第二十六篇 玩转数据结构——二分搜索树(Binary Search Tree)
- 跟链表一样,二叉树也是一种动态数据结构,即,不需要在创建时指定大小。
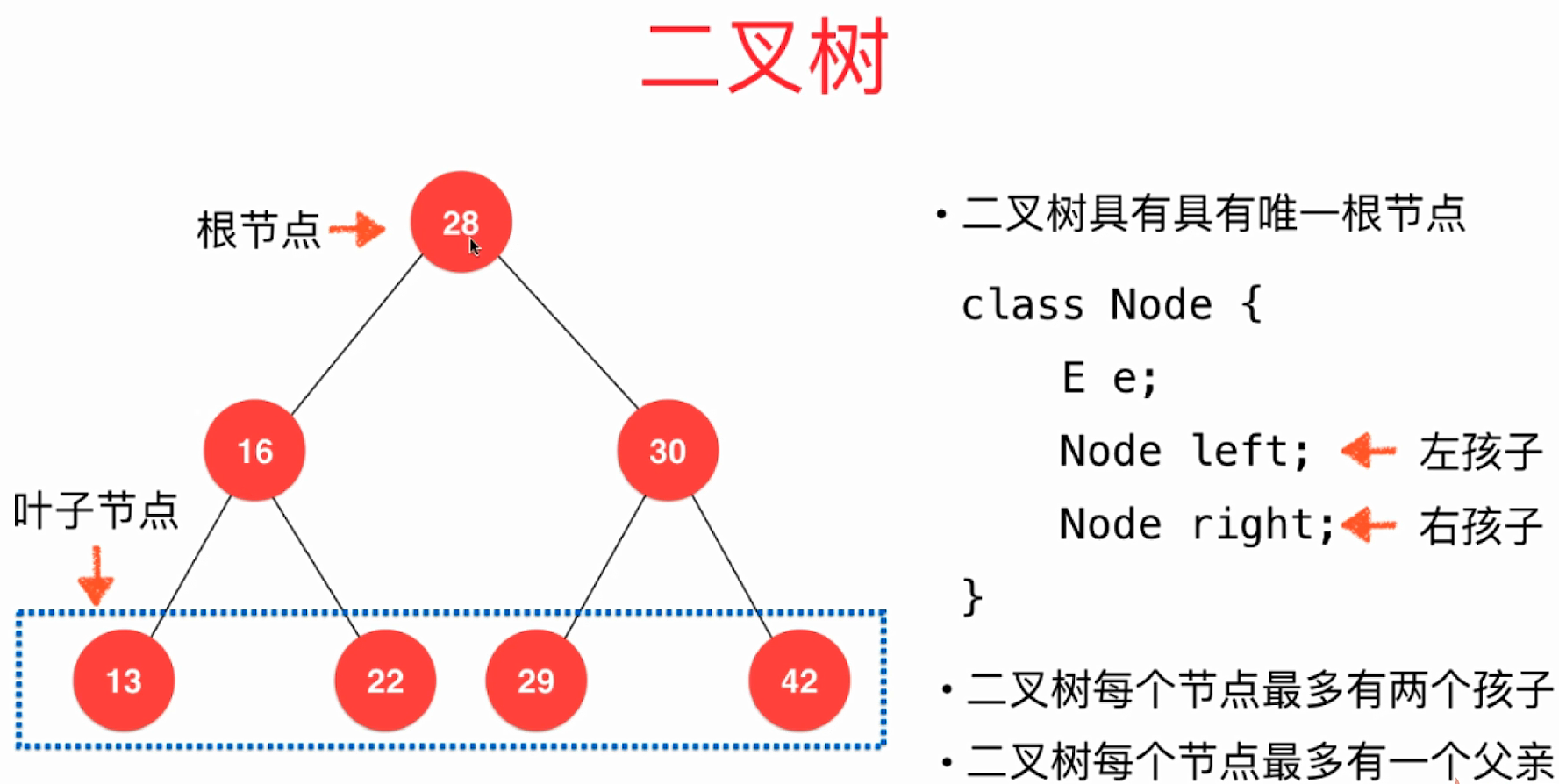
- 跟链表不同的是,二叉树中的每个节点,除了要存放元素e,它还有两个指向其它节点的引用,分别用Node left和Node right来表示。
- 类似的,如果每个节点中有3个指向其它节点的引用,就称其为"三叉树"...
- 二叉树具有唯一的根节点。
- 二叉树中每个节点最多指向其它的两个节点,我们称这两个节点为"左孩子"和"右孩子",即每个节点最多有两个孩子。
- 一个孩子都没有的节点,称之为"叶子节点"。
- 二叉树的每个节点,最多只能有一个父亲节点,没有父亲节点的节点就是"根节点"。
- 二叉树的形象化描述如下图:
- 二叉树具有天然的递归结构。
- 每个节点的"左子树"也是一棵二叉树,每个节点的"右子树"也是一棵二叉树。
- 二叉树不一定是"满的",即,某些节点可能只有一个子节点;更极端一点,整棵二叉树可以仅有一个节点;在极端一点,整棵二叉树可以一个节点都没有;

- 二分搜索树的构造函数、getSize方法、isEmpty方法及add方法的实现逻辑如下:
public class BST<E extends Comparable> { private class Node {
public E e;
public Node left, right; // 构造函数
public Node(E e) {
this.e = e;
left = null;
right = null;
}
} private Node root;
private int size; // 记录二分搜索树中存储的元素个数 public BST() {
root = null;
size = 0;
} // 实现size方法
public int size() {
return size;
} // 实现isEmpty方法
public boolean isEmpty() {
return size == 0;
} // 实现add方法
public void add(E e) {
root = add(root, e);
} // 向以node为根的二分搜索树中插入元素e,递归算法
// 返回插入新节点后二分搜索树的根
private Node add(Node node, E e) { if (node == null) {
size++;
return new Node(e);
} if (e.compareTo(node.e) < 0) {
node.left = add(node.left, e);
} else if (e.compareTo(node.e) > 0) {
node.right = add(node.right, e);
}
return node;
}
}- 二分搜索树的contains方法实现逻辑如下:
// 实现contains方法,判断二分搜索树中是否包含元素e
public boolean contains(E e) {
return contains(root, e);
} // 判断以node为根的二分搜索树中是否包含元素e
private boolean contains(Node node, E e) {
if (node == null) {
return false;
}
if (e.compareTo(node.e) == 0) {
return true;
} else if (e.compareTo(node.e) < 0) {
return contains(node.left, e);
} else {
return contains(node.right, e);
}
}
- 二分搜索树的遍历操作,遍历操作就是把所有节点都访问一遍
- 前序遍历的业务逻辑如下:
//二分搜索树的前序遍历
public void preOder() {
preOrder(root);
} private void preOrder(Node node) { if (node == null) {
return;
} System.out.print(node.e);
preOrder(node.left);
preOrder(node.right);
}- 中序遍历的业务逻辑如下:
// 二分搜索树的中序遍历
public void inOrder() {
inOrder(root);
} // 中序遍历以node为根的二分搜索树,递归算法
private void inOrder(Node node) { if (node == null) {
return;
} inOrder(node.left);
System.out.print(node.e);
inOrder(node.right); }- 后序遍历的业务逻辑如下:
// 二分搜索树的后序遍历
public void postOrder() {
postOrder(root);
} // 后序遍历以node为根的二分搜索树,递归算法
private void postOrder(Node node) { if (node == null) {
return;
}
postOrder(node.left);
postOrder(node.right);
System.out.print(node.e); }- 简单测试如下:
public class Main { public static void main(String[] args) {
BST<Integer> bst = new BST<>();
int[] nums = {5, 3, 6, 8, 4, 2};
for (int num : nums) {
// 测试add方法
bst.add(num);
}
// 测试前序遍历
bst.preOrder();
System.out.println();
// 测试中序遍历
bst.inOrder();
System.out.println();
// 测试后序遍历
bst.postOrder(); }
}- 输出结果:
532468
234568
243865- 前序遍历是最自然的遍历方式,也是最常用的遍历方式;中序遍历的结果是按从小到大的顺序的排列的;后序遍历可以用于为二分搜索树释放内存。
- 利用"栈"实现二分搜索树的非递归前序遍历
// 二分搜索树的非递归前序遍历
public void preOrderNR() {
Stack<Node> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
Node cur = stack.pop();
System.out.print(cur.e);
if (cur.right != null) {
stack.push(cur.right);
}
if (cur.left != null) {
stack.push(cur.left);
}
}
}
- 二分搜索树的非递归实现比递归实现更加复杂。
- 二分搜索树的前序、中序和后续遍历都属于"深度优先"算法。
- 二分搜索树的"层序遍历"属于"广度优先"算法。
- 利用"队列"实现二分搜索树的"层序遍历"
// 二分搜索树的层序遍历
public void levelOrder() {
Queue<Node> q = new LinkedList<>();
q.add(root);
while (!q.isEmpty()) {
Node cur = q.remove();
System.out.print(cur.e);
if (cur.left != null) {
q.add(cur.left);
}
if (cur.right != null) {
q.add(cur.right);
}
}
}- 获取二分搜索树中的最小元素和最大元素
// 寻找二分搜索树中的最小元素
public E minimum() { if (size == 0) {
throw new IllegalArgumentException("BST is empty.");
}
return minimum(root).e; } // 返回以node为根的二分搜索树的最小元素所在节点
private Node minimum(Node node) {
if (node.left == null) {
return node;
}
return minimum(node.left);
} // 寻找二分搜索树中的最大元素
public E maximum() { if (size == 0) {
throw new IllegalArgumentException("BST is empty.");
}
return maximum(root).e; } // 返回以node为根的二分搜索树的最大元素所在节点
private Node maximum(Node node) {
if (node.right == null) {
return node;
}
return maximum(node.right);
}- 删除二分搜索树中最小元素和最大元素所在节点
// 从二分搜索树中删除最小元素所在节点,返回最小元素
public E removeMin() {
E ret = minimum();
root = removeMin(root);
return ret;
} // 删除掉以node为根的二分搜索树中的最小元素所在节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node) {
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}
node.left = removeMin(node.left);
return node;
} // 从二分搜索树中删除最大元素所在节点,返回最小元素
public E removeMax() {
E ret = maximum();
root = removeMax(root);
return ret;
} // 删除掉以node为根的二分搜索树中的最小元素所在节点
// 返回删除节点后新的二分搜索树的根
private Node removeMax(Node node) {
if (node.right == null) {
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
}
node.right = removeMax(node.right);
return node;
}- 删除二分搜索树中指定元素所对应的节点
// 从二分搜索树中删除元素为e的节点
public void remove(E e) {
remove(root, e);
} // 删除以node为根节点的二分搜索树中元素为e的节点,递归算法
// 返回删除节点后新的二分搜索树的根
private Node remove(Node node, E e) {
if (node == null) {
return null;
} if (e.compareTo(node.e) < 0) {
node.left = remove(node.left, e);
return node;
} else if (e.compareTo(node.e) > 0) {
node.right = remove(node.right, e);
return node;
} else {
// 待删除节点左子树为空的情况
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
// 待删除节点右子树为空的情况
} else if (node.right == null) {
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
// 待删除节点左右子树均不为空
// 找到比待删除节点大的最小节点,即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点
} else {
Node successor = minimum(node.right);
successor.right = removeMin(node.right); //这里进行了size--操作
successor.left = node.left;
node.left = null;
node.right = null;
return successor;
}
}
}
第二十六篇 玩转数据结构——二分搜索树(Binary Search Tree)的更多相关文章
- 第二十九篇 玩转数据结构——线段树(Segment Tree)
1.. 线段树引入 线段树也称为区间树 为什么要使用线段树:对于某些问题,我们只关心区间(线段) 经典的线段树问题:区间染色,有一面长度为n的墙,每次选择一段墙进行染色(染色允许覆盖),问 ...
- 第三十二篇 玩转数据结构——AVL树(AVL Tree)
1.. 平衡二叉树 平衡二叉树要求,对于任意一个节点,左子树和右子树的高度差不能超过1. 平衡二叉树的高度和节点数量之间的关系也是O(logn) 为二叉树标注节点高度并计算平衡因子 AVL ...
- 第二十八篇 玩转数据结构——堆(Heap)和有优先队列(Priority Queue)
1.. 优先队列(Priority Queue) 优先队列与普通队列的区别:普通队列遵循先进先出的原则:优先队列的出队顺序与入队顺序无关,与优先级相关. 优先队列可以使用队列的接口,只是在 ...
- 第二十五篇 玩转数据结构——链表(Linked List)
1.. 链表的重要性 我们之前实现的动态数组.栈.队列,底层都是依托静态数组,靠resize来解决固定容量的问题,而"链表"则是一种真正的动态数据结构,不需要处理固定容 ...
- 第二十四篇 玩转数据结构——队列(Queue)
1.. 队列基础 队列也是一种线性结构: 相比数组,队列所对应的操作数是队列的子集: 队列只允许从一端(队尾)添加元素,从另一端(队首)取出元素: 队列的形象化描述如下图: 队列是一种先进 ...
- 数据结构 《5》----二叉搜索树 ( Binary Search Tree )
二叉树的一个重要应用就是查找. 二叉搜索树 满足如下的性质: 左子树的关键字 < 节点的关键字 < 右子树的关键字 1. Find(x) 有了上述的性质后,我们就可以像二分查找那样查找给定 ...
- 数据结构 -- 二叉树(Binary Search Tree)
一.简介 在计算机科学中,二叉树是每个结点最多有两个子树的树结构.通常子树被称作“左子树”(left subtree)和“右子树”(right subtree).二叉树常被用于实现二叉查找树和二叉堆. ...
- 第二十六篇 jQuery 学习8 遍历-父亲兄弟子孙元素
jQuery 学习8 遍历-父亲兄弟子孙元素 jQuery遍历,可以理解为“移动”,使用“移动”还获取其他的元素. 什么意思呢?老师举一个例子: 班上30位同学,我是新来负责教这个班学生的老师 ...
- 第二十六篇:两个SOUI新控件 ---- SListView和SComboView(借用Andorid的设计)
SOUI原来实现的SListBoxEx的效率一直是我对SOUI不太满意的地方.包括后来网友实现的SListCtrlEx. 这类控件为每一个列表项创建一个SWindow来容纳数据,当数据量比较大(100 ...
随机推荐
- Python中numpy模块的简单使用
# encoding:utf-8 import numpy as np data1 = np.array([1, 2, 3, 4, 5]) print(data1) data2 = np.array( ...
- 分类问题(三)混淆矩阵,Precision与Recall
混淆矩阵 衡量一个分类器性能的更好的办法是混淆矩阵.它基于的思想是:计算类别A被分类为类别B的次数.例如在查看分类器将图片5分类成图片3时,我们会看混淆矩阵的第5行以及第3列. 为了计算一个混淆矩阵, ...
- linux 6.9 补丁修补漏洞
1 先将openssh-8.0p1.tar.gz 上传到 root下的/opt 文件夹下 解压 tar -zxvf openssh-8.0p1.tar.gz -C /opt 2 启动vncserv ...
- 占位 CP
占位 CP include: CP403 CP404 CP405
- AntDesign(React)学习-3 React基础
前面项目已经建起来了,但是没有React基础怎么办,从头学习,这个项目使用的是基于React16.X版本的几种技术集成,那么我们就从网上找一些相关的资料进行研究,我的习惯是用到哪学到哪. 一.先看一些 ...
- 《 Java 编程思想》CH07 复用类
复用代码是 Java 众多引人注目的功能之一. Java 可以通过创建类来复用代码,要在使用类的时候不破坏现有代码,有两种方式: 组合:在新的类中使用现有类的对象. 继承:按照现有类的类型来创建新类, ...
- npm 配置国内源
淘宝镜像 npm config set registry http://registry.npm.taobao.org
- day04_1hibernate
log4j的整合.一对一关系的操作.二级缓存的介绍 一.log4j的整合: 1.介绍什么是 slf4j 核心jar : slf4j-api-1.6.1.jar .slf4j是日志框架,将其他优秀的日 ...
- 【网页浏览】国内伪P站搜图网站
蛮好用的国内p站搜图网站(伪p站) 传送链接
- SSM-整合简单配置
首先说明Spring和Mybatis的版本: Spring:3.2.4 Mybatis:3.3.0 使用了C3P0连接池和Log4J日志,下面是jar包总览: 然后是项目目录总览: 为了能够让项目跑一 ...