大数据(1)---大数据及HDFS简述
一、大数据简述
在互联技术飞速发展过程中,越来越多的人融入互联网。也就意味着各个平台的用户所产生的数据也越来越多,可以说是爆炸式的增长,以前传统的数据处理的技术已经无法胜任了。比如淘宝,每天的活跃用户量是很大的一个数目。马云之前说过某个省份的女性bar的size最小问题,不管是玩笑还什么,细想而知,基于淘宝用户的购物记录确实可以分析出来。
对企业的用户数据进行分析,可以知道公司产品的运营情况,比方说一个APP的用户每天登陆了几乎都没有什么实质性的操作,那就说明这个玩意儿已经快凉了,程序员赶快可以跑路了。
每个人登录哪些电商网站的首页都是不一样,这后面就是根据用户的近期浏览或者关注的,根据这些来生成推送每个人关注的商品。
对于这些海量的数据的处理分析所诞生的技术,也就是大数据。
对于这些数据两个核心点,一个如何存储,另一个就是怎么使用。
相关的技术:
存储框架:
HDFS——分布式文件存储系统(HADOOP生态中的存储框架)
HBASE——分布式数据库系统
KAFKA——分布式消息缓存系统(实时流式数据处理场景中应用广泛)
运算框架:(要解决的核心问题就是帮用户将处理逻辑在很多机器上并行)
MAPREDUCE—— 分布式计算(HADOOP中的运算框架)
SPARK —— 离线批处理/实时流式计算
STORM —— 实时流式计算
其他框架:
HIVE —— 数据仓库工具:可以接收sql,翻译成mapreduce或者spark程序运行
FLUME——数据采集
SQOOP——数据迁移
ELASTIC SEARCH —— 分布式的搜索引擎
.......
.......
.......
二、HDFS简述
hadoop中有3个核心组件:
分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上
分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运算
分布式资源调度平台:YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
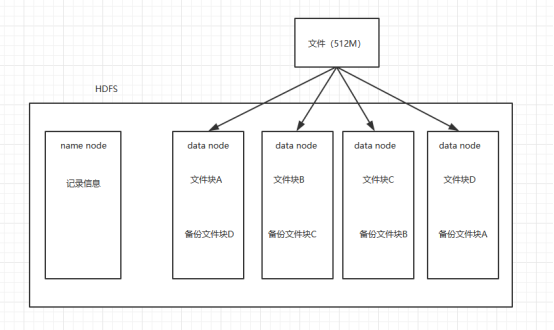
HDFS---分布式文件系统,相当于就是一个目录树,一层一层的,这个是虚拟的出来一个结构,由HDFS管理,并不能实际看见,只能通过客户端去访问的时候可以看见这些结构。
1.一个数据在HDFS上面存储的时候会根据大小来进行分块,被分块之后,存放在多个机器上面(data node),比如一个512M的文件,如果按照128M来分,就会被分成4块,然后
存储到4个节点上。
2.一般来说为了保证数据的高可用,我们会把同一个数据块备份到不同的节点上面,某个节点挂了,还可以在其他节点上面找到数据。意思就说数据块A既会在A机器上存储,也会在机器B上面存储一份,甚至更多的备份。
3.分块存储之后怎么直到数据存在哪些机器上呢,这个时候就需要一个管理者来记录这些数据信息(name node)
也就是说一个HDFS系统是由name node服务器和多个data node服务组成
大数据(1)---大数据及HDFS简述的更多相关文章
- 大数据技术之Hadoop(HDFS)
第1章 HDFS概述 1.1 HDFS产出背景及定义 1.2 HDFS优缺点 1.3 HDFS组成架构 1.4 HDFS文件块大小(面试重点) 第2章 HDFS的Shell操作(开发重点) 1.基本语 ...
- 大数据学习(03)——HDFS的高可用
高可用架构图 先上一张搜索来的图. 如上图,HDFS的高可用其实就是NameNode的高可用. 上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameN ...
- 1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上
一.数据仓库架构 二.flume收集数据存储到hdfs 文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hd ...
- 大快DKH大数据智能分析平台监控参数说明
2018年国内大数据公司50强榜单排名已经公布了出来,大快以黑马之姿闯入50强,并摘得多项桂冠.Hanlp自然语言处理技术也荣膺了“2018中国数据星技术”奖.对这份榜单感兴趣的可以找一下看看.本篇承 ...
- ASP.NET MVC导出excel(数据量大,非常耗时的,异步导出)
要在ASP.NET MVC站点上做excel导出功能,但是要导出的excel文件比较大,有几十M,所以导出比较费时,为了不影响对界面的其它操作,我就采用异步的方式,后台开辟一个线程将excel导出到指 ...
- chart.js插件生成折线图时数据普遍较大时Y轴数据不从0开始的解决办法[bubuko.com]
chart.js插件生成折线图时数据普遍较大时Y轴数据不从0开始的解决办法,原文:http://bubuko.com/infodetail-328671.html 默认情况下如下图 Y轴并不是从0开始 ...
- MVC学习笔记---MVC导出excel(数据量大,非常耗时的,异步导出)
要在ASP.NET MVC站点上做excel导出功能,但是要导出的excel文件比较大,有几十M,所以导出比较费时,为了不影响对界面的其它操作,我就采用异步的方式,后台开辟一个线程将excel导出到指 ...
- MySQL数据很大的时候
众所周知,mysql在数据量很大的时候查询的效率是很低的,因为假如你需要 OFFSET 100000 LIMIT 5 这样的数据,数据库就需要跳过前100000条数据,才能返回给你你需要的5条数据.由 ...
- BLOB:大数据,大对象,在数据库中用来存储超长文本的数据,例如图片等
将一张图片存储在mysql中,并读取出来(BLOB数据:插入BLOB类型的数据必须使用PreparedStatement,因为插入BLOB类型的数据无法使用字符串拼写): -------------- ...
随机推荐
- python 排序 插入排序与希尔排序
希尔排序是插入排序的升级版,先来了解插入排序 插入排序 算法思想: 插入排序再面对几乎已经有序的数据效率非常高,可以达到线性排序的效率 将数组元素插入已经有序的部分中,具体的过程是在有序的部分中通过比 ...
- Eureka重要对象简介
在进行分析EurekaClient和EurekaServer之间通信的源码之前,我们首先需要熟悉一下几个实体类 InstanceInfo 这个类代表着EurekaClient实例,客户端向服务端请求注 ...
- 设计模式之(九)桥接模式(Bridge)
桥接模式是怎么诞生的呢?来看一个场景. 一个软件企业开发一套系统,要兼容所有的不同类型硬件和和各种操作系统.不同种类硬件主要是 电脑.平板电脑.手机.各种操作系统是苹果系统.windows 系统.Li ...
- Vue – 基础学习(4):事件修饰符
Vue – 基础学习(3):事件修饰符
- c# 读数据库二进制流到图片
public Bitmap PictureShow(string connectionString, string opName, string productType) { ...
- JavaWeb 文件的上传、下载
文件上传 表单 <form action="HandlerServlet" method="post" enctype="multipart/f ...
- MySQL单表数据不要超过500万行:是经验数值,还是黄金铁律?
本文阅读时间大约3分钟. 梁桂钊 | 作者 今天,探讨一个有趣的话题:MySQL 单表数据达到多少时才需要考虑分库分表?有人说 2000 万行,也有人说 500 万行.那么,你觉得这个数值多少才合适呢 ...
- Odoo中的字段显示方式和行为控制
在odoo的视图中,字段都是通过widget来控制显示效果和行为的. 一般情况下,不同类型的字段odoo会使用默认的widget来显示和控制它的行为. options以一种JSON对象的形 ...
- Linux虚拟机修改ip地址,查看网关,网络环境配置
修改虚拟机的ip地址: 进入如下界面,直接修改子网ip即可. 查看网关: Linux网络环境配置: 第一种方式(自动获取): 说明:登陆后,通过界面来设置自动获取ip 我们先进入设置: 把自动连接勾上 ...
- alpine基础镜像使用
关于Alpine的相关知识,可以参考下边的链接 https://yeasy.gitbooks.io/docker_practice/content/cases/os/alpine.html 一. al ...