tf.train.string_input_producer()
处理从文件中读数据
官方说明
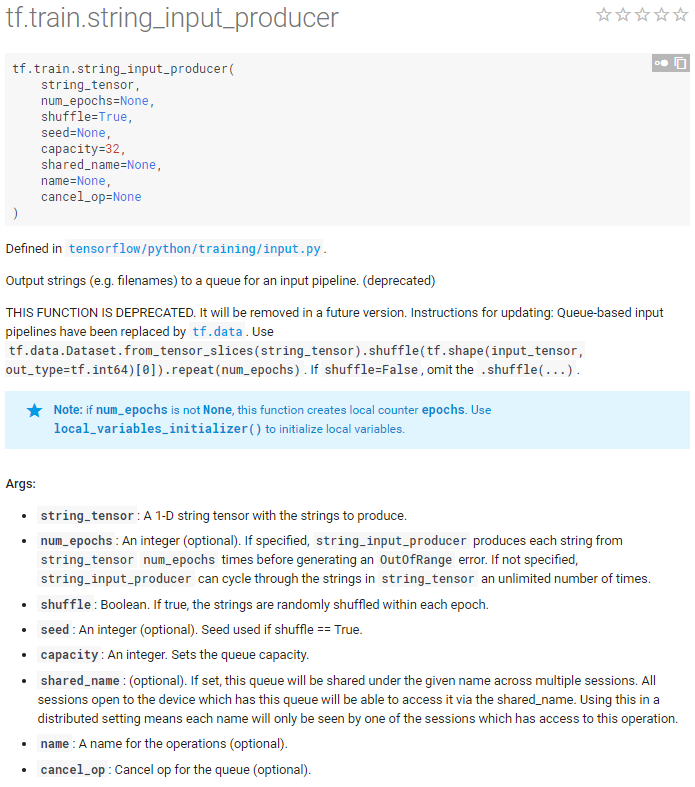
简单使用
示例中读取的是csv文件,如果要读tfrecord的文件,需要换成 tf.TFRecordReader
import tensorflow as tf
filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"]) reader = tf.TextLineReader()
key, value = reader.read(filename_queue) # Default values, in case of empty columns. Also specifies the type of the decoded result.
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value, record_defaults=record_defaults)
features = tf.stack([col1, col2, col3, col4]) with tf.Session() as sess:
# Start populating the filename queue.
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord) for i in range(12):
# Retrieve a single instance:
example, label = sess.run([features, col5])
print(example, label) coord.request_stop()
coord.join(threads)
运行结果:

结合批处理
import tensorflow as tf
def read_my_file_format(filename_queue):
# reader = tf.SomeReader()
reader = tf.TextLineReader()
key, record_string = reader.read(filename_queue)
# example, label = tf.some_decoder(record_string)
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(record_string, record_defaults=record_defaults)
# processed_example = some_processing(example)
features = tf.stack([col1, col2, col3, col4])
return features, col5 def input_pipeline(filenames, batch_size, num_epochs=None):
filename_queue = tf.train.string_input_producer(filenames, num_epochs=num_epochs, shuffle=True)
example, label = read_my_file_format(filename_queue)
# min_after_dequeue + (num_threads + a small safety margin) * batch_size
min_after_dequeue = 100
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch([example, label], batch_size=batch_size, capacity=capacity,
min_after_dequeue=min_after_dequeue)
return example_batch, label_batch x,y = input_pipeline(["file0.csv", "file1.csv"],5,4) sess = tf.Session()
sess.run([tf.global_variables_initializer(),tf.initialize_local_variables()]) coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord) try:
print("in try")
while not coord.should_stop():
# Run training steps or whatever
example, label = sess.run([x,y])
print(example, label)
print("ssss") except tf.errors.OutOfRangeError:
print ('Done training -- epoch limit reached')
finally:
# When done, ask the threads to stop.
coord.request_stop() # Wait for threads to finish.
coord.join(threads)
sess.close()
运行结果:

tf.train.string_input_producer()的更多相关文章
- 深度学习原理与框架-Tfrecord数据集的读取与训练(代码) 1.tf.train.batch(获取batch图片) 2.tf.image.resize_image_with_crop_or_pad(图片压缩) 3.tf.train.per_image_stand..(图片标准化) 4.tf.train.string_input_producer(字符串入队列) 5.tf.TFRecord(读
1.tf.train.batch(image, batch_size=batch_size, num_threads=1) # 获取一个batch的数据 参数说明:image表示输入图片,batch_ ...
- Tensorflow读取大数据集的方法,tf.train.string_input_producer()和tf.train.slice_input_producer()
1. https://blog.csdn.net/qq_41427568/article/details/85801579
- tf.train.batch的偶尔乱序问题
tf.train.batch的偶尔乱序问题 觉得有用的话,欢迎一起讨论相互学习~Follow Me tf.train.batch的偶尔乱序问题 我们在通过tf.Reader读取文件后,都需要用batc ...
- tf.train.ExponentialMovingAverage
这个函数可以参考吴恩达deeplearning.ai中的指数加权平均. 和指数加权平均不一样的是,tensorflow中提供的这个函数,能够让decay_rate随着step的变化而变化.(在训练初期 ...
- Tensorflow滑动平均模型tf.train.ExponentialMovingAverage解析
觉得有用的话,欢迎一起讨论相互学习~Follow Me 移动平均法相关知识 移动平均法又称滑动平均法.滑动平均模型法(Moving average,MA) 什么是移动平均法 移动平均法是用一组最近的实 ...
- tf.train.shuffle_batch函数解析
tf.train.shuffle_batch (tensor_list, batch_size, capacity, min_after_dequeue, num_threads=1, seed=No ...
- 图融合之加载子图:Tensorflow.contrib.slim与tf.train.Saver之坑
import tensorflow as tf import tensorflow.contrib.slim as slim import rawpy import numpy as np impor ...
- 深度学习原理与框架-图像补全(原理与代码) 1.tf.nn.moments(求平均值和标准差) 2.tf.control_dependencies(先执行内部操作) 3.tf.cond(判别执行前或后函数) 4.tf.nn.atrous_conv2d 5.tf.nn.conv2d_transpose(反卷积) 7.tf.train.get_checkpoint_state(判断sess是否存在
1. tf.nn.moments(x, axes=[0, 1, 2]) # 对前三个维度求平均值和标准差,结果为最后一个维度,即对每个feature_map求平均值和标准差 参数说明:x为输入的fe ...
- 深度学习原理与框架-Tfrecord数据集的制作 1.tf.train.Examples(数据转换为二进制) 3.tf.image.encode_jpeg(解码图片加码成jpeg) 4.tf.train.Coordinator(构建多线程通道) 5.threading.Thread(建立单线程) 6.tf.python_io.TFR(TFR读入器)
1. 配套使用: tf.train.Examples将数据转换为二进制,提升IO效率和方便管理 对于int类型 : tf.train.Examples(features=tf.train.Featur ...
随机推荐
- 安装babel-preset-stage-0为了不打包所有的组件
今天 看到一段话 是否是我们可以通过这个自定义多种组件,但是只选择我们需要的组件进行打包
- pytest相关资源收集
pytest官网 https://docs.pytest.org/en/latest/getting-started.html 官网推荐的plugin https://docs.pytest.org/ ...
- 大数据ETL详解
ETL是BI项目最重要的一个环节,通常情况下ETL会花掉整个项目的1/3的时间,ETL设计的好坏直接关接到BI项目的成败.ETL也是一个长期的过程,只有不断的发现问题并解决问题,才能使ETL运行效率更 ...
- cp和mv命令
注意事项:mv与cp的结果不同,mv好像文件“搬家”,文件个数并未增加.而cp对文件进行复制,文件个数增加了. 一.cp命令 cp命令用来将一个或多个源文件或者目录复制到指定的目的文件或目录.它可以将 ...
- BKDRHash算法的初步了解
字符串hash最高效的算法, 搜了一下, 原理是: 字符串的字符集只有128个字符,所以把一个字符串当成128或更高进制的数字来看,当然是唯一的 这里unsigned不需要考虑溢出的问题, 不过 ...
- Android实战:手把手实现“捧腹网”APP(三)-----UI实现,逻辑实现
Android实战:手把手实现"捧腹网"APP(一)-–捧腹网网页分析.数据获取 Android实战:手把手实现"捧腹网"APP(二)-–捧腹APP原型设计.实 ...
- 【JZOJ4854】【NOIP2016提高A组集训第6场11.3】小澳的坐标系
题目描述 小澳者表也,数学者景也,表动则景随矣. 小澳不喜欢数学,可数学却待小澳如初恋,小澳睡觉的时候也不放过. 小澳的梦境中出现了一个平面直角坐标系,自原点,向四方无限延伸. 小澳在坐标系的原点,他 ...
- MySQL整数类型字段的长度总结
MySQL还支持选择在该类型关键字后面的括号内指定整数值的显示宽度(例如,INT(4)). 该可选显示宽度规定用于显示宽度小于指定的列宽度的值时从左侧填满宽度.(类似使用LPAD函数效果) 在INT( ...
- QT_OPENGL-------- 2.shader
用可编程管线绘制一个三角形 1.以上一节window为基准,进行绘制. 2.下载编译glew,并在.pro添加动态链接,并在头文件中引用. LIBS +=-L/usr/lib64 -lGLEW 可能根 ...
- C++返回值优化
返回值优化(Return Value Optimization,简称RVO)是一种编译器优化机制:当函数需要返回一个对象的时候,如果自己创建一个临时对象用于返回,那么这个临时对象会消耗一个构造函数(C ...