接口调用信息,导出成jmx文件.(jmeter支持命令行方式调用j ...
- H3C 使用tracert命令
- H3C使用tracert命令--用户视图
<H3C>tracert ? -a 指明 ...
- 【NOIP数据结构专项】单调队列单调栈
[FZYZ P1280 ][NOIP福建夏令营]矩形覆盖 Description 有N个矩形,矩形的底边边长为1,且均在X轴上,高度给出,第i个矩形的高为h[i],求最少需要几个矩形才能覆盖这个图形. ...
- 【Linux】centos查看防火墙是否关闭
查看防火墙的状态的命令为: sudo systemctl status firewalld 打开防火墙的方式有两种,一种是打开后重启会恢复回原来的状态,命令为: sudo systemctl star ...