WebGPU学习(十一):学习两个优化:“reuse render command buffer”和“dynamic uniform buffer offset”
大家好,本文介绍了“reuse render command buffer”和“dynamic uniform buffer offset”这两个优化,以及Chrome->webgpu-samplers->animometer示例对它们进行的benchmark性能测试。
上一篇博文:
WebGPU学习(十):介绍“GPU实现粒子效果”
学习优化:reuse render command buffer
提出问题
每一帧经过下面的步骤进行绘制:
- 创建一个command buffer
- 开始一个render pass
- 设置多个render command到command buffer中
- 结束该render pass
相关代码如下:
return function frame() {
...
const commandEncoder = device.createCommandEncoder();
...
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
passEncoder.setPipeline(pipeline);
passEncoder.setVertexBuffer(0, verticesBuffer);
passEncoder.setBindGroup(0, uniformBindGroup1);
passEncoder.draw(36, 1, 0, 0);
passEncoder.endPass();
...
}
我们可以发现,一般来说,每帧创建的command buffer设置的command是一样的,因此这造成了重复记录的开销。开销具体包括两个方面:
- js binding的开销
如转换descriptor object(如转换创建render pipeline时传入的参数:GPURenderPipelineDescriptor)和字符串、处理边界、检验数据的合法性等开销 - 创建render command的开销和设置render command到command buffer的开销
优化方案
WebGPU提供了GPURenderBundle,只需设置一次render command到render bundle,然后每帧执行该bundle,从而实现了command buffer的复用。
WebGPU还支持创建多个bundle,从而可以设置不同的render command到对应的render bundle中
案例代码
对案例代码的说明:
1.发起两个drawcall,对应两个bind group。
这里给出原始的案例代码和优化后的案例代码,供读者参考:
- 原始的案例代码:不使用bundle
代码如下:
return function frame() {
...
const commandEncoder = device.createCommandEncoder();
...
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
passEncoder.setPipeline(pipeline);
passEncoder.setVertexBuffer(0, verticesBuffer);
passEncoder.setBindGroup(0, uniformBindGroup1);
passEncoder.draw(36, 1, 0, 0);
passEncoder.setBindGroup(0, uniformBindGroup2);
passEncoder.draw(36, 1, 0, 0);
passEncoder.endPass();
...
}
- 优化后的案例代码:创建一个bundle
代码如下:
function recordRenderPass(passEncoder) {
passEncoder.setPipeline(pipeline);
passEncoder.setVertexBuffer(0, verticesBuffer);
passEncoder.setBindGroup(0, uniformBindGroup1);
passEncoder.draw(36, 1, 0, 0);
passEncoder.setBindGroup(0, uniformBindGroup2);
passEncoder.draw(36, 1, 0, 0);
}
const renderBundleEncoder = device.createRenderBundleEncoder({
colorFormats: [swapChainFormat],
});
recordRenderPass(renderBundleEncoder);
const renderBundle = renderBundleEncoder.finish();
return function frame(timestamp) {
...
const commandEncoder = device.createCommandEncoder();
...
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
passEncoder.executeBundles([renderBundle]);
passEncoder.endPass();
...
}
- 优化后的案例代码:创建两个bundle
代码如下:
function recordRenderPass1(passEncoder) {
passEncoder.setPipeline(pipeline);
passEncoder.setVertexBuffer(0, verticesBuffer);
passEncoder.setBindGroup(0, uniformBindGroup1);
passEncoder.draw(36, 1, 0, 0);
}
function recordRenderPass2(passEncoder) {
passEncoder.setPipeline(pipeline);
passEncoder.setVertexBuffer(0, verticesBuffer);
passEncoder.setBindGroup(0, uniformBindGroup2);
passEncoder.draw(36, 1, 0, 0);
}
const renderBundleEncoder1 = device.createRenderBundleEncoder({
colorFormats: [swapChainFormat],
});
recordRenderPass1(renderBundleEncoder1);
const renderBundle1 = renderBundleEncoder1.finish();
const renderBundleEncoder2 = device.createRenderBundleEncoder({
colorFormats: [swapChainFormat],
});
recordRenderPass2(renderBundleEncoder2);
const renderBundle2 = renderBundleEncoder2.finish();
return function frame(timestamp) {
...
const commandEncoder = device.createCommandEncoder();
...
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
passEncoder.executeBundles([renderBundle1, renderBundle2]);
passEncoder.endPass();
...
}
}
进一步分析
我们再来看下bundle和render pass相关的定义:
interface GPUDevice : EventTarget {
...
GPURenderBundleEncoder createRenderBundleEncoder(GPURenderBundleEncoderDescriptor descriptor);
...
}
dictionary GPURenderBundleEncoderDescriptor : GPUObjectDescriptorBase {
required sequence<GPUTextureFormat> colorFormats;
GPUTextureFormat depthStencilFormat;
unsigned long sampleCount = 1;
};
...
interface GPUCommandEncoder {
...
GPURenderPassEncoder beginRenderPass(GPURenderPassDescriptor descriptor);
...
}
...
dictionary GPURenderPassDescriptor : GPUObjectDescriptorBase {
required sequence<GPURenderPassColorAttachmentDescriptor> colorAttachments;
GPURenderPassDepthStencilAttachmentDescriptor depthStencilAttachment;
};
注意:创建bundle时,需要指定与所属render pass相同的color attachments、depthAndStencil attachment的format。
参考资料
Encoder results reuse
Add GPURenderBundle
How do people reuse command buffers?(要翻墙)
学习优化:dynamic uniform buffer offset
提出问题
在大多数应用中,每个drawcall需要不同的uniform变量,对应不同的uniform buffer。而uniform buffer被设置在bind group中,这意味着需要在每一帧中为每个drawcall创建并设置一个bind group。
创建bind group比drawcall的开销更大。通过在“Proposal: Dynamic uniform and storage buffer offsets”中进行的性能测试,我们知道现代图形API创建bind group的个数是有限的(而WebGPU是基于现代图形API而实现的,因此它在WebGPU中也是有限的):
This means, in a single frame, the Metal devices can create 285 bind groups, the D3D12 devices can create 7270 bind groups, and the Vulkan devices can create 18561 bind groups.
优化方案
- 我们可以一次性创建所有的bind group作为cache,然后在每一帧drawcall时只需设置对应的bind group,从而省去了drawcall时创建bind group的开销。
- 使用dynamic uniform buffer
除此之外,因为WebGPU支持“dynamic uniform buffer offset”,所以我们也可以使用下面的方法来优化:
只创建一个bind group,将其设置为dynamic offset;
每一帧drawcall时用对应的offset来设置同一个bind group。
第二种优化与第一种优化相比,更简单,只需创建一个bind group,不需要维护cache。
根据Proposal: Dynamic uniform and storage buffer offsets:
I believe we said:
We need at least one of the two for the MVP
Having both causes more complication because they will fight for root table space so we might have to introduce a combined limit for pushConstantSize + N * DynamicBufferCount.
WebGPU的MVP版本应该不会支持dynamic storage buffer offset,也就是说设置为dynamic offset的bind group只能设置一个或多个uniform buffer,不能设置storage buffer。
案例代码
对案例代码的说明:
1.每个bind group都设置同一个uniform buffer,只是它的offset不同
uniform buffer包含的uniform变量为:
float scale;
float offsetX;
float offsetY;
float scalar;
float scalarOffset;
2.一共有100个gameObject,分别对应100个draw call和uniform变量的100份数据(在uniformBufferData中)
3.在使用第二种优化的案例代码中,每个drawcall对应的bind group->uniform buffer的offset需要为256的倍数
这里给出使用第一种优化的案例代码和使用第二种优化的案例代码,供读者参考:
- 使用第一种优化的案例代码
代码如下:
const bindGroupLayout = device.createBindGroupLayout({
bindings: [
{ binding: 0, visibility: GPUShaderStage.VERTEX, type: "uniform-buffer" },
],
});
const pipelineLayout = device.createPipelineLayout({ bindGroupLayouts: [bindGroupLayout] });
const pipeline = device.createRenderPipeline({
layout: pipelineLayout,
...
});
const gameObjects = 100;
const uniformBytes = 5 * Float32Array.BYTES_PER_ELEMENT;
const alignedUniformBytes = Math.ceil(uniformBytes / 256) * 256;
const alignedUniformFloats = alignedUniformBytes / Float32Array.BYTES_PER_ELEMENT;
const uniformBuffer = device.createBuffer({
size: gameObjects * alignedUniformBytes + Float32Array.BYTES_PER_ELEMENT,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.UNIFORM
});
const uniformBufferData = new Float32Array(gameObjects * alignedUniformFloats);
//bind group的cache数组
const bindGroups = new Array(gameObjects);
function setUniformBufferData(i) {
uniformBufferData[alignedUniformFloats * i + 0] = Math.random() * 0.2 + 0.2; // scale
uniformBufferData[alignedUniformFloats * i + 1] = 0.9 * 2 * (Math.random() - 0.5); // offsetX
uniformBufferData[alignedUniformFloats * i + 2] = 0.9 * 2 * (Math.random() - 0.5); // offsetY
uniformBufferData[alignedUniformFloats * i + 3] = Math.random() * 1.5 + 0.5; // scalar
uniformBufferData[alignedUniformFloats * i + 4] = Math.random() * 10; // scalarOffset
}
for (let i = 0; i < gameObjects; ++i) {
setUniformBufferData(i);
bindGroups[i] = device.createBindGroup({
layout: bindGroupLayout,
bindings: [{
binding: 0,
resource: {
buffer: uniformBuffer,
offset: i * alignedUniformBytes,
size: 5 * Float32Array.BYTES_PER_ELEMENT,
}
}]
});
}
uniformBuffer.setSubData(0, uniformBufferData);
return function frame() {
...
const commandEncoder = device.createCommandEncoder();
...
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
passEncoder.setPipeline(pipeline);
passEncoder.setVertexBuffer(0, verticesBuffer);
for (let i = 0; i < gameObjects; ++i) {
passEncoder.setBindGroup(0, bindGroups[i]);
passEncoder.draw(3, 1, 0, 0);
}
passEncoder.endPass();
...
}
- 使用第二种优化的案例代码
代码如下:
//设置hasDynamicOffset为true
const dynamicBindGroupLayout = device.createBindGroupLayout({
bindings: [
{ binding: 0, visibility: GPUShaderStage.VERTEX, type: "uniform-buffer", hasDynamicOffset: true },
],
});
const dynamicBindGroup = device.createBindGroup({
layout: dynamicBindGroupLayout,
bindings: [{
binding: 0,
resource: {
buffer: uniformBuffer,
offset: 0,
size: 5 * Float32Array.BYTES_PER_ELEMENT,
},
}],
});
const dynamicPipelineLayout = device.createPipelineLayout({ bindGroupLayouts: [dynamicBindGroupLayout] });
const dynamicPipeline = device.createRenderPipeline({
layout: dynamicPipelineLayout,
...
});
//定义gameObjects等代码与使用第一种优化的案例代码相同,故省略
...
for (let i = 0; i < gameObjects; ++i) {
//setUniformBufferData函数与使用第一种优化的案例代码相同
setUniformBufferData(i);
}
const dynamicBindGroup = device.createBindGroup({
layout: dynamicBindGroupLayout,
bindings: [{
binding: 0,
resource: {
buffer: uniformBuffer,
offset: 0,
size: 5 * Float32Array.BYTES_PER_ELEMENT,
},
}],
});
uniformBuffer.setSubData(0, uniformBufferData);
const dynamicOffsets = [0];
return function frame() {
...
const commandEncoder = device.createCommandEncoder();
...
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
passEncoder.setPipeline(pipeline);
passEncoder.setVertexBuffer(0, verticesBuffer);
for (let i = 0; i < gameObjects; ++i) {
//这里进行了小优化:之所以要预先创建dynamicOffsets数组,然后在这里设置它的元素,而不直接用“passEncoder.setBindGroup(0, dynamicBindGroup, [i * alignedUniformBytes]);”,是因为这样可以省去“创建数组:[i * alignedUniformBytes]”的开销
dynamicOffsets[0] = i * alignedUniformBytes;
passEncoder.setBindGroup(0, dynamicBindGroup, dynamicOffsets);
passEncoder.draw(3, 1, 0, 0);
}
passEncoder.endPass();
...
}
参考资料
Proposal: Dynamic uniform and storage buffer offsets
性能测试
animometer示例对这两个优化进行了benchmark测试。
(需要说明的是,该示例的“size: 6 * Float32Array.BYTES_PER_ELEMENT”应该被改为“size: 5 * Float32Array.BYTES_PER_ELEMENT”)
该示例的运行截图如下所示:
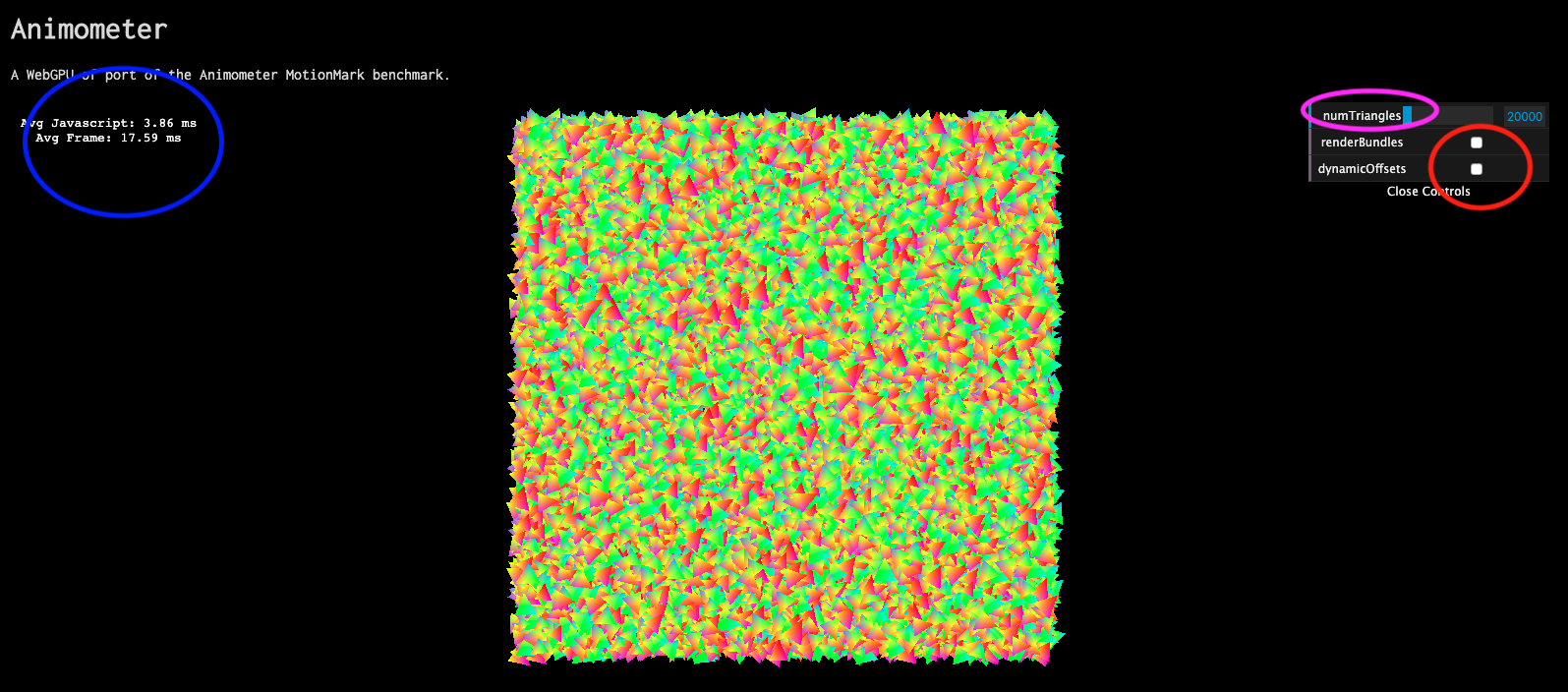
在右侧的红圈内选中按钮可启用对应的优化;
右上角的紫圈可设置绘制的三角形个数;
在左上角的蓝圈内,第一行显示每一帧在CPU端所用时间,主要包括render pass的js binding所用的时间;第二行显示每一帧总时间,它等于CPU端+GPU端的所用时间。
测试数据
在我的电脑(Mac Pro 2014,MacOS Catalina10.15.1,Chrome Canary 80.0.3977.4)上绘制4万个三角形的测试结果:
- 只使用bundle与没用任何优化相比
大幅降低了js binding所用时间,由14ms变为0.2ms;
每一帧总时间只降低了20%。
- 同时使用bundle与offset与只使用bundle相比
js binding所用时间和每一帧总时间几乎没有变化
- 只使用offset与没用任何优化相比
js binding所用时间大幅增加了60%;
每一帧总时间只稍微增加了10%。
结论
使用offset优化,虽然增加了CPU端开销,但也降低了GPU端开销,从而使每一帧总时间增加得很少。而且它使代码更为简洁(只创建一个bind group),可能也减少了内存占用(我没有进行测试,仅为推测),所以推荐使用。
使用bundle优化,虽然大幅降低了CPU端开销,但也增加了GPU端开销。不过考虑到每一帧总时间还是降低了20%,而且有被浏览器进一步优化的空间(参考Encoder results reuse),所以推荐使用。
参考资料
WebGPU学习(十一):学习两个优化:“reuse render command buffer”和“dynamic uniform buffer offset”的更多相关文章
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
- 【学习笔记】动态规划—斜率优化DP(超详细)
[学习笔记]动态规划-斜率优化DP(超详细) [前言] 第一次写这么长的文章. 写完后感觉对斜优的理解又加深了一些. 斜优通常与决策单调性同时出现.可以说决策单调性是斜率优化的前提. 斜率优化 \(D ...
- 「学习笔记」FFT 之优化——NTT
目录 「学习笔记」FFT 之优化--NTT 前言 引入 快速数论变换--NTT 一些引申问题及解决方法 三模数 NTT 拆系数 FFT (MTT) 「学习笔记」FFT 之优化--NTT 前言 \(NT ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
- js 正则学习小记之匹配字符串优化篇
原文:js 正则学习小记之匹配字符串优化篇 昨天在<js 正则学习小记之匹配字符串>谈到 个字符,除了第一个 个,只有 个转义( 个字符),所以 次,只有 次成功.这 次匹配失败,需要回溯 ...
- Deep Learning(深度学习)学习笔记整理系列之(五)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(八)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(七)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(六)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
随机推荐
- iOS7之后JavaScript与Objective-C之间的通信
http://www.cocoachina.com/ios/20150906/13320.html 最近公司用Ping++集成了第三方支付,并且微信端也集成了这个功能,而微信付款时需要调用原生的支付宝 ...
- ELK练习
1.ELK练习 PUT s3/_doc/ { "mappings" : { "doc" : { "properties" : { " ...
- 【Objective-C】-空指针和野指针
一.什么是空指针和野指针 1.空指针 1> 没有存储任何内存地址的指针就称为空指针(NULL指针) 2> 空指针就是被赋值为0的指针,在没有被具体初始化之前,其值为0. 下面两个都是空指针 ...
- Java练习 SDUT-1194_余弦
C语言实验--余弦 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 输入n的值,计算cos(x). Input 输入数据 ...
- 1、Ubuntu 16.04 安装.net core
Register the Microsoft key register the product repository Install required dependencies 参考网址:https: ...
- angular安装应用
首先你要有node 和npm 全局安装angular npm install -g @angular/cli 安装一个angular项目 ng new 项目名称 cd进入新建的项目 跑页 ...
- protobuf DNK下的编译
protobuffer 编译配置 mkdir -p ./cmake/build cd ./cmake/build cmake \ -Dprotobuf_BUILD_SHARED_LIBS=OFF \ ...
- LRJ-Example-06-01-Uva210
#define _CRT_SECURE_NO_WARNINGS #include <cstdio> #include <cstdlib> #include <cstrin ...
- 一个div居于另一个div底部
一个div如何与另一个div底部对齐,方法有很多,比如使用绝对定位 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional/ ...
- Project Euler Problem 5-Smallest multiple
对每个数字分解素因子,最后对每个素因子去其最大的指数,然后把不同素因子的最大指数次幂相乘,得到的就是最小公倍数 python不熟练,代码比较挫 mp = {} def process(n): i = ...