数据科学:pd.DataFrame.drop()
一、功能
- 删除集合中的整行或整列;
二、格式
df.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
- labels:指示标签,表示行标或列标;
- axis = 0:默认取 0,表示删除集合的行;
- axis = 1:删除集合中的列;
- index:删除行;
- columns:删除列;
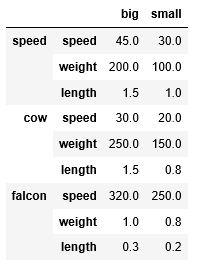
- level:针对有两级行标或列标的集合;如下图,集合有两级行标;
- level = 1:表示按第2级行删除整行;(即speed、weight、length)
- level = 0:默认取 0,表示按第1级行标删除整行;(即speed、cow、falcon,此处一次删除 3 行数据)
二、例
1)例一

- 删除行

- 删除列


2)例二
midx = pd.MultiIndex(levels=[['speed', 'cow', 'falcon'],
['speed', 'weight', 'length']],
codes=[[0, 0, 0, 1, 1, 1, 2, 2, 2],
[0, 1, 2, 0, 1, 2, 0, 1, 2]]) df = pd.DataFrame(index=midx, columns=['big', 'small'],
data=[[45, 30], [200, 100], [1.5, 1], [30, 20],
[250, 150], [1.5, 0.8], [320, 250],
[1, 0.8], [0.3,0.2]])
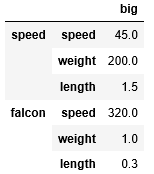
df.drop(index='cow', columns='small')
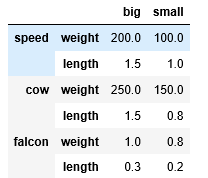
df.drop(index='speed', level=1)
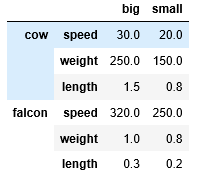
level 默认取 0
df.drop(index='speed')
数据科学:pd.DataFrame.drop()的更多相关文章
- Python 数据科学系列 の Numpy、Series 和 DataFrame介绍
本課主題 Numpy 的介绍和操作实战 Series 的介绍和操作实战 DataFrame 的介绍和操作实战 Numpy 的介绍和操作实战 numpy 是 Python 在数据计算领域里很常用的模块 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- 15种Python片段去优化你的数据科学管道
来源:15 Python Snippets to Optimize your Data Science Pipeline 翻译:RankFan 15种Python片段去优化你的数据科学管道 为什么片段 ...
- (数据科学学习手札134)pyjanitor:为pandas补充更多功能
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 pandas发展了如此多年,所包含的功能已 ...
- pandas中,dataframe 进行数据合并-pd.concat()
``# 通过数据框列向(左右)合并 a = pd.DataFrame(X_train) b = pd.DataFrame(y_train) # 合并数据框(合并前需要将数据设置成DataFrame格式 ...
- Kaggle泰坦尼克数据科学解决方案
原文地址如下: https://www.kaggle.com/startupsci/titanic-data-science-solutions --------------------------- ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- python和数据科学(Anaconda)
Python拥有着极其丰富且稳定的数据科学工具环境.遗憾的是,对不了解的人来说这个环境犹如丛林一般(cue snake joke).在这篇文章中,我会一步一步指导你怎么进入这个PyData丛林. 你可 ...
- 深入对比数据科学工具箱:Python和R之争
建议:如果只是处理(小)数据的,用R.结果更可靠,速度可以接受,上手方便,多有现成的命令.程序可以用.要自己搞个算法.处理大数据.计算量大的,用python.开发效率高,一切尽在掌握. 概述 在真实的 ...
随机推荐
- B 题解————2019.10.16
相信他说的话,但不要当真 [题目描述]有一个长度为 n 的自然数序列 a,要求将这个序列恰好分成至少 m 个连续子段. 每个子段的价值为该子段的所有数的按位异或.要使所有子段的价值按位与的结果最大,输 ...
- 【转】Web实现前后端分离,前后端解耦
一.前言 ”前后端分离“已经成为互联网项目开发的业界标杆,通过Tomcat+Ngnix(也可以中间有个Node.js),有效地进行解耦.并且前后端分离会为以后的大型分布式架构.弹性计算架构.微服务架构 ...
- 京东联盟开发(6)——推广链接解析SKUID
1.从推广方案中分析出价格及推广码 $keyword = " [京东]长虹(CHANGHONG) L3 老人手机 移动/联通2G 老年机 双卡双待 咖啡 原价:168.00元 券后价:163 ...
- 重置jenkins用户名密码
忘记用户名密码(如图)不管是忘记用户名密码还是误删jenkins目录下的users文件都可以使用下面的方式找回密码,我的版本是Jenkins 2.134 1. 进入jenkins安装目录,我的 ...
- Intellij 热部署插件 JRebel [转载]
原文:https://blog.csdn.net/weixin_42831477/article/details/82229436 Intellij热部署插件JRebel IDEA本身没有集成热部署工 ...
- 《Linux就该这么学》培训笔记_ch23_使用OpenLDAP部署目录服务
<Linux就该这么学>培训笔记_ch23_使用OpenLDAP部署目录服务 文章主要内容: 了解目录服务 目录服务实验 配置LDAP服务端 配置LDAP客户端 了解目录服务 其实目录可以 ...
- centos8 安装 docker
centos 安装docker 官方参考地址:https://docs.docker.com/install/linux/docker-ce/centos/ 里面包含包下载地址: https://d ...
- json对象与string相互转换教程
一.说明 1.1 背景说明 json对象与string相互转换,这东西想写了很多次,但总觉得网上教程比较成熟,所以之前每次都放弃了.但今天又被string转json对象折腾了半天,实在受不了,所以还是 ...
- [转帖]PostgreSQL 参数调整(性能优化)
PostgreSQL 参数调整(性能优化) https://www.cnblogs.com/VicLiu/p/11854730.html 知道一个 shared_pool 文章写的挺好的 还没仔细看 ...
- GoLang 开山篇
GoLang 开山篇 1.Golang 的学习方向 Go语言,我们可以简单的写成Golang. 2.GoLang 的应用领域 2.1 区块链的应用开发 2.2 后台的服务应用 2.3 云计算/云服务后 ...