Oracle current redo.log出现坏块后的不完全恢复案例一则
1异常出现
8月30日下午2时左右,接同事电话,说数据库异常宕机了,现在启动不了。
2初步分析
我让现场把alert.log发过来,先看看是什么问题。
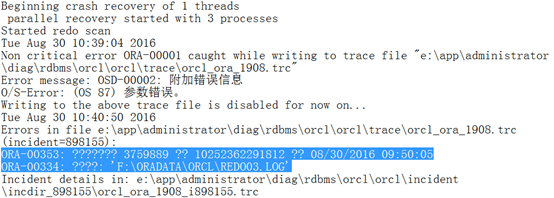
关于ORA-00353和ORA-00334,先查一查是什么错误:

根据上述信息可知,30日10点39分,在进行crash recovery时,REDO03.LOG文件的block=3759889处存在corruption block(坏块。属物理损坏,一般与介质异常与操作系统调用失败有关)。
当发现坏块后,oracle后台进程将REDO03.LOG中的所有内容DUMP到orcl\trace\orcl_ora_1908.trc文件中。分析该文件:

通过对该trace文件的分析,可以看到,crash recovery将从REDO03.LOG的cache-low rba开始恢复,一直要恢复到REDO01.LOG的on-disk rba处。而REDO03.LOG文件的corruption block 3759889(REDO文件大小为2G,REDO BLOCKSIZE=512B,因此block范围为1~4194304),正处于这个区间内,如下图所示。

此时,REDO01.LOG的状态是CURRENT,而REDO03.LOG的状态是ACTIVE,由于坏块在REDO03.LOG上。因此REDO01.LOG整个文件,以及REDO03.LOG上corrption block之后的redo entry(重做条目)不可恢复。所以,数据库只能以不完全恢复启动。
3处理过程
到了现场,以如下方式启动数据库:
1.参数文件中添加_allow_resetlogs_corruption=true
2.Startup mount;
3.recover database until cancel;
4.alter database open resetlogs;
以这种方式,可以将数据库SCN推进到corruption rba处的SCN,但此时的数据库因为丢矢了corruption rba了重做日志,所以,现在的数据库并不是一致的状态。
数据库打开了,然而没运行多久,就又自动宕机了。再次检查alert.log,发现出现了ORA-00600 [2662] 错误。

针对现场的数据库版本v11.2.0.1,在MOS上查询ORA-00600 [2662],文档ID 28929.1中有关解释,内容如下:

从文档描述可知,当curren SCN小于dependent SCN时,出现ORA-00600 [2662],它有5个参数,见上图ARGUMENTS部分。
Current SCN来自于控制文件,当前值为(2387*232)+ 275355755= 10252362291307,该值实际上代表的是corruption rba处(非完全一致,但接近)的SCN。
Dependent SCN当前值为(2387*232)+ 275361895=10252362297447, 10252362297447-10252362291307=6140,可知相差非常小(对于SCN来说,这个值的确非常小)。
另外,第5个参数[83597025],代表的是Dependent SCN从何处得到。它是一个DBA(data block address),计算该DBA的具体位置:

通过查询v$datafile,可知FILE_ID=19是一个业务相关的数据文件。
根据图6的说明,如果Current SCN与Dependent SCN非常接近时,重启几次,让Current SCN追上直至超过Dependent SCN即可。

图6
在alert.log中,可以看到,重启多次之后,current SCN逐渐追上了depentend SCN,直至数据库可以启动为止。不过,由于数据库是以不完全恢复启动的,所以启动会必须立刻将数据库DUMP出来,并在其它数据库中恢复。
4其它说明
此案例中,由于current SCN与depentend SCN相差较近,所以选择使用多次启动的方式,使current SCN逐渐追上depentend SCN的方式来启动。但如果current SCN与depentend SCN相差较远,需要用其它方式来手动推进current SCN。
1)set the following hidden parameter in init.ora
*._allow_error_simulation = TRUE
*._smu_debug_mode = 268435456
2)通过adjust_scn事件
1.set "*._allow_error_simulation = TRUE" in init.ora
2.alter system set events 'immediate trace name adjust_scn level 1';
3)设置current SCN最小起始值(1表示1*230)
Set "*._minimum_giga_scn=1" in init.ora
4)修改实例的Global Lamport SCN,在SGA中由kcsgscn变量存储
1.oradebug setmypid
2.oradebug DUMPvar SGA kcsgscn
3.ORADEBUG POKE 0x060012658 4 0xfffff
5)用BBED工具修改datafile header实现修改SCN
主要是修改datafile header kcvfh.kcvfhckp.kcvcpscn,bbed具体使用方法不展开叙述。
Oracle current redo.log出现坏块后的不完全恢复案例一则的更多相关文章
- 07 oracle 归档模式 inactive/current redo log损坏修复--以及错误ORA-00600: internal error code, arguments: [2663], [0], [9710724], [0], [9711142], [], [], [], [], [], [], []
07 oracle 归档模式 inactive/current redo log损坏修复--以及错误ORA-00600: internal error code, arguments: [2663], ...
- 07 oracle 非归档模式 inactive/active/current redo log损坏的恢复
在非归档模式下缺失Redo Log后的恢复 将之前的归档模式修改为非归档 SQL> shutdown immediate; SQL> startup mount SQL> alter ...
- 【REDO】删除REDO LOG重做日志组后需要手工删除对应的日志文件(转)
为保证重新创建的日志组成员可以成功创建,我们在删除日志组后需要手工删除对应的日志文件. 1.查看数据库当前REDO LOG日志相关信息1)查看日志组信息sys@ora10g> select * ...
- ORACLE模拟一个数据文件坏块并使用RMAN备份来恢复
1.创建一个实验用的表空间并在此表空间上创建表 create tablespace blocktest datafile '/u01/oradata/bys1/blocktest.dbf' size ...
- Oracle更改redo log的大小
因为数据仓库ETL过程中,某个mapping的执行时间超过了一个小时, select event,count(*) fromv$session_wait group by event order by ...
- Oracle更改redo log大小 or 增加redo log组
(1)redo log的大小可以影响 DBWR 和 checkpoint : (2)arger redo log files provide better performance. Undersize ...
- 12 oracle 数据库坏块--物理坏块-ORA-01578/ORA-01110
oracle 数据库坏块--物理坏块 数据坏块的类型物理坏块:通常是由于硬件损坏如磁盘异常导致.内存有问题.存储链有问题. IO有问题.文件系统有问题. Oracle本身的问题等逻辑坏块:可能都是软件 ...
- Oracle Redo Log 机制 小结(转载)
Oracle 的Redo 机制DB的一个重要机制,理解这个机制对DBA来说也是非常重要,之前的Blog里也林林散散的写了一些,前些日子看老白日记里也有说明,所以结合老白日记里的内容,对oracle 的 ...
- 13 oracle数据库坏块-逻辑坏块(模拟/修复)
13 oracle数据库坏块-逻辑坏块 逻辑数据坏块的场景1)oracle bug也可能导致逻辑坏块的产生. 特别是parallel dml. 例如:Bug 5621677 Logical corru ...
随机推荐
- kubectl kubernetes cheatsheet
from : https://cheatsheet.dennyzhang.com/cheatsheet-kubernetes-a4 PDF Link: cheatsheet-kubernetes-A4 ...
- 怎样把txt文档转换成csv文件?
其实csv就是逗号隔开的一行一行的数据, 如果每行数据中都是用逗号分隔的,直接把文件后缀txt改成csv就行了. 用python搞定: import numpy as np import pandas ...
- GPP(Group Policy Preferences)漏洞
再次之前先讲一些知识点: 密码的难题 每台Windows主机有一个内置的Administrator账户以及相关联的密码.大多数组织机构为了安全,可能都会要求更改密码,虽然这种方法的效果并不尽如人意.标 ...
- springboot使用jdbcTemplate案例
1 创建实体类 public class Student { private Integer stuid; private String stuname; public Integer getStui ...
- Uncaught SyntaxError: Unexpected token o
浏览器报Uncaught SyntaxError: Unexpected token o 这原因是你ajax获取数据的时候对数据进行错误操作,比如使用了 JSON.parse(data) 对数据进行转 ...
- According to TLD or attribute directive in tag file, attribute items does not accept any expressions
<%@ taglib uri="http://java.sun.com/jstl/core" prefix="c" %>报错 <%@ tagl ...
- Server concepts 详解
server status 是由 vm_state和task_state 计算出来的,vm_state是虚机当前的稳定状态(例如Active, Error),task_state是虚机当前的瞬间状态( ...
- 2019暑假Java学习笔记(三)
目录 面向对象 对象 构造方法 引用与对象实例 static final 封装 this 继承 super 方法重载与重写 多态 抽象类 接口 内部类 成员内部类 静态内部类 局部内部类 匿名内部类 ...
- Thinking In SE
各种编程范式的区别 并发模型 并行架构: 位级(bit-level)并行 指令级(instruction-level)并行 数据级(data)并行 数据级并行 任务级(task-level)并行 -- ...
- uniapp - 微信公众号授权登录
[缘由] 采用uniapp进行微信小程序和微信公众号双版本开发:考虑到用户唯一性,我们后端确定了以“unionid”.作为唯一标识. 有的小伙伴估计也是刚入这坑,我就简单说一下步骤流程 [摸索] ...