Hadoop综合大作业总评
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
1、把python爬取的数据传到linux
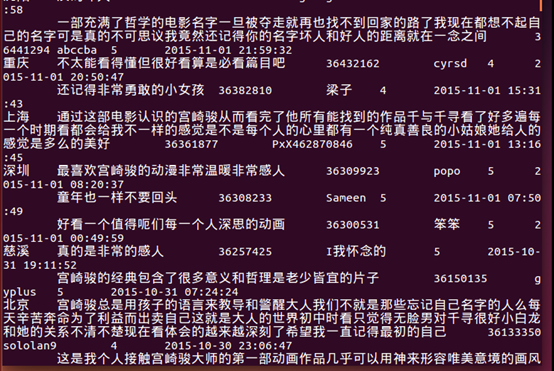
2、把数据的逗号代替为 \t转义字符
3、启动hadoop集群

4、启动hive

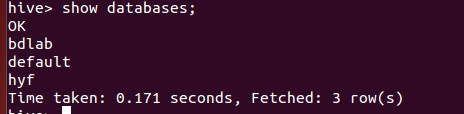
5、创建数据库

6、创建表并把hdfs的数据导入表中

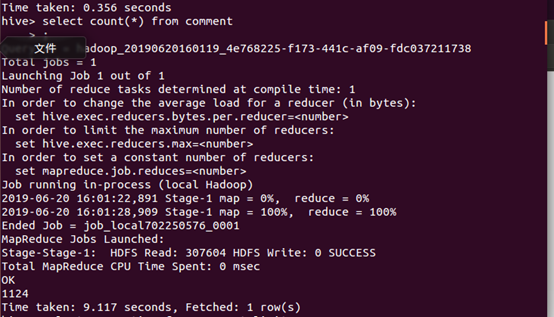
7、统计数据一共有1124条
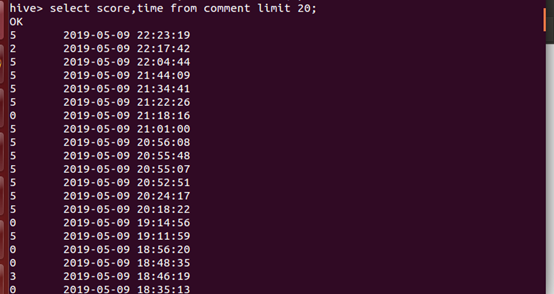
8、列出前20名观众分数和时间
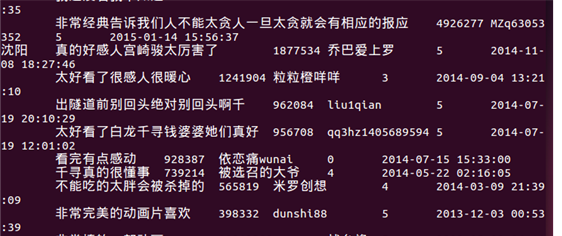
9、列出前20名观众的评论
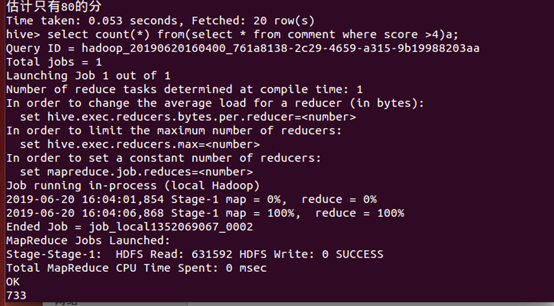
10、统计评论分数大于4分(总5分)的评论条数,大部分是大于4分,说明
《千与千寻》的好评率很高。
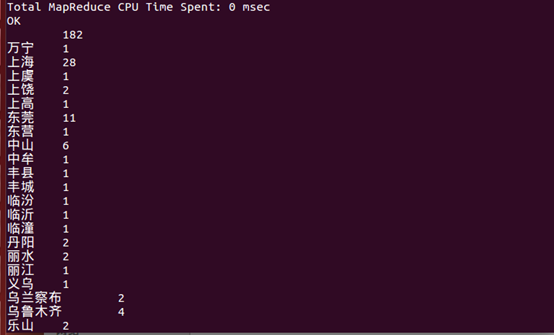
11、列出各城市的评论数
12、统计北京的评论数
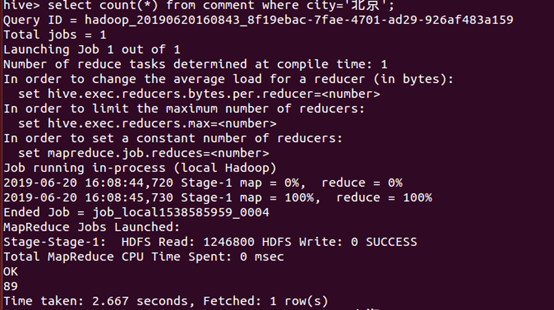
13、统计上海的评论数
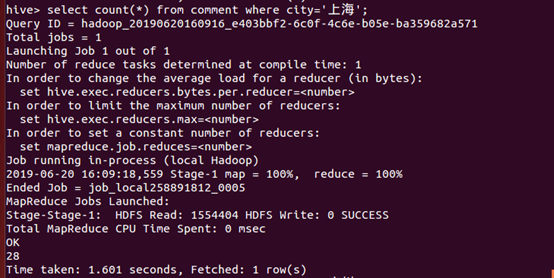
14、统计广州的评论数
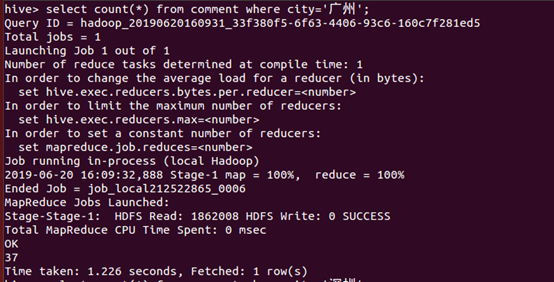
15、统计深圳的评论数
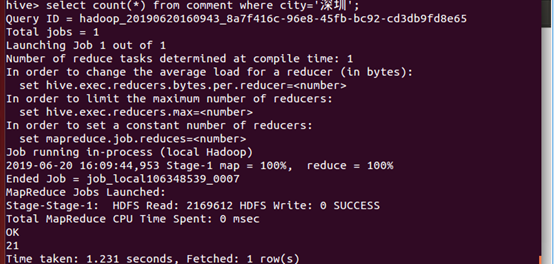
、、、、、
本作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3310
利用Shell命令与HDFS进行交
1.目录操作:
(1)、在HDFS中为hadoop用户创建一个用户目录(hadoop用户):

(2)、在用户目录下创建一个input目录

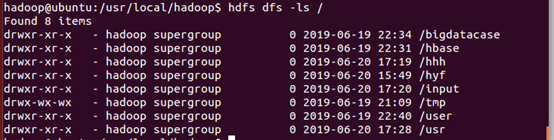
(3)、在HDFS的根目录下创建一个名称为input的目录
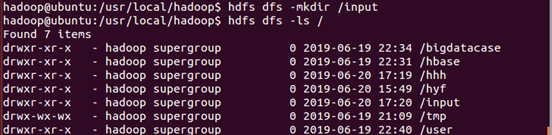
(4)、删除HDFS根目录中的“input”目录:

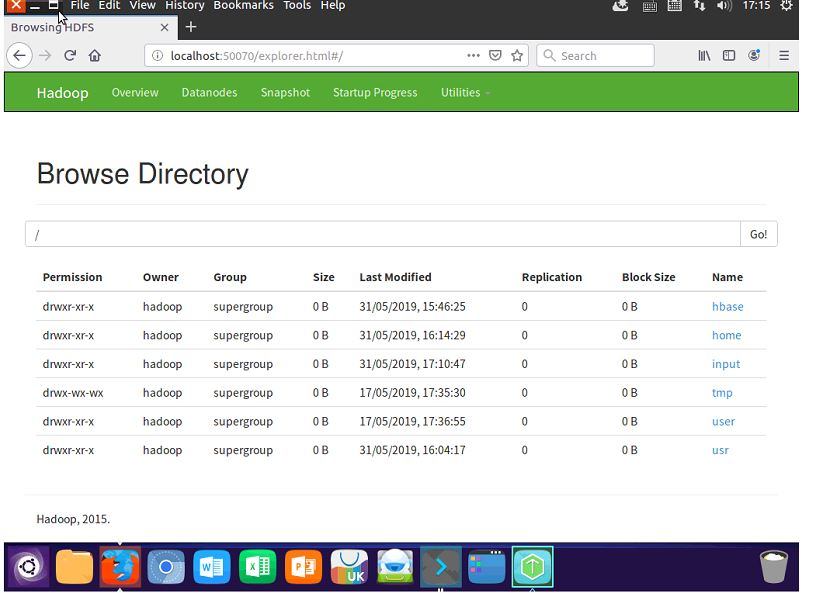
2.文件操作:
Hadoop综合大作业总评的更多相关文章
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.将爬虫大作业产生的csv文件上传到HDFS (1)在/usr ...
- 【大数据应用技术】作业十二|Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 前言 本次作业是在<爬虫大作业>的基础上进行的 ...
随机推荐
- Flask 和 Django 框架的区别
1)Flask Flask确实很“轻”,不愧是Micro Framework,从Django转向Flask的开发者一定会如此感慨,除非二者均为深入使用过 Flask自由.灵活,可扩展性强,第三方库的选 ...
- JavaWeb 之 MVC 开发模式
MVC 开发模式 一.JSP 演变历史 1. 早期只有servlet,只能使用response输出标签数据,非常麻烦 2. 后来又jsp,简化了Servlet的开发,如果过度使用jsp,在jsp中即写 ...
- 英语foteball足球foteball单词
现代足球起源地是在英格兰.传说在11世纪,英格兰与丹麦之间有过一场战争,战争结束后,英格兰人在清理战争废墟时发现一个丹麦入侵者的头骨,出于愤恨,他们便用脚去踢这个头骨,一群小孩见了便也来踢,不过他们发 ...
- POSIX多线程之创建线程pthread_create && 线程清理pthread_cleanup
多线程之pthread_create创建线程 pthreads定义了一套C程序语言类型.函数.与常量.以pthread.h和一个线程库实现. 数据类型: pthread_t:线程句柄 pthread_ ...
- 结对项目(python) 黄浩伟 黄飞越
作者:黄浩伟 黄飞越 一 .Github项目地址: https://github.com/Flying123haha/123.git 二.psp表格: PSP2.1 Personal Softwar ...
- 【RMAN】TSPITR--RMAN表空间基于时间点的自动恢复
[RMAN]TSPITR--RMAN表空间基于时间点的自动恢复 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其 ...
- 微信小程序 - 定位功能
(1) 查看微信小程序文档 大家可以从我截图中可以看到,API中的返回值有纬度和经度,所以我们接下来就是要用到纬度和经度逆地址解析出地址的一些信息. (2)注册腾讯地图开放平台 注册完之后选择WebS ...
- Spring中获取被代理的对象
目录 Spring中获取被代理的对象 获取Spring被代理对象什么时候可能会用到? Spring中获取被代理的对象 Spring中获取被代理的对象 ### 获取Spring被代理对象的JAVA工具类 ...
- 【RocketMQ】同一个项目中,同一个topic,可以存在多个消费者么?
一.问题答案 是不可以的 而且后注册的会替换前注册的,MqConsumer2会替换MqConsumer,并且只结束tag-2的消息 /** * @date 2019/05/28 */ @Compone ...
- C++(五十一) — 容器中常见算法(查找、排序、拷贝替换)
1.find(); find()算法的作用是在指定的一段序列中查找某个数,包含三个参数,前两个参数是表示元素范围的迭代器,第三个参数是要查找的值. 例:fing(vec.begin(), vec.en ...