Embedding Layer
在深度学习实验中经常会遇Eembedding层,然而网络上的介绍可谓是相当含糊。比如 Keras中文文档中对嵌入层 Embedding的介绍除了一句 “嵌入层将正整数(下标)转换为具有固定大小的向量”之外就不愿做过多的解释。那么我们为什么要使用嵌入层 Embedding呢? 主要有这两大原因:
1、使用One-hot 方法编码的向量会很高维也很稀疏。假设我们在做自然语言处理(NLP)中遇到了一个包含2000个词的字典,当时用One-hot编码时,每一个词会被一个包含2000个整数的向量来表示,其中1999个数字是0,要是我的字典再大一点的话这种方法的计算效率岂不是大打折扣?
2、训练神经网络的过程中,每个嵌入的向量都会得到更新。如果你看到了博客上面的图片你就会发现在多维空间中词与词之间有多少相似性,这使我们能可视化的了解词语之间的关系,不仅仅是词语,任何能通过嵌入层 Embedding 转换成向量的内容都可以这样做。
Eg 1:
对于句子“deep learning is very deep”:
使用嵌入层embedding 的第一步是通过索引对该句子进行编码,这里我们给每一个不同的句子分配一个索引,上面的句子就会变成这样:
"1 2 3 4 1"
接下来会创建嵌入矩阵,我们要决定每一个索引需要分配多少个‘潜在因子’,这大体上意味着我们想要多长的向量,通常使用的情况是长度分配为32和50。在这篇博客中,为了保持文章可读性这里为每个索引指定6个潜在因子。这样,我们就可以使用嵌入矩阵来而不是庞大的one-hot编码向量来保持每个向量更小。简而言之,嵌入层embedding在这里做的就是把单词“deep”用向量[.32, .02, .48, .21, .56, .15]来表达。然而并不是每一个单词都会被一个向量来代替,而是被替换为用于查找嵌入矩阵中向量的索引。
eg 2:
假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它降到100W X 20,瞬间量级降了。。。10W/20=5000倍!!!
这就是嵌入层的一个作用——降维。
然后中间那个10W X 20的矩阵,可以理解为查询表,也可以理解为映射表,也可以理解为过度表;
参考链接:https://blog.csdn.net/weixin_42078618/article/details/82999906
https://blog.csdn.net/u010412858/article/details/77848878
PS: pixel wise metric learning
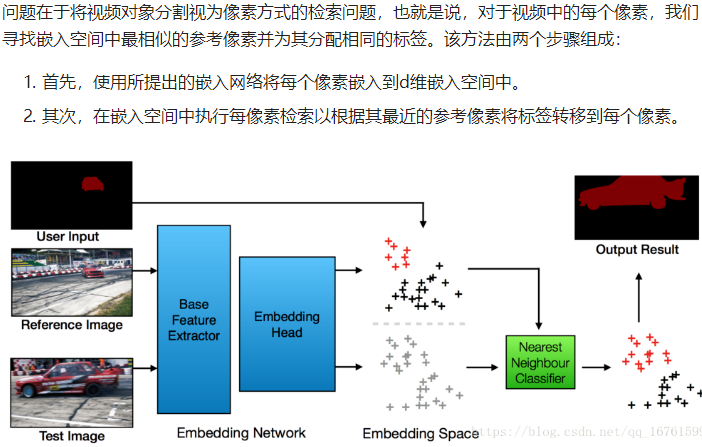
嵌入模型:在所提出的模型f中,其中每个像素x j,i被表示为d维嵌入向量ej,i = f(xj,i)。理想地,属于相同对象的像素在嵌入空间中彼此靠近,并且属于不同对象的像素彼此远离。
Embedding Layer的更多相关文章
- NLP 中的embedding layer
https://blog.csdn.net/chuchus/article/details/78386059 词汇是语料库的基本元素, 所以, 使用embedding layer来学习词嵌入, 将一个 ...
- Word Embedding/RNN/LSTM
Word Embedding Word Embedding是一种词的向量表示,比如,对于这样的"A B A C B F G"的一个序列,也许我们最后能得到:A对应的向量为[0.1 ...
- ConceptVector: Text Visual Analytics via Interactive Lexicon Building using Word Embedding
论文简介 本文是对词嵌入的一种应用,用户可以根据自己的需要创建concept,系统根据用户提供的seed word推荐其他词汇,以帮助用户更高的构建自己的concept.同时用户可以利用自己创建的 ...
- 神经网络中embedding层作用——本质就是word2vec,数据降维,同时可以很方便计算同义词(各个word之间的距离),底层实现是2-gram(词频)+神经网络
Embedding tflearn.layers.embedding_ops.embedding (incoming, input_dim, output_dim, validate_indices= ...
- (转) How to Train a GAN? Tips and tricks to make GANs work
How to Train a GAN? Tips and tricks to make GANs work 转自:https://github.com/soumith/ganhacks While r ...
- RNN 入门教程 Part 4 – 实现 RNN-LSTM 和 GRU 模型
转载 - Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano ...
- How much training data do you need?
How much training data do you need? //@樵夫上校: 0. 经验上,10X规则(训练数据是模型参数量的10倍)适用与大多数模型,包括shallow networ ...
- 【IOS笔记】Views
Views Because view objects are the main way your application interacts with the user, they have many ...
- (转) Written Memories: Understanding, Deriving and Extending the LSTM
R2RT Written Memories: Understanding, Deriving and Extending the LSTM Tue 26 July 2016 When I was ...
随机推荐
- 项目前端 - vue配置 | axios配置 | cookies配置 | element-ui配置 | bootstrap配置
vue项目创建 环境 1.傻瓜式安装node: 官网下载:https://nodejs.org/zh-cn/ 2.安装cnpm: >: npm install -g cnpm --regis ...
- zjoj1706: [usaco2007 Nov]relays 奶牛接力跑
矩阵乘法(快速幂) 为说明方便,这里让\(k\)为点数,\(n\)为路径长度. 先将点都离散化,这样最后的点只有\(2k\)个. 先考虑一种暴力,每次用\(O(k^3)\)的复杂度来暴力更新,设当前长 ...
- ps -p {pid} -o etime获取进程运行时间是如何计算出来的?
ps -p 986 -o etime可以获取进程986的执行时间,不论系统时间有没有发生改变,它都可以返回正确的结果: -bash-4.2$ ps -p 986 -o etime ELAPSED 13 ...
- MAC OS 10.15 挂载ntfs文件系统并设置自动挂载RW模式.
解决方案 花钱的,省心的 https://www.paragon-software.com/home/ntfs-mac/ 免费的 开源的 https://github.com/osxfuse/osxf ...
- CStatic 控件设置文本,不能重回问题
CStatic m_page_text_; m_page_text_.SetWindowText(str); CRect rt; m_page_text_.GetWindowRect(&rt) ...
- phpstorm 2019.1 修改浏览器
如图,修改如下浏览器的位置,由于我安装了虚拟机,导致每次点击谷歌浏览器后,都是打开的虚拟机里面的谷歌浏览器,需要重新设置浏览器的位置 打开设置 打开浏览器设置界面 双击可以选择浏览器的路径,然后就可以 ...
- StarUML自动生成Java代码
下载一个starUML 链接:https://pan.baidu.com/s/1pIGNVmhtwBxMrCG9LHdkCQ 提取码:c4i6 复制这段内容后打开百度网盘手机App,操作更方便哦 添加 ...
- mnist卷积网络实现
加载MNIST数据 from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_se ...
- 康哲20191114-1 每周例行报告kz404
此作业的要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/10004 本周PSP 本周进度条 本周折线图 饼状图
- cropper手机使用实例
cropper手机使用实例 一.总结 一句话总结: 启示:还是要多个相关的实例交叉使用,相互印证,查漏补缺,可以更加高效和方便和节约时间 二.Cropper.js从前台到后台的完整实例应用 转自或参考 ...