day04_1hibernate
log4j的整合、一对一关系的操作、二级缓存的介绍
一、log4j的整合:
1.介绍什么是 slf4j 核心jar :
slf4j-api-1.6.1.jar 。slf4j是日志框架,将其他优秀的日志第三方进行整合。
2.如何整合log4j:(前提已将hibernate框架搭建好了)
第一步导包:将log4j 核心包:log4j-1.2.17.jar 转化包 slf4j-log4j12-1.7.5.jar:这是将slf4j转换成log4j的过渡包,导入到创建好的lib目录下
第二步导入配置文件:log4j.properties ,此配置文件通知log4j 如何输出日志,此配置文件在hibernate的project的etc目录下
### direct log messages to stdout ###
log4j.appender.stdout=org.apache.log4j.ConsoleAppender 表示: 输出源
log4j.appender.stdout.Target=System.err 表示:输出的目标
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout 表示输出的样式
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n 表示输出的格式 ### direct messages to file hibernate.log ###
log4j.appender.file=org.apache.log4j.FileAppender 表示:输出源是一个文件类型
log4j.appender.file.File=d\:hibernate.log 表示:输出到指定文件下
log4j.appender.file.layout=org.apache.log4j.PatternLayout 表示:输出的样式
log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n 表示:输出的格式 ### set log levels - for more verbose logging change 'info' to 'debug' ### log4j.rootLogger=info, stdout, file 表示:根配置
#log4j.rootLogger=日志级别, 输出源1,输出源2,....
根配置的格式:log4j.rootLogger=日志级别, 输出源1,输出源2,....
log4j 日志级别 : fatal 致命错误 error 错误 warn 警告 info 信息 debug 调试信息 trace 堆栈信息 (由高到底顺序)
第三步:正常使用即可,根据上述代码它会将日志信息分别打印输出源指定的地方,一个是控制台,一个是文件下
二、一对一关系的介绍和操作(了解):
1.关于操作一对一有两种方式:
情况1:主表的主键,与从表的外键(唯一),形成主外键关系
情况2:主表的主键,与从表的主键,形成主外键关系 (从表的主键又是外键)
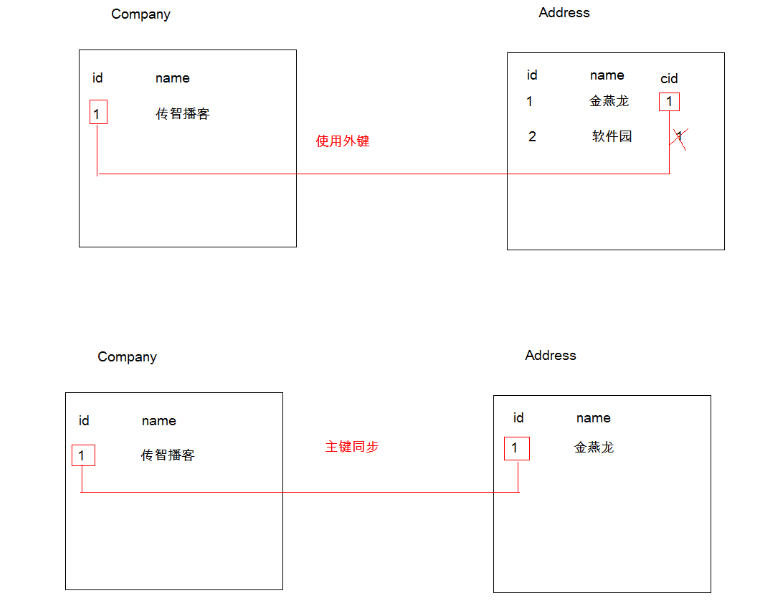
这里我们把公司和公司地址作为一对一关系的存在:
情况1:当形成主外键的形式配置文件为:
public class Company {
private Integer id;
private String name;
private Address address;//类似于一对多的配置,为了产生关联需要在两边都加上属性关联
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
@Override
public String toString() {
return "Company [id=" + id + ", name=" + name + ", address=" + address
+ "]";
}
}
Company的持久类
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.a.one_to_one">
<class name="Company" table="t_company">
<!-- 一对一配置之外键唯一的配置 -->
<id name="id" column="id" >
<generator class="native"></generator>
</id> <property name="name" length="20"></property>
<!-- 配置一对一
one-to-one:默认使用主键同步策略完成一对一的表的体现,默认用主键id去找关联
property-ref:指定company在一对一关联时,指向哪个属性
-->
<one-to-one name="address" class="Address" property-ref="company"></one-to-one> </class> </hibernate-mapping>
Company.hbm.xml
public class Address {
private Integer id;
private String name;
private Company company;//一对一时为了两方产生关联必须两方配置关联属性
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Company getCompany() {
return company;
}
public void setCompany(Company company) {
this.company = company;
}
@Override
public String toString() {
return "Address [id=" + id + ", name=" + name + "]";
}
}
Address的持久化类
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.a.one_to_one">
<class name="Address" table="t_address">
<!-- 一对一配置之外键唯一的配置 -->
<id name="id" column="id" >
<generator class="native"></generator>
</id> <property name="name" length="20"></property>
<!-- 多对一怎么配我们还怎么配 unique:唯一指外键唯一 不能多个引用 -->
<many-to-one name="company" class="Company" column="cid" unique="false"></many-to-one>
</class> </hibernate-mapping>
Address.hbm.xml
import org.hibernate.Transaction;
import org.hibernate.classic.Session;
import org.junit.Test; import cn.itcast.Hibernate.utils.HibernateUtils;
import cn.itcast.a.domain.Customer; public class Test01 {
@Test//一对一的操作
public void fun01(){//保存一对一数据
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Company company =new Company();
company.setName("传智播客"); Address address =new Address();
address.setName("金燕龙");
//注意:在一对一使用外键时,外键所在的对象才能维护关系,另一方无法维护关系
address.setCompany(company); session.save(company);
session.save(address);
//----------------------------------------
transaction.commit();
session.close(); } @Test//一对一的操作 关于一对一的查询
public void fun02(){//一对一查询会自动使用外连接查询
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Company company =(Company) session.get(Company.class, 1);
System.out.println(company);
//----------------------------------------
transaction.commit();
session.close(); } }
测试类
这里我们需要在两个持久化类中进行关联,分别引入关联的属性对象
情况2:主表的主键,与从表的主键,形成主外键关系 (从表的主键又是外键)
这里上述的持久化类不用做修改只需要修改ORM映射文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.a.one_to_one">
<class name="Company" table="t_company">
<!-- 使用的是hibernate默认的主键同步,要是实在记不住就算了没必要 一对一的例子很少出现 -->
<id name="id" column="id" >
<generator class="native"></generator>
</id> <property name="name" length="20"></property>
<!-- 配置一对一
one-to-one:默认使用主键同步策略完成一对一的表的体现,默认用主键id去找关联
可以使用cascade:
可以使用fetch:
可以使用lazy:
使用起来和以前一对多一样
-->
<one-to-one name="address" class="Address"></one-to-one> </class> </hibernate-mapping>
Company.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.a.one_to_one">
<class name="Address" table="t_address">
<!-- 使用的是hibernate默认的主键同步,要是实在记不住就算了没必要 一对一的例子很少出现 -->
<id name="id" column="id" >
<!-- foreign:该主键即是主键又是外键 -->
<generator class="foreign">
<!-- 做外键时引用哪个属性 -->
<param name="property">company</param>
</generator>
</id> <property name="name" length="20"></property>
<!-- 多对一怎么配我们还怎么配 unique:唯一指外键唯一 不能多个引用 -->
<one-to-one name="company" class="Company" constrained="true" ></one-to-one>
</class> </hibernate-mapping>
Address.hbm.xml
import org.hibernate.Transaction;
import org.hibernate.classic.Session;
import org.junit.Test; import cn.itcast.Hibernate.utils.HibernateUtils;
import cn.itcast.a.domain.Customer; public class Test02 {
@Test//一对一的操作之使用主键同步策略
public void fun01(){//保存一对一数据
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Company company =new Company();
company.setName("传智播客"); Address address =new Address();
address.setName("金燕龙");
//注意:在一对一使用外键时,外键所在的对象才能维护关系,另一方无法维护关系
address.setCompany(company); session.save(company);
session.save(address);
//----------------------------------------
transaction.commit();
session.close(); } @Test//一对一的操作之主键同步的默认配置 关于一对一的查询
public void fun02(){//一对一查询会自动使用外连接查询
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Company company =(Company) session.get(Company.class, 1);
System.out.println(company);
//----------------------------------------
transaction.commit();
session.close(); } }
测试类
因为一对一不太常见如果有不懂的可以去看视频。
三、二级缓存介绍与操作
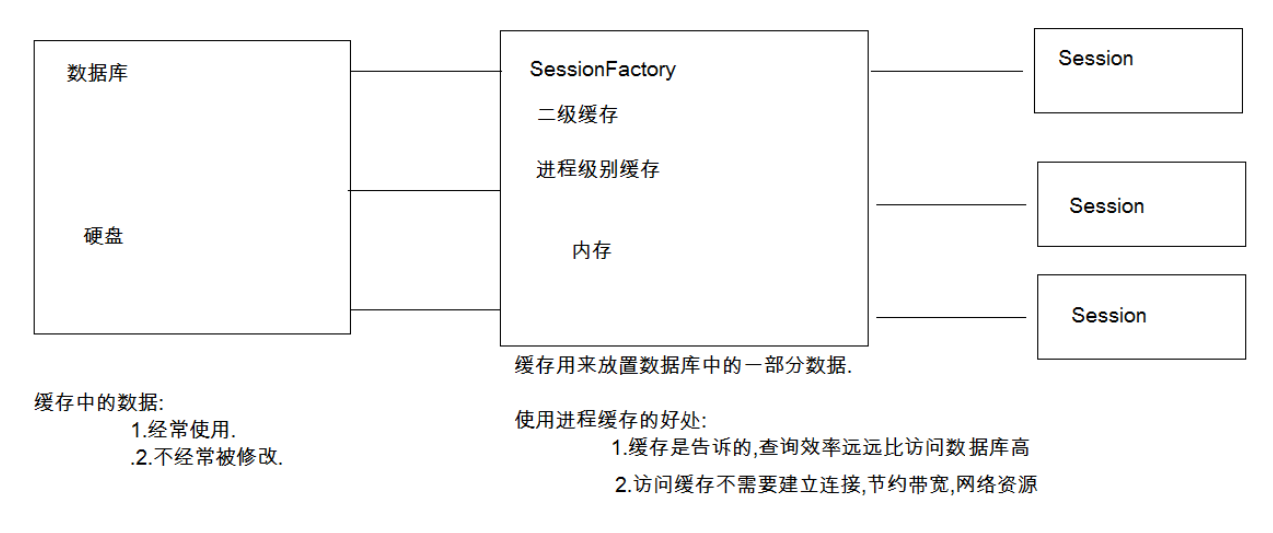
1.hibernate中提供了两个级别的缓存:
第一级别的缓存是Session级别的缓存,它是属于事务范围的缓存。这一级别的缓存由hibernate管理,一遍情况下无须进行干预。第二级别的缓存是SessionFactory级别的缓存,它属于进程范围的缓存。这一级别的缓存是一个可拔的缓存插件,它是由SessionFactory负责管理的。
2.SessionFactory级别的缓存的分类:
SessionFactory的缓存两部分: 内置缓存:使用一个Map,用于存放配置信息,预定义HQL语句等,提供给Hibernate框架自己使用,对外只读的。不能操作。也被称为Hibernate的第一级缓存。
外置缓存:使用另一个Map,用于存放用户自定义数据。默认不开启。外置缓存hibernate只提供规范(接口),需要第三方实现类。外置缓存又称为二级缓存。它是一个可配置的缓存插件,外置缓存的物理介质可以是内存或硬盘
3.二级缓存的结构:
在hibernate中二级缓存可分为四类:类级别的缓存:主要用来存储PO(实体)对象
、集合级别的缓存:用于存储集合数据、查询缓存:会缓存一些常用于查询语句的查询结果、更新时间戳缓存:该区域存放了与查询结果相关的表在进行插入、更新或删除操作的时间戳,hibernate通过更新时间戳缓存区域来判断被缓存的查询结果是否过期
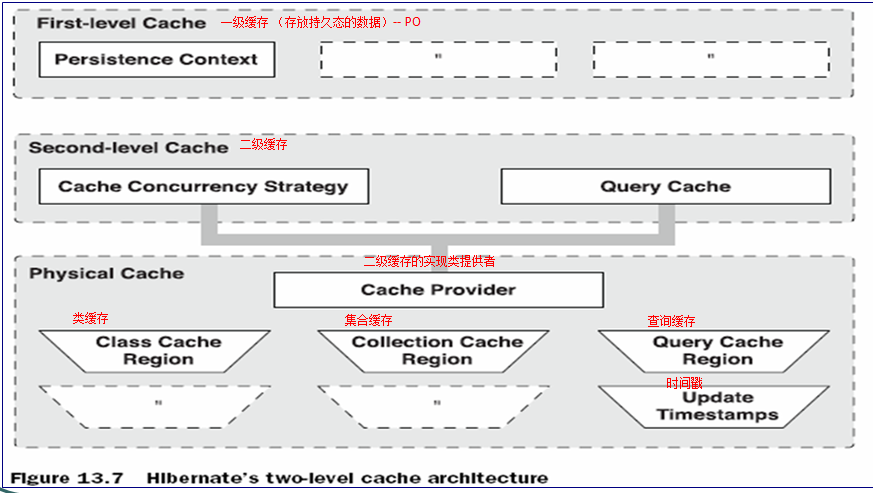
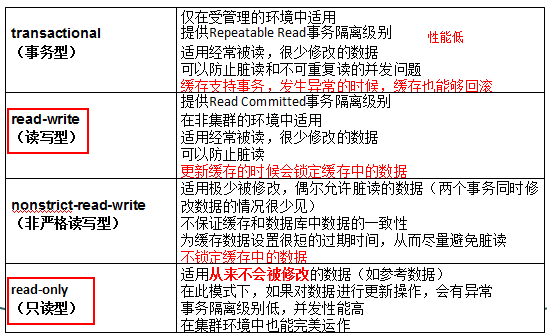
4.二级缓存的并发访问策略:
两个并发的事务同时访问持久层缓存的相同数据时,可能会出现各类并发问题,所需要采用必要的隔离v措施解决这些问题。由于二级缓存中也会出现并发问题,因此在hibernate的二级缓存中,可以设定4种访问类型的并发访问策略来解决这些问题,每一种访问策略对应一种事务隔离级别,具体介绍如下:
5.二级缓存的插件:
hibernate的二级缓存功能是通过配置二级缓存的插件来实现的,常用的二级缓存插件有:
EHCache: 可作为进程(单机)范围内的缓存, 存放数据的物理介质可以是内存或硬盘, 对 Hibernate 的查询缓存提供了支持。--支持集群。
OpenSymphony `:可作为进程范围内的缓存, 存放数据的物理介质可以是内存或硬盘, 提供了丰富的缓存数据过期策略, 对 Hibernate 的查询缓存提供了支持
SwarmCache: 可作为集群范围内的缓存, 但不支持 Hibernate 的查询缓存
JBossCache:可作为集群范围内的缓存, 支持 Hibernate 的查询缓存

并不是所有的数据都适合放到二级缓存当中,在通常情况下可以将很少被修改、不是很重要的,且不会被并发访问的数据放置在二级缓存中
而经常被修改的或者财务数据(绝对不允许出现并发问题)以及与其他应用数据共享的数据,不适合放到二级缓存中
其中EHCache缓存插件是理想的进程范围的缓存实现,下面就以EHCache缓存插件为例,介绍二级缓存的配置和使用
6.EHCache缓存插件的使用:
第一步引入jar包:ehcache-1.5.0.jar/ commons-logging.jar/ backport-util-concurrent.jar(这三个包都需要导入引文核心包ehcache-1.5.0.jar依赖于另外两个)
第二步引入ehcache.xml的配置文件,这个文件在EHCache的jar包里面有相应的ehcache-failsafe.xml文件可以对照着仿写,当我们导入进去时需要把名称改为ehcache.xml。这样就可以自动加载这里面的配置。注意这个是相当于自己定制配置文件,若不配也会有默认的值
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<diskStore path="java.io.tmpdir"/><!-- 设置缓存数据文件的存储目录-->
<defaultCache <!--设置缓存的默认数据过期策略-->
maxElementsInMemory="10000"<!--设置缓存对象的最大数目>
eternal="false" <!--指定是否永不过期 true为不过期 false为过期-->
timeToIdleSeconds="120"<!--设置对象处于空闲状态的最大秒数-->
timeToLiveSeconds="120"<!--设置对象处于缓存状态的最大秒数--》
overflowToDisk="true"<!--内存溢出时是否将溢出对象写入到硬盘中-->
maxElementsOnDisk="10000000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>
</ehcache>
7.二级缓存的四种缓存级别的介绍和操作
①类级别缓存:将类的实例放置到一级缓存中,在类级别缓存存放查询实体的真实值(散装数据)
我们需要在Ehcache配置完成的基础上配置hibernate配置文件 ,开启二级缓存(默认是关闭的),指定二级缓存供应商(键值对可以去hibernate.properties里面查找),指定ORM映射文件,指定哪些数据放到二级缓存中
<!-- 开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 指定二级缓存的供应商 -->
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property> <mapping resource="cn/itcast/a/domain/Customer.hbm.xml" />
<!-- 指定哪些数据存放到二级缓存当中 -->
<!-- 配置类缓存区中,缓存哪个类 类缓存 需要放在mapping元素后面
usage:缓存的隔离级别 class:完整的类名
-->
<class-cache usage="read-only" class="cn.itcast.a.domain.Customer"/>
配置好上面的配置文件后就可以创建一个测试类来测试
@Test//二级缓存中的类级别缓存(需要在hibernate文件中指定存放的二级缓存中的数据)
public void fun01(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Customer customer1 =(Customer) session.get(Customer.class, 1);
Customer customer2 =(Customer) session.get(Customer.class, 1);
System.out.println(customer1==customer2);//这个是证明了一级缓存的存在
session.clear();//清空一级缓存区的内容
Customer customer3 =(Customer) session.get(Customer.class, 1);
Customer customer4 =(Customer) session.get(Customer.class, 1); System.out.println(customer3==customer4);
//----------------------------------------
transaction.commit();
session.close(); }
证明二级缓存的存在
二级缓存在缓存数据时,并不是以对象的形式缓存,缓存的是对象数据的散列,每次从二级缓存拿 会在一级缓存中组装成对象。这是因为防止二级缓存中的数据被修改
@Test//二级缓存中的类级别缓存(需要在hibernate文件中指定存放的二级缓存中的数据)
public void fun02(){//证明二级缓存中缓存的不是对象。(因为二级缓存是进程级别的缓存我们不能把它变为对象进行缓存,放在别人对这个对象进行修改)
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Customer customer1 =(Customer) session.get(Customer.class, 1); session.clear();//清空一级缓存区的内容
Customer customer2 =(Customer) session.get(Customer.class, 1); System.out.println(customer1==customer2);//false
//二级缓存在缓存数据时,并不是以对象的形式缓存,缓存的是对象数据的散列,每次从二级缓存拿 会在一级缓存中组装成对象。
//----------------------------------------
transaction.commit();
session.close(); }
证明二级缓存里面存储的不是对象
注意放二级缓存里面的是对象数据的散列并不是对象,对象是拿到一级缓存中进行的组装
类缓存:只存放数据
一级缓存:存放对象本身
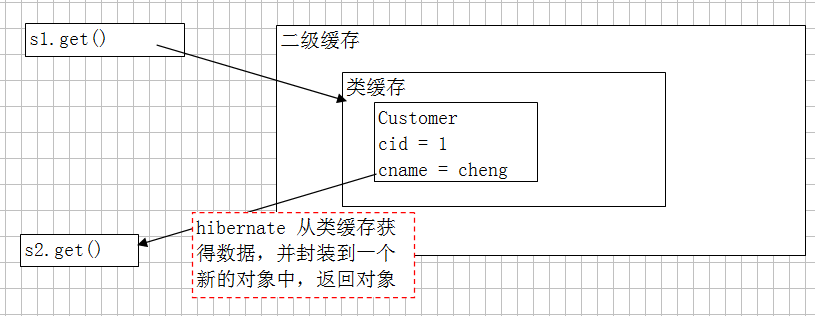
②集合级别缓存:存放的查询条件(即OID),真实的实体在类级别的二级缓存中
根据类级别缓存配置的基础上配置集合级别缓存的配置
<!-- 配置类缓存区中,缓存哪个类 类缓存 需要放在mapping元素后面
usage:缓存的隔离级别 class:完整的类名
-->
<class-cache usage="read-only" class="cn.itcast.a.domain.Customer"/>
<class-cache usage="read-only" class="cn.itcast.a.domain.Order"/>
<!-- 配置类缓存区中,缓存哪个类 集合级别缓存 需要依赖着类缓存
collection:完整类名.集合属性名
注意:集合级别的缓存依赖类级别的缓存所以我们要在上面配置Order的类级别缓存
-->
<collection-cache usage="read-only" collection="cn.itcast.a.domain.Customer.orders"/> </session-factory>
配置好上面的配置文件后就可以创建一个测试类来测试
@Test//二级缓存中的集合级别缓存(需要在hibernate文件中配置二级缓存集合级别的配置,而且还要配置集合对应的类级别缓存配置)
public void fun01(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Customer customer =(Customer) session.get(Customer.class, 1);
for (Order o :customer.getOrders()) {
System.out.println(o.getAddress());
} session.clear();//清除一级缓存数据 Customer customer2 =(Customer) session.get(Customer.class, 1);
//可以发现遍历集合时也没有打印语句说明集合级别缓存的存在
for (Order o :customer2.getOrders()) {
System.out.println(o.getAddress());
} //----------------------------------------
transaction.commit();
session.close(); }
集合级别的二级缓存
为什么需要配置对应集合的类级别缓存配置呢?我们下面演示将对应的类级别删除后会是一个什么样子
<class-cache usage="read-only" class="cn.itcast.a.domain.Order"/>将这条配置删除后测试代码如下
@Test//二级缓存中的集合级别缓存(如果不添加对应的类缓存配置会出怎么样的错误,首先删除掉对应集合的类缓存配置)
public void fun02(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Customer customer =(Customer) session.get(Customer.class, 1);
for (Order o :customer.getOrders()) {
System.out.println(o.getAddress());
} session.clear();//清除一级缓存数据 Customer customer2 =(Customer) session.get(Customer.class, 1);
//使用迭代器来遍历看的更清除,因为增强for会一口气将数据全部取出而迭代器则是一个一个迭代的
Iterator<Order> iterator=customer2.getOrders().iterator();
while(iterator.hasNext()){
Order order=iterator.next();
System.out.println(order.getAddress());
}
//----------------------------------------
transaction.commit();
session.close(); }
不添加对应的类缓存配置
我们知道了类级别缓存里面装载的是对象的散装数据并没有放进对象里面那么,集合级别的二级缓存里面存放的是什么呢?
其实集合级别缓存的是从类缓存里带下来的id,根据Order的id去找对应的数据,如果找不到就会去数据库中找所以这个就算需要配置对应类级别缓存的原因,防止多次访问数据库?
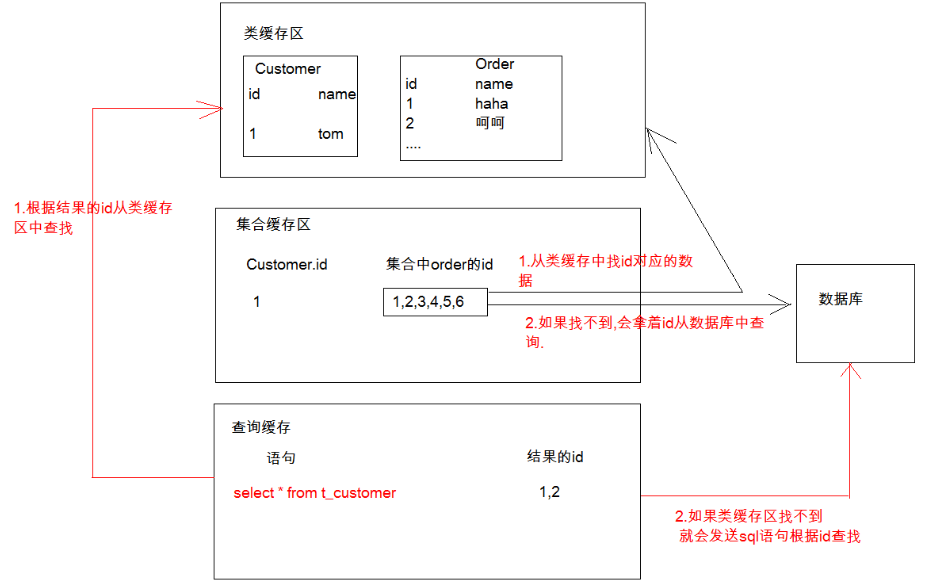
③查询缓存:存放的查询条件(即OID),真实的实体在类级别的二级缓存中
我们需要在上面配置的基础上再,配置我们需要打开查询缓存,开启查询缓存 注意查询缓存还要单独开启 在hibernate.xml里面找配置信息
hibernate.cache.use_query_cache true,然后这就打开了这个开关,这是第一步。
<!-- 开启查询缓存 注意查询缓存还要单独开启 在hibernate.xml里面找配置信息
hibernate.cache.use_query_cache true
-->
<property name="hibernate.cache.use_query_cache">true</property>
<mapping resource="cn/itcast/a/domain/Customer.hbm.xml" />
<mapping resource="cn/itcast/a/domain/Order.hbm.xml" />
<mapping resource="cn/itcast/a/one_to_one/Address.hbm.xml" />
<mapping resource="cn/itcast/a/one_to_one/Company.hbm.xml" /> <!-- 指定哪些数据存放到二级缓存当中 --> <!-- 配置类缓存区中,缓存哪个类 类缓存 需要放在mapping元素后面
usage:缓存的隔离级别 class:完整的类名
-->
<class-cache usage="read-only" class="cn.itcast.a.domain.Customer"/>
<class-cache usage="read-only" class="cn.itcast.a.domain.Order"/>
<!-- 配置类缓存区中,缓存哪个类 集合级别缓存 需要依赖着类缓存
collection:完整类名.集合属性名
注意:集合级别的缓存依赖类级别的缓存所以我们要在上面配置Order的类级别缓存
-->
<collection-cache usage="read-only" collection="cn.itcast.a.domain.Customer.orders"/> </session-factory>
第二步我们在用HQL语句查询时需要打开这个配置 query.setCacheable(true);相当于打开二级查询缓存,然后去查找有没有相对应的语句,如果没找到则会去打印sql语句并去查找数据库,最后将这条语句存入缓存。
@Test//二级缓存中的查询缓存缓存(我们需要单独在hibernate配置文件中开启查询缓存)
public void fun01(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Query query =session.createQuery("from Customer");
//使用二级缓存(查询)缓存
//查询时,会先从二级缓存中取结果
//如果取不到结果就会执行语句,然后将结果放入二级查询缓存中
//打开二级缓存(查询)
query.setCacheable(true);
List<Customer> list=query.list(); session.clear();
Query query2 =session.createQuery("from Customer");
//打开二级缓存(查询)
query2.setCacheable(true);
List<Customer> list2=query2.list();
//可以看见控制台里只打印一条SQL语句说明是去找的二级缓存 //----------------------------------------
transaction.commit();
session.close(); }
测试查询缓存代码
注意查询缓存也要依赖于类级别缓存,所以必须有相应配置类缓存。不然就会一直去查询数据库,失去了缓存的价值测试代码如下:
@Test//二级缓存中的查询缓存缓存(我们也需要依赖类缓存中的实体当我们删除了类缓存的配置后)
public void fun02(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Query query =session.createQuery("from Customer");
//使用二级缓存(查询)缓存
//查询时,会先从二级缓存中取结果
//如果取不到结果就会执行语句,然后将结果放入二级查询缓存中
//打开二级缓存(查询)
query.setCacheable(true);
List<Customer> list=query.list(); session.clear();
Query query2 =session.createQuery("from Customer");
//打开二级缓存(查询)
query2.setCacheable(true);
List<Customer> list2=query2.list();
//可以看见控制台里只打印两条SQL语句因为你删除了对应的类缓存的配置
//由此我们可以知道只有类缓存里才是存放实体的和集合缓存类似查询缓存也是存放的结果ID然后去类缓存里去找 //----------------------------------------
transaction.commit();
session.close(); }
删除了类缓存的配置后
那么我们思考,我们知道查询缓存里缓存了查询语句那么它到底存放的是怎么判断HQL是不是同一条语句的?
@Test//二级缓存中的查询缓存缓存(我们知道查询缓存里缓存了查询语句那么它到底存放的是怎么判断HQL是不是同一条语句的)
public void fun03(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Query query =session.createQuery("from Customer");
//使用二级缓存(查询)缓存
//查询时,会先从二级缓存中取结果
//如果取不到结果就会执行语句,然后将结果放入二级查询缓存中
//打开二级缓存(查询)
query.setCacheable(true);
List<Customer> list=query.list(); session.clear();
Query query2 =session.createQuery("select c from Customer as c");
//打开二级缓存(查询)
query2.setCacheable(true);
List<Customer> list2=query2.list();
//可以看见控制台里只打印一条SQL语句但是我两条HQL语句是不一样
//这是因为HQL语句最后还是要转换为SQL语句所以只要判断最后的sql语句是否一样即可
//由此我们可以知道只有类缓存里才是存放实体的和集合缓存类似查询缓存也是存放的结果ID然后去类缓存里去找 //----------------------------------------
transaction.commit();
session.close(); }
怎么判断HQL是不是同一条语句的
可以看见控制台里只打印一条SQL语句但是我两条HQL语句是不一样
这是因为HQL语句最后还是要转换为SQL语句所以只要判断最后的sql语句是否一样即可
由此我们可以知道只有类缓存里才是存放实体的和集合缓存类似查询缓存也是存放的结果ID然后去类缓存里去找

④更新时间戳缓存

在时间戳缓存区里面存放的是时间,在上面配置的基础上无需再在hibernate配置文件里面配置。如上图代码中当执行了查询语句时会存放一个时间点,再当执行修改的操作时就会再次记录一个时间点,执行第三个查询语句时会比较两个时间,缓存时间已经过时,重新查询数据库。否则不进行修改的话时间点不会被记录的。
演示没有进行修改语句时,没有执行修改操作则不会再次记录新的时间点则会直接去类级别缓存找对应数据
@Test//二级缓存中的时间戳缓存(会比较修改数据库操作前后的时间比对)
public void fun01(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Customer customer =(Customer) session.get(Customer.class, 1);
System.out.println(customer);
session.clear();
Customer customer2 =(Customer) session.get(Customer.class, 1);
System.out.println(customer2);
//发现控制台只会答应一个get()方法的两条sql语句
//----------------------------------------
transaction.commit();
session.close(); }
当没有执行修改操作时
演示进行了修改操作后
发现控制台会打印四条sql语句前两句是第一个查询语句的后两个是第二个查询语句的
因为进行了修改操作又记录了一个新的时间点,当再次调用查询语句时它会比对一下时间发现时间过期后再次去查找数据库而不会去找类级别缓存。
@Test//二级缓存中的时间戳缓存(会比较修改数据库操作前后的时间比对)
public void fun02(){
Session session=HibernateUtils.openSession();
Transaction transaction=session.beginTransaction();
//-------------------------------------------------
Customer customer =(Customer) session.get(Customer.class, 1);
System.out.println(customer);
Query query =session.createQuery("update Customer set name=:name where id=:id");
query.setString("name", "小刘刘");
query.setInteger("id", 1);
query.executeUpdate();//修改的方法
session.clear();
Customer customer2 =(Customer) session.get(Customer.class, 1);
System.out.println(customer2);
//发现控制台会打印四条sql语句前两句是第一个查询语句的后两个是第二个查询语句的
//因为进行了修改操作又记录了一个新的时间点,当再次调用查询语句时它会比对一下时间发现时间过期后再次去查找数据库而不会去找类级别缓存
//----------------------------------------
transaction.commit();
session.close();
}
当执行了修改操作后
day04_1hibernate的更多相关文章
随机推荐
- 到2029年MRAM收入将增长170倍
一份新市场报告预计,从2018年到2029年,独立MRAM和STT-MRAM的收入将增长170倍,达到近40亿美元的收入.下一代内存技术的增长将主要由取代效率较低的内存技术(例如NOR闪存和SRAM) ...
- opencv中的图像矩(空间矩,中心矩,归一化中心矩,Hu矩)
严格来讲矩是概率与统计中的一个概念,是随机变量的一种数字特征.设 x 为随机变量,C为常数,则量E[(x−c)^k]称为X关于C点的k阶矩.比较重要的两种情况如下: 1.c=0,这时a_k=E(X^k ...
- DolphinScheduler源码分析
DolphinScheduler源码分析 本博客是基于1.2.0版本进行分析,与最新版本的实现有一些出入,还请读者辩证的看待本源码分析.具体细节可能描述的不是很准确,仅供参考 源码版本 1.2.0 技 ...
- 硬件知识整理part3--电阻在单片机系统中的应用
邦有道,如矢:邦无道,如矢. --孔子 电阻在电路中主要功能是限流和分压等等.在单片机系统中自然也是. 电阻作为限流应该是最常用的应用之一,对于单片机外围设计来说,电阻的应用非常重要,在很多时候,我 ...
- C#设计模式学习笔记:(3)抽象工厂模式
本笔记摘抄自:https://www.cnblogs.com/PatrickLiu/p/7596897.html,记录一下学习过程以备后续查用. 一.引言 接上一篇C#设计模式学习笔记:简单工厂模式( ...
- opencv —— split、merge 通道的分离与合并
对于三通道或四通道图像,有时要对某一通道的像素值进行修改或展示,这就需要进行通道分离操作.修改后,若要进行结果展示,就需要重新将各通道合并. 通道分离:split 函数 void split (Inp ...
- Wannafly Winter Camp 2020 Day 6C 酒馆战棋 - 贪心
你方有 \(n\) 个人,攻击力和血量都是 \(1\).对方有 \(a\) 个普通人, \(b\) 个只有盾的,\(c\) 个只有嘲讽的,\(d\) 个有盾又有嘲讽的,他们的攻击力和血量都是无穷大.有 ...
- Navicat Premium15安装与激活(破解)
Navicat premium是一款数据库管理工具,是一个可多重连线资料库的管理工具,它可以让你以单一程式同时连线到 MySQL.SQLite.Oracle 及 PostgreSQL 资料库,让管理不 ...
- 使用SSM 或者 springboot +mybatis时,对数据库的认证信息(用户名,密码)进行加密。
通常情况下,为了提高安全性,我们需要对数据库的认证信息进行加密操作,然后在启动项目的时候,会自动解密来核对信息是否正确.下面介绍在SSM和springboot项目中分别是怎样实现的. 无论是使用SSM ...
- nvm,nrm和yarn
nvm Node Version Management nvm list 查看所有已安装的 node 版本 nvm install 版本号 安装指定版本的 node nvm use 版本号 切换到指定 ...