联合CRF和字典学习的自顶向下的视觉显著性-全文解读
top-down visual saliency via joint CRF anddictionary learning
自顶向下的视觉显著性是使用目标对象的可判别表示和一个降低搜索空间的概率图来进行目标定位。一,提出了一个联合CRF和判别字典自顶向下的显著性模型。该模型建立在包含潜在变量的CRF的基础上,将稀疏编码作为潜在变量,对CRF调制的字典进行训练,同时训练具有稀疏编码的CRF,二,提出一种最大间隔方法,通过快速推理来训练模型。
Bag of word(Bow)模型高度依赖于字典和采样策略,从这两个角度出发,提出了自顶向下的显著性模型,其核心思想是利用联合学习的方法在稀疏编码的图像块上建立条件随机场。对任意的图像块,我们利用二进制变量来标记目标对象的存在与否。条件随机场的使用能使我们利用相邻图像块的连通性,以至于我们通过并入局部性文本信息来计算显著性映射,另一方面,利用稀疏编码工具,我们可以对显著性映射的特征选择性建模,这通常会导致更紧凑和更有鉴别力的表示。
利用稀疏编码作为潜在变量,学习一种由CRF调制的判别字典,以及由稀疏编码驱动的CRF。
3 问题公式化
根据一张图像,我们感兴趣的是目标对象是否出现以及目标对象出现在哪。对于一个局部的图像块,x∈Rp,我们分配一个二进制标签y,y=1表示目标对象出现,y=-1表示没有出现,我们从图像的不同位置观察得到采样得到了一组图像块 X={x1,x2,...,xm},Y={y1,y2,...,ym}是标签,代表目标对象的在图像块上的存在信息。在特定的尺度下,一个采样块xi通常携带目标对象的局部信息,因此直接从xi中推断目标对象的存在与否而不考虑块级别表示上的语义和几何上的模型性是很有挑战性的。
假设存在一个字典D∈Rp×k,其中存储最具代表性的对象部件,{d1,d2,...,dk},引进一个潜在变量的向量si,来模拟xi=Dsi的稀疏表示,(通俗的说,就是将图像块根据字典进行稀疏表示)可以通过下面公式得到(以下公式还是字典学习里面的公式)(1)
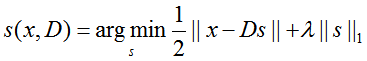
λ是控制稀疏编码的惩罚项
将所有块的潜在变量表示为S(X,D)=[s(x1,D),s(x2,D),...,s(xm,D)],潜在变量就是字典里面的稀疏编码,稀疏潜在变量是字典的函数,符号记为
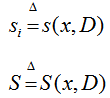
通过稀疏编码,字典中包含的视觉信息通过S(X,D)传递到潜在变量中,比图像块X更具有信息量。如果一个局部块显示了目标对象的支持,附近的块很可能也会显示相同的支持。在样本块上根据他们的空间邻近性,我们建立一个四连通图G<V,E>,V表示结点,E表示边。在稀疏潜在变量S(X,D)的条件下,假设标签Y在图G上具有马尔可夫性质(在t0所处的状态为已知的条件下,过程在时刻t(t>t0)的状态的条件分布与过程在时刻t0之前所处的状态无关),通过下面的等式提出了一个新颖的模型。(2)
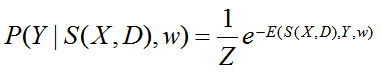
Z是分配函数,E(S(X,D),Y,w)是一个能量函数,w是CRF的权重向量。这个公式能够共同学习CRF的权重w和字典D。根据上式,可以看做有监督的字典学习,给定字典D后,可以视为稀疏编码的CRF学习。从这个模型中,我们很容易从一个特定结点的边际概率中检索到目标信息。(3)
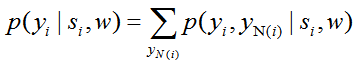
N(i)表示结点i在图G上的邻居。定义块i的显著性值u(si,w)为(4)
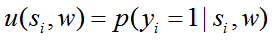
因此通过消息传递算法可以推断出显著性映射U(S,w)={u1,u2,...,um}。这种自上而下的显著性图的概率定义不仅利用了外观信息,还通过公式3中的边缘化利用了局部上下文信息。
将能量函数E(S(X,D),Y,w)分解成结点和能量项,对于每个结点,能量通过稀疏编码总的贡献量来表示, w1是一个权重向量。对于每一条边,我们只考虑与数据无关的平滑度。
w1是一个权重向量。对于每一条边,我们只考虑与数据无关的平滑度。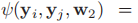
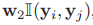 ,标量w2衡量标签平滑度的权重,
,标量w2衡量标签平滑度的权重,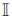 是一个指标函数,对于不同的标签都等于一个指标函数,所以能量函数具体可以表示为(5)
是一个指标函数,对于不同的标签都等于一个指标函数,所以能量函数具体可以表示为(5)
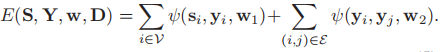
将图像块的稀疏编码作为顶点,标签与标签之间作为边。
可以看到能量函数是线性的,w=[w1:w2],非线性字典D在等式1中定义了,非线性参数对学习这个模型带来了挑战。
现在假设,我们已经学到了CRF和参数w和字典D,等式2中自上而下的显著性公式并没有涉及潜在变量的复杂性评估,不考虑潜在变量和标签推理之间进行交替的情况下,直接推导出显著性图,对于一个测试图像X={x1,x2,...,xm},计算显著性图U如下:
1,通过公式1评估稀疏潜在变量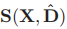
2.通过公式3,4,推断显著性图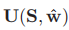
4 联合CRF和字典学习
X={X(1),X(2),...,X(N)}是训练图像的集合,Y={Y(1),Y(2),...,Y(N)}是相应的标签,我们目的是学习CRF参数w和字典D来最大化训练样本的联合可能性。(6)是目标式子
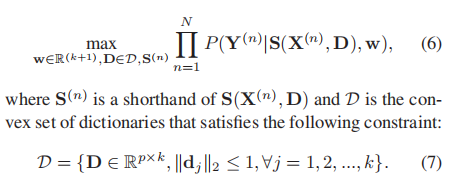
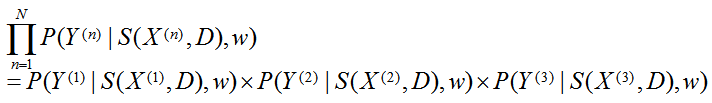
X(1)={x1,x2,..,xn},Y(1)={y1,y2,...,yn}
4.1 最大间隔方法(求w和D)
CRF学习的困难主要是评估分配函数Z,受到最大间隔CRF学习方法的启发,我们追求最优的w和D,以至于对于所有的Y≠Y(n),n=1,2,...N
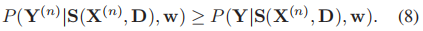
这个约束允许我们在约束两边消去分配函数Z,并用能量来表示它们
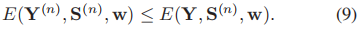
更进一步的,我们希望(9)式子中的差值越大越好,即如下表示
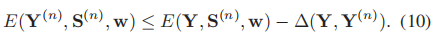
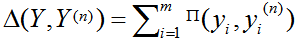
对于每一个训练样本,都有指数级别的约束,我们通过式子11来寻找最严的约束
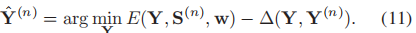 因此,我们可以通过最小化式子(12)学习权重w和字典D
因此,我们可以通过最小化式子(12)学习权重w和字典D
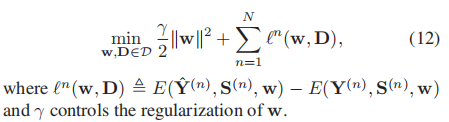
此方法与支持向量机有相似的目标函数,不同的是,潜在结构SVM参数是线性的,而此方法是字典D是非线性的。
4.2 学习算法
使用随机梯度下降算法,来优化等式12,这个思想简单且容易实现,在第t次迭代的时候随机挑选一个训练示例(X(n),Y(n)),然后进行如下操作:
1)通过式子1,用字典D(t-1)来计算稀疏潜在变量
2)通过式子11,获得最违反的标签权重
3)通过损失函数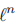 的梯度更新wt和Dt
的梯度更新wt和Dt
接下来,描述关于权重和字典计算梯度的方法。
当潜在变量S已知,能量函数E(Y,S,w)和w程线性关系。
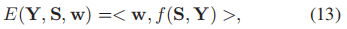
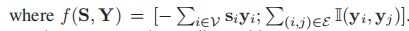 ,对损失函数对w进行求导
,对损失函数对w进行求导

字典在式子12中并没有明确定义,在式子1中隐式定义,我们利用微分链式法则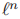 对字典D求导。
对字典D求导。
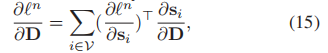
问题又来了,稀疏编码对字典D求导不好求,为克服这个困难采用的是不动点方程的显式微分,所以首先建立方程式1的显式不动点方程
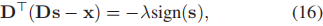
sign(s)表示以逐点的方式,s的符号,sign(0)=0
对(16)两边进行求导,得到如下:
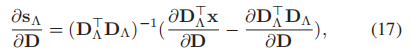
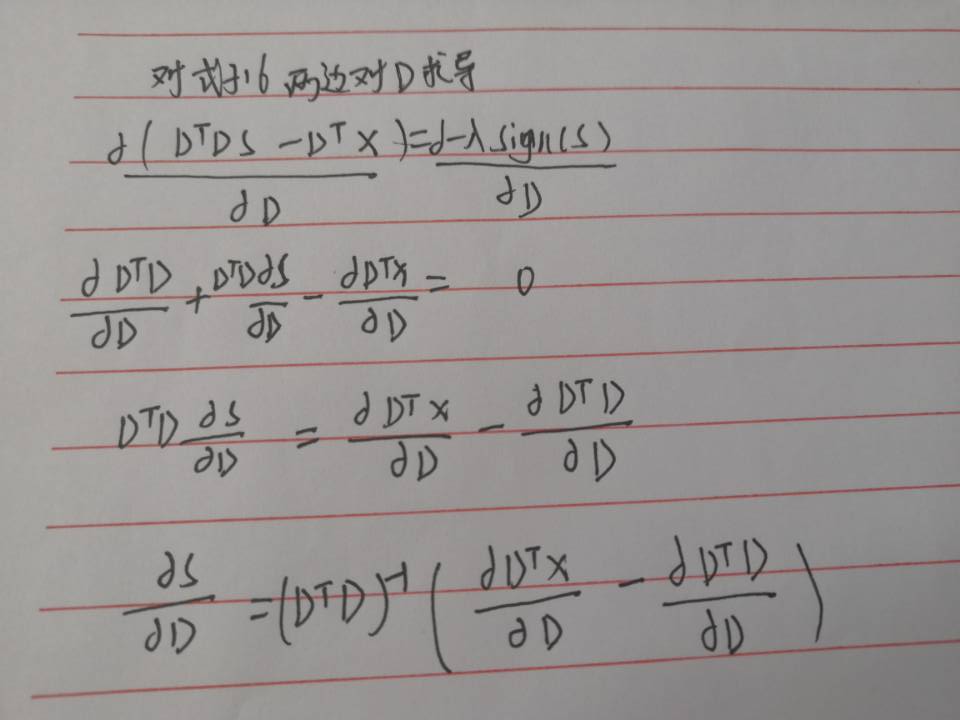
Λ表示s的非零码的索引集, 表示s的零码集,为简化方程式(15)的梯度的计算,对每一个s引进一个辅助变量z,
表示s的零码集,为简化方程式(15)的梯度的计算,对每一个s引进一个辅助变量z,
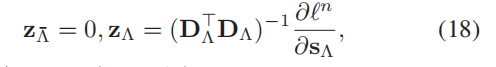
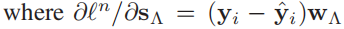 ,
,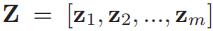 ,
,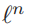 关于D的梯度可以计算为(公式怎么求出来的)
关于D的梯度可以计算为(公式怎么求出来的)
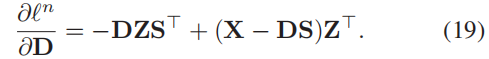
算法流程:
输入:X(训练图片),Y(对应的标签),D(0)初始化字典,w(0)初始化CRF的权重,λ,T表示迭代次数,γ,p0初始化学习率
输出:D和w
for t=1,...,T do
改变训练样本的序列(X,Y)
for n=1,...,N do
通过等式1计算潜在变量
通过方程式11解决最不符合的标签
通过方程式14更新w
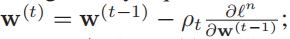
找到si的非零集合
通过方程式(18)计算辅助变量z
通过(19)更新字典D
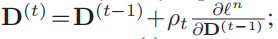
使用等式(7)将D(t)投影到D上
更新p0
end for
end for
5 实验
数据集选用Graz-02和PASCAL VOC 2007
5.1 Graz-02
Graz-02数据集包含三个类别,(汽车,自行车,人)和一个背景类,每一类有300个图像,每一张图片大小640×480,还有像素级别的前景和背景注释。任务是评估自上而下显著性映射在背景条件下定位目标对象的性能。通过滑动16个像素,对64*64的像素块进行采样,以便在27*37的网格上为每个图像收集999个图像块。对所有的实验采用相同的块采样方法。从每一个图像块中提取sift描述符来表示对象的外观。如果一个块的至少四分之一表示前景,我们标记为正,否则标记为负,因此我们从原始像素级别的注解中获得了块级别的真实值,每一类,利用其类别的150张奇数图片和额外的来自背景类的150张图像作为训练集,剩下的其类别的150张偶数图像和150张偶数背景图像作为测试集。
使用算法1训练显著性模型,需要初始化字典和CRF,从训练集里面收集所有的sift描述符,利用kmeans算法初始化字典D(0),通过稀疏编码计算潜在变量后,在稀疏编码和相应的块标签上训练线性SVM来初始化CRF的权重w1(0),对w2(0)设置为1,模型训练20次。
两个重要参数,一,可视单词(字典原子)的数目k,它控制对外观变化建模的能力,通常字典越大,效果越好,但是很难去学习,因为需要更多的训练样本,计算成本较高,在我们实验中,我们使用的字典原子为256和512,另一个参数λ控制稀疏惩罚,λ越大表示潜在变量越稀疏,选择表示一个图像块的可视单词越少,实验中的λ有两个值,0.15和0.3。初始学习率p0=0.003,权重惩罚γ=1e-5.为验证联合CRF和字典学习的有效性,建立了一个基准模型,直接利用稀疏编码和CRF,使用初始字典计算的稀疏编码作为特征来学习CRF的权值。本文提出的算法和两个最先进的算法进行了比较,在DSD算法中,首先建立一个包含256大小为64×64的滤波器的DCT(离散余弦变换)字典,然后选取100个具有最大互信息的显著特征。在SUN算法中,我们使用PCA降低了图像块的维度,然后从训练样本中学习了724个滤波器,用ICA滤波器响应作为特征,训练线性SVM计算块的显著性值。
针对所有模型,在每一类的测试样本上,计算准确率和召回率。DSD算法基于图像级统计信息选择显著特征,通常对背景图像的抑制能力有限,一般的DSD方法的召回率高,准确率低,SUN采用了强分类器,性能优于DSD方法,在不考虑局部上下文的情况下,SUN常产生噪声显著性映射。我们的模型在目标对象不同视角出现和部分遮挡时也能产生清晰的显著性映射。
图像的显著性映射具有其块网格的大小,即27×37,为了可视化定位的性能,我们将原始显著性图提升到图像大小上,以便得到像素级结果。
字典更新是如何提高模型性能的呢?在每一次循环中,记录CRF权重和字典,在测试集上进行评估,实验表明,在前几个循环中,性能有了显著的提升,10次后开始收敛。
5.2 PASCAL VOC 2007
PASCAL VOC 2007数据集包含9963个图像,20个类和一个背景类,对象分割注解可用于632张图像。评估自上而下的显著性模型,在背景和其他类别对象的情况下,定位目标图像。来自不同类别的对象有相似的部分外观,例如,自行车,公交车,摩托车都有相似的轮子结构,这种现象使得在块级水平上很难判别对象和其他对象。在此数据集上422张图像用于训练,210张用于测试。从每张图像的分割注解中创建20个对象显著性掩码。我们注意到在训练集中,与负样本相比,只有少量样本包含每一类的目标对象。为了从不均衡的数据集中学习一个模型,我们还是用正面示例的边界框注释进行训练。我们通过测量样本块是否落入目标边界框中来为这些图像创建显著性掩码。
此模型的不足
此模型部分依赖于目标对象在块级上是否包含丰富的结构化信息,以飞机为例,此模型不适用一个大型飞机在图像中占主导地位的情况,因为这些图像的局部块包含有限的相关信息,此模型成功的将小飞机定位到接近实验中使用的块大小的范围内。在规则网格上,同样大小的图像块,此模型处理尺度变化带来的信息损失的能力是有限的,我们注意到对象实例更容易通过许多类别中的全局形状来识别(eg,餐桌,瓶子),因此通过在多尺度上扩展我们的模型,或者使用尺度自适应块采样策略,对于自顶向下的视觉显著性,我们没有在模型中包含边界信息,尽管这些线索对于基于CRF的对象分割非常重要。此模型可以很容易的扩展到利用超像素或边界保持区域进行目标分割。
6 总结
本文提出了联合CRF和字典学习的自上而下的视觉显著性图,对每一个目标类,利用提出的模型在图像块的采样网格上生成显著性图。与计算每个块上的显著性值相比,我们的显著性图是通过考虑具有潜在变量的CRF模型的空间一致性来生成的,此模型通过合并上下文信息生成清晰的显著性映射,该词典规定了从不同角度和尺度表示目标外观的能力。未来工作:1.使用多尺度块扩展此模型,2,考虑边界保留区域或者超像素进行对象分割。
联合CRF和字典学习的自顶向下的视觉显著性-全文解读的更多相关文章
- Dictionary Learning(字典学习、稀疏表示以及其他)
第一部分 字典学习以及稀疏表示的概要 字典学习(Dictionary Learning)和稀疏表示(Sparse Representation)在学术界的正式称谓应该是稀疏字典学习(Sparse Di ...
- 条件随机场CRF(三) 模型学习与维特比算法解码
条件随机场CRF(一)从随机场到线性链条件随机场 条件随机场CRF(二) 前向后向算法评估标记序列概率 条件随机场CRF(三) 模型学习与维特比算法解码 在CRF系列的前两篇,我们总结了CRF的模型基 ...
- 字典学习(Dictionary Learning, KSVD)详解
注:字典学习也是一种数据降维的方法,这里我用到SVD的知识,对SVD不太理解的地方,可以看看这篇博客:<SVD(奇异值分解)小结 >. 1.字典学习思想 字典学习的思想应该源来实际生活中的 ...
- 学习人工智能的第五个月[字典学习[Dictionary Learning,DL]]
摘要: 大白话解释字典学习,分享第五个月的学习过程,人生感悟,最后是自问自答. 目录: 1.字典学习(Dictionary Learning,DL) 2.学习过程 3.自问自答 内容: 1.字典学习( ...
- 稀疏编码(sparse code)与字典学习(dictionary learning)
Dictionary Learning Tools for Matlab. 1. 简介 字典 D∈RN×K(其中 K>N),共有 k 个原子,x∈RN×1 在字典 D 下的表示为 w,则获取较为 ...
- 字典学习(Dictionary Learning)
0 - 背景 0.0 - 为什么需要字典学习? 这里引用这个博客的一段话,我觉得可以很好的解释这个问题. 回答这个问题实际上就是要回答“稀疏字典学习 ”中的字典是怎么来的.做一个比喻,句子是人类社会最 ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- swift2.0 字符串,数组,字典学习代码
swift 2.0 改变了一些地方,让swift变得更加完善,这里是一些最基本的初学者的代码,里面涉及到swift学习的最基本的字符串,数组,字典和相关的操作.好了直接看代码吧. class View ...
- 搜狗大数据总监、Polarr 联合创始人关于深度学习的分享交流 | 架构师小组交流会
架构师小组交流会是由国内知名公司技术专家参与的技术交流会,每期选择一个时下最热门的技术话题进行实践经验分享.第一期:来自沪江.滴滴.蘑菇街.扇贝架构师的 Docker 实践分享 第二期:来自滴滴.微博 ...
随机推荐
- c# 如何获取当前方法的调用堆栈
c# 调试程序时常常需要借助 call stack 查看调用堆栈,实际上通过code也可以获取: class Program { static void Main(string[] args) { T ...
- Navicat for Mysql安装及破解教程
一.Navicat for Mysql安装 下载链接:https://navicatformysql.en.softonic.com/ 点击download下载. 下载完成后双击安装 二.破解 破解工 ...
- 英语_金丝楠是紫楠(phoebeSheareri)的别名
姚黄魏紫俱凋零--红木家具今古谈(连载七) [上海木业网]楠木品种包括闽楠.细叶楠.红毛山楠.滇楠.白楠.紫楠.乌心楠.桢楠.水楠.香楠等二百余种之多,1997年的木材国家标准中就列入了八种.某些售卖 ...
- vue学习指南:第五篇(详细) - vue的 computed、methods、watch 的区别?
Computed 计算属性 1. 将函数代码块中返回的结果 赋值 给前面的方法名 2. computed 中的属性有缓存功能,只要data中的数据不发生改变,计算得到的新属 性就会被缓存下 ...
- Linux环境oracle导库步骤
1.xshell登录linux 2.切换oracle用户 su - oracle 3.创建directory仓库目录,存放数据库dmp文件 //DIRFILE_zy 表示目录名称 后面的是实际地址 c ...
- Java代码实现定时器
一 import java.util.Timer; import java.util.TimerTask; public class time { public static void main(St ...
- python_数据分析_正态分布
Kolmogorov-Smirnov 与 Shapiro-Wilk 模型正态分布检验 Spss stata R语言正态分布 install.packages("nortest") ...
- appium---app输入中文
在app自动化的过程中,都会遇到输入中文的问题,今天总结下app自动化如何输入中文 app输入中文 在启动app的时候在参数里面添加unicodeKeyboard和resetKeyboard后,运行代 ...
- paxos算法—今生
Paxos 定义2.1 票:即弱化形式的锁.它具备下面几个性质: 可重新发布:服务器可以重新发布新票,即使前面发布的票没有释放. 票可以过期:客户端用一张票来给服务器发送命令请求时,只有当这张票是最 ...
- AssetBundleMaster_Introduce_EN
This is an integrated solution for building AssetBundles and loading Assets. what it can do is about ...