MySQL数据库汇总
select date_format(create_time, '%Y-%m-%d') dat, count(*),
sum(work_indicator) as totalWorkIndicator,
sum(work_compelete_indicator) as totalWorkCompeleteIndicator
from merchants_work_indicator_history
WHERE work_type =#{recordType}
and DATE_FORMAT(create_time,'%Y%m') = DATE_FORMAT(CURDATE(),'%Y%m')
group by date_format(create_time, '%Y-%m-%d')
order by dat asc;
https://www.cnblogs.com/cxiaocai/p/11594151.html
SHOW STATUS LIKE '%Connection%';
SHOW VARIABLES LIKE '%max_connections%';
SHOW PROCESSLIST;
lock table student write; 加表锁
show open tables;查看表状态(是否被加锁)
内有有一个列为In_use为1的即为已有锁存在。
show status;
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 58 |
| Threads_connected | 57 | ###这个数值指的是打开的连接数
| Threads_created | 3676 |
| Threads_running | 4 | ###这个数值指的是激活的连接数,这个数值一般远低于connected数值
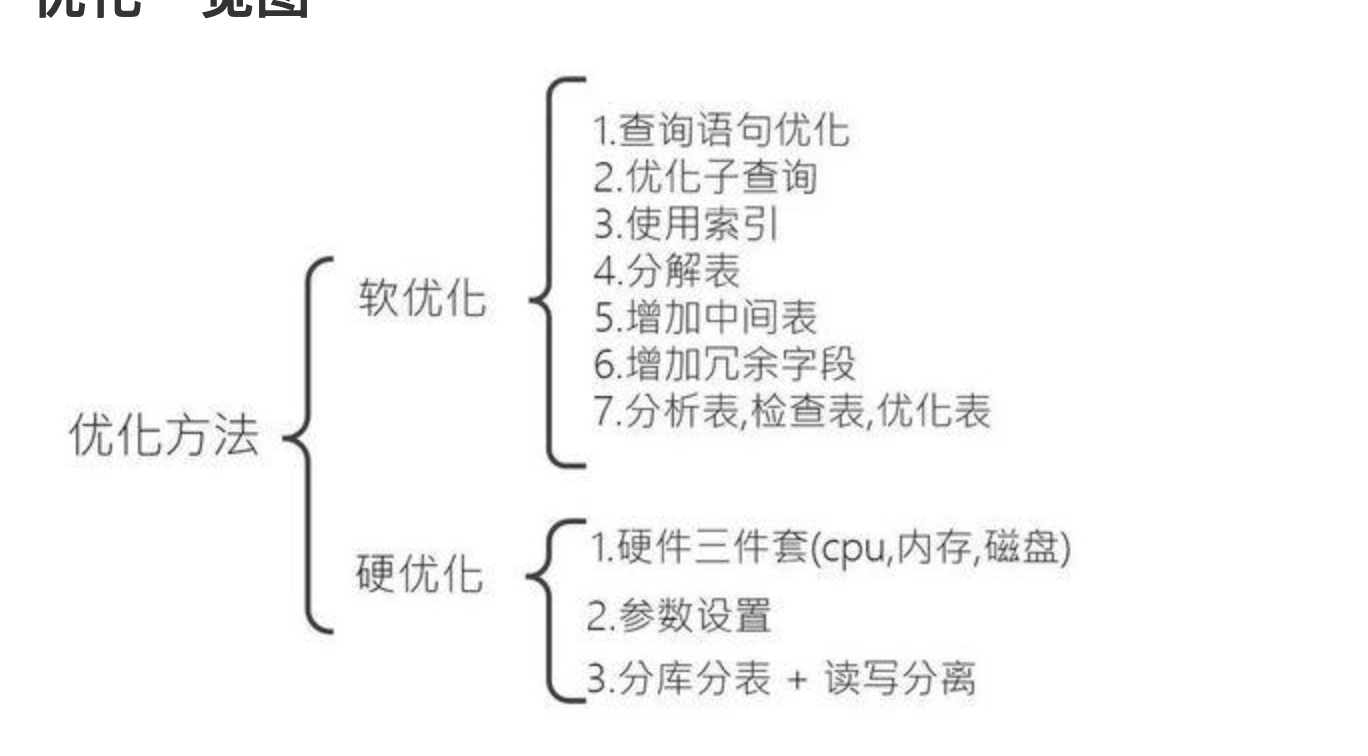
数据库性能优化
1.建立索引
2.多表关联进行单表查询
3.数据查询where条件进行从右先过滤大的条件
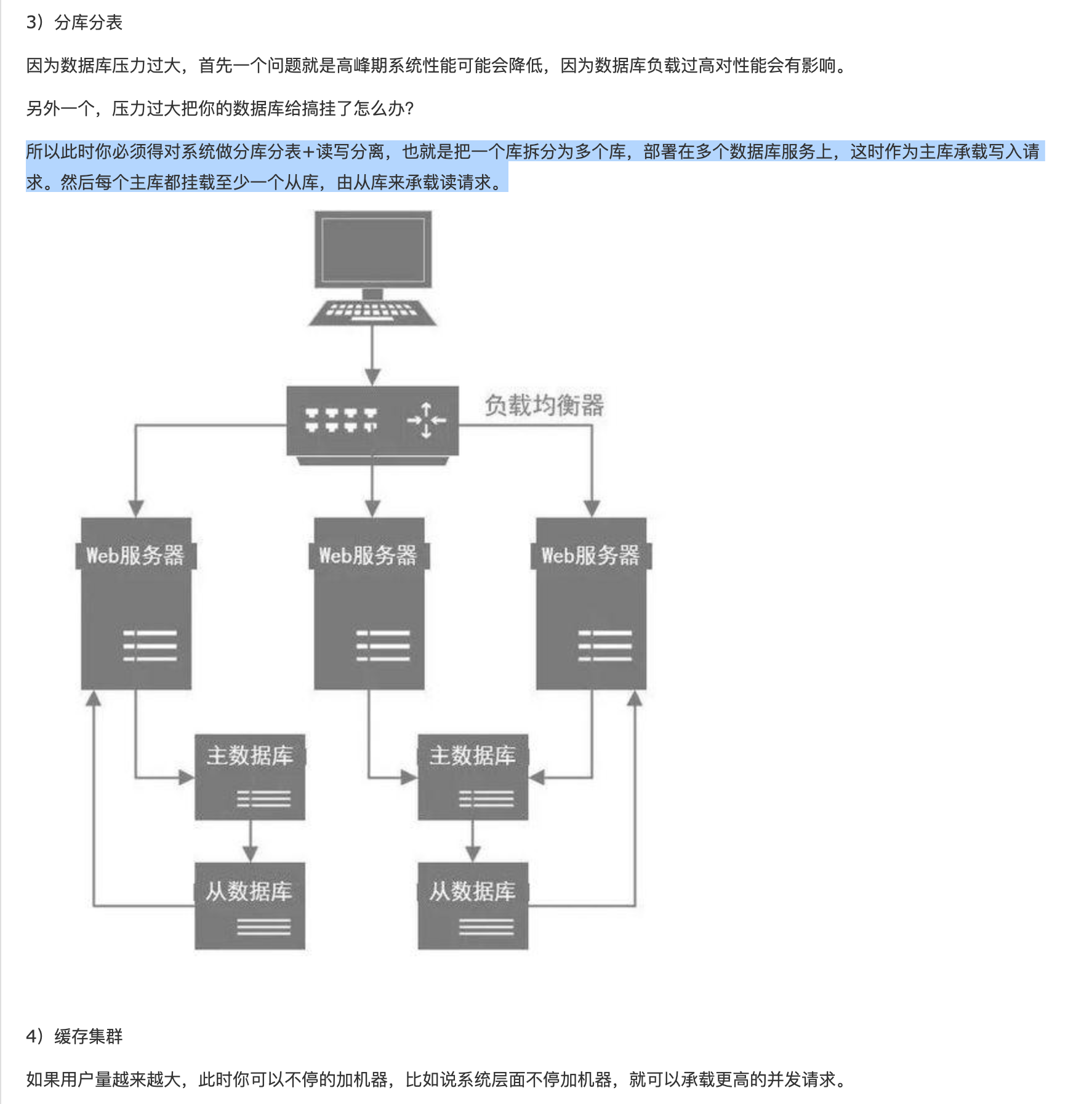
5、数据库主从分离,读写分离,降低读写针对同一表同时的压力,至于主从同步,MySQL有自带的binlog实现 主从同步;
数据处理
SELECT
count(1)
FROM
hzc.usr_profiles as u
LEFT JOIN hzc.tblorder AS t ON u.id=t.profile_id
where
u.mobile in (SELECT
a.mobile
FROM
opt.opt_user_travel_info as a) AND t.OrderID IS NULL or t.payment_status in(3,4);
-- SELECT count(TIMESTAMPDIFF(HOUR,now(),DATE_ADD(election_time, INTERVAL 15 DAY))) as hours
-- from apply_city_master
select count(id) from apply_city_master where HOUR(timediff(now(), expiry_time)) <= 24 and apply_status=2 SELECT order_num,SUM(quantity*item_price) AS ordertotal FROM orderitems GROUP BY order_num HAVING SUM(quantity*item_price) >=50 ORDER BY ordertotal;
非前导则可以使用索引
select name from user where name like 'zhangsan%'
- 1>.InnoDB支持事物,而MyISAM不支持事物
- 2>.InnoDB支持行级锁,而MyISAM支持表级锁
- 3>.InnoDB支持MVCC, 而MyISAM不支持
- 4>.InnoDB支持外键,而MyISAM不支持
- 5>.InnoDB不支持全文索引,而MyISAM支持。
- from (注:这里也包括from中的子语句)
- join
- on
- where
- group by(开始使用select中的别名,后面的语句中都可以使用)
- avg,sum.... 等聚合函数
- having
- select
- distinct
- order by
- limit
1. 怎么验证 mysql 的索引是否满足需求?
使用 explain 查看 SQL 是如何执行查询语句的,从而分析你的索引是否满足需求。
explain 语法:explain select * from table where type=1。
TIMESTAMPDIFF(DAY,now(),min(t2.expiry_time)),
SELECT `userspk`.`avatar` AS `user_avatar`,
`a`.`user_id`,
`a`.`answer_record`,
MAX(`score`) AS `score`
FROM (select * from pkrecord order by score desc) as a
INNER JOIN `userspk` AS `userspk`
ON `a`.`user_id` = `userspk`.`user_id`
WHERE `a`.`status` = 1
AND `a`.`user_id` != 'm_6da5d9e0-4629-11e9-b5f7-694ced396953'
GROUP BY `user_id`
ORDER BY `a`.`score` DESC
LIMIT 9; //不使用子查询
SELECT `userspk`.`avatar` AS `user_avatar`,
`pkrecord`.`user_id`,
`pkrecord`.`answer_record`,
`pkrecord`.`id`,
MAX(`score`) AS `score`
FROM pkrecord
INNER JOIN `userspk` AS `userspk`
ON `pkrecord`.`user_id` = `userspk`.`user_id`
WHERE `pkrecord`.`status` = 1
AND `pkrecord`.`user_id` != 'm_6da5d9e0-4629-11e9-b5f7-694ced396953'
GROUP BY `user_id`
ORDER BY `pkrecord`.`score` DESC
LIMIT 9;
MySql查询某一天的数据
select SUM(actual_deduction_price) from income_details where user_id=20 and create_time>='2019-07-25 00:00:00' and create_time<='2019-07-25 23:59:59';
select SUM(actual_deduction_price) from income_details where user_id=20 and create_time between '2019-07-25 00:00:00' and '2019-07-25 23:59:59';
SELECT SUM(actual_deduction_price) from income_details where user_id=20 and create_time > '2019-07-25' and create_time < '2019-07-26';
SELECT SUM(actual_deduction_price) from income_details where user_id=20 and (datediff(create_time,'2019-07-25')=0);
索引:B+,B-,全文索引
Mysql的索引是一个数据结构,旨在使数据库高效的查找数据。
常用的数据结构是B+Tree,每个叶子节点不但存放了索引键的相关信息还增加了指向相邻叶子节点的指针,这样就形成了带有顺序访问指针的B+Tree,做这个优化的目的是提高不同区间访问的性能。
什么时候使用索引:
经常出现在group by,order by和distinc关键字后面的字段
经常与其他表进行连接的表,在连接字段上应该建立索引
经常出现在Where子句中的字段
经常出现用作查询选择的字段
1)首先我们可以用EXPLAIN或DESCRIBE(简写:DESC)命令分析一条查询语句的执行信息。
DESC SELECT * FROM `user`
2)优化子查询
在MySQL中,尽量使用JOIN来代替子查询。因为子查询需要嵌套查询,嵌套查询时会建立一张临时表,临时表的建立和删除都会有较大的系统开销,而连接查询不会创建临时表,因此效率比嵌套子查询高。
3)使用索引
索引是提高数据库查询速度最重要的方法之一,使用索引的三大注意事项包括:
LIKE关键字匹配'%'开头的字符串,不会使用索引;
OR关键字的两个字段必须都是用了索引,该查询才会使用索引;
使用多列索引必须满足最左匹配。
4)分解表
对于字段较多的表,如果某些字段使用频率较低,此时应当将其分离出来从而形成新的表。
5)中间表
对于将大量连接查询的表可以创建中间表,从而减少在查询时造成的连接耗时。
6)增加冗余字段
类似于创建中间表,增加冗余也是为了减少连接查询。
7)分析表、检查表、优化表
分析表主要是分析表中关键字的分布;检查表主要是检查表中是否存在错误;优化表主要是消除删除或更新造成的表空间浪费。
分析表: 使用 ANALYZE 关键字,如ANALYZE TABLE user
select t1.id,t1.city_name,GROUP_CONCAT(t2.mobile) as mobile,t2.city_type,t2.apply_status
from city_config as t1
left join apply_city_master as t2
on t1.id=t2.city_id
where t2.apply_status=4
and t1.id=363
GROUP BY city_type
ORDER BY t2.create_time
select GROUP_CONCAT(t2.mobile) as mobile,t2.city_type from apply_city_master as t2 where t2.city_id=363 and t2.apply_status=4 GROUP BY t2.city_type ORDER BY t2.create_time
select
(
CASE
WHEN (a1.city_type=1) THEN a1.mobile
END
)AS citymaster,
(
CASE
WHEN (a1.city_type=2) THEN a1.mobile
END
)AS citymaster2,
(
CASE
WHEN (a1.city_type=3) THEN a1.mobile
END
)AS citymaster3
from
(
select GROUP_CONCAT(t2.mobile) as mobile,t2.city_type from apply_city_master as t2 where t2.city_id=363 and t2.apply_status=4 GROUP BY t2.city_type ORDER BY t2.create_time
) as a1
select
(
CASE
WHEN (a1.city_type=1) THEN a1.mobile
WHEN (a1.city_type=2) THEN a1.mobile
WHEN (a1.city_type=3) THEN a1.mobile
END
)AS citymaster
from
(
select GROUP_CONCAT(t2.mobile) as mobile,t2.city_type from apply_city_master as t2 where t2.city_id=363 and t2.apply_status=4 GROUP BY t2.city_type ORDER BY t2.create_time
) as a1


MySQL数据库汇总的更多相关文章
- .net连mysql数据库汇总
另外MySql官方出了一个在csharp里面连接MySql的Connector,可以试试 http://dev.mysql.com/downloads/#connector-net <add n ...
- MySQL数据库— 汇总和分组数据
一 汇总和分组数据 查询语句 ---> 结果集(多条数据) ---> 聚合函数 ----> 单行记录 1.常用的聚合函数: sum() 数字 ...
- Shell脚本使用汇总整理——mysql数据库5.7.8以前备份脚本
Shell脚本使用汇总整理——mysql数据库5.7.8以前备份脚本 Shell脚本使用的基本知识点汇总详情见连接: https://www.cnblogs.com/lsy-blogs/p/92234 ...
- Shell脚本使用汇总整理——mysql数据库5.7.8以后备份脚本
Shell脚本使用汇总整理——mysql数据库5.7.8以后备份脚本 Shell脚本使用的基本知识点汇总详情见连接: https://www.cnblogs.com/lsy-blogs/p/92234 ...
- Linux上通过MySQL命令访问MySQL数据库时常见问题汇总
Linux上通过mysql命令访问MySQL数据库时常见问题汇总 1)创建登录账号 #创建用户并授权 #允许本地访问 create user 'test'@'localhost' identified ...
- MySQL 数据库备份种类以及常用备份工具汇总
1,数据库备份种类 按照数据库大小备份,有四种类型,分别应用于不同场合,下面简要介绍一下: 1.1完全备份 这是大多数人常用的方式,它可以备份整个数据库,包含用户表.系统表.索引.视图和存储过程等所有 ...
- mysql自身报错、java、reids连接mysql数据库报错汇总
1.Can't connect to local MySQL server through socket 'tmpmysql.sock' (2) 原因是mysql根本没有启动 2.Access den ...
- MySQL笔记汇总
[目录] MySQL笔记汇总 一.mysql简介 数据简介 结构化查询语言 二.mysql命令行操作 三.数据库(表)更改 表相关 字段相关 索引相关 表引擎操作 四.数据库类型 数字型 字符串型 日 ...
- MySQL数据库学习笔记(四)----MySQL聚合函数、控制流程函数(含navicat软件的介绍)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
随机推荐
- [转]TrueType(TTF)字体文件裁剪(支持简体中文,繁体中文TTF字体裁剪)
原文入口: TTF字体文件裁剪(支持简体中文,繁体中文TTF字体裁剪) 对于TrueType(TTF)字体格式的介绍可以看: https://www.cnblogs.com/slysky/p/1131 ...
- 在Windows平台下使用Gitblit搭建Git服务器图文解说
Windows平台下Git服务器搭建 一.java环境变量的设置 下载jdk并配置jdk的环境变量,JAVA_HOME,CLASSPATH以及PATH,最后在DOS窗口输入java -version检 ...
- SpringBoot处理异常方式
SpringBoot提供了多种处理异常方式,以下为常用的几种 1. 自定义错误异常页面 SpringBoot默认的处理异常的机制:SpringBoot默认的已经提供了一套处理异常的机制.一旦程序中出现 ...
- Spring Shell入门介绍
目录 Spring Shell是什么 入门实践 基础配置 简单示例 注解@ShellMethod 注解@ShellOption 自定义参数名称 设置参数默认值 为一个参数传递多个值 对布尔参数的特殊处 ...
- IDEA中类文件显示J,IDEA Unable to import maven project: See logs for details
今天用了下lemon清理了下垃圾后,IDEA打开项目类文件图标由C变为J,在IDEA右侧的Maven Project中点击刷新提示IDEA Unable to import maven project ...
- sourceTree安装和使用(windows)
SourceTree的简介 SourceTree 是 Windows 和Mac OS X 下免费的 Git 和 Hg 客户端,拥有可视化界面,容易上手操作.同时它也是Mercurial和Subve ...
- java 查看类是从哪个jar包加载的
package com.jason object FIndjar { def main(args: Array[String]): Unit = { val pd = classOf[org.apac ...
- sql调优方法实用性总结(一)
1.选择最有效率的表名顺序(只在基于规则的优化器): Oracle的解析器按照从右向左的顺序处理FROM子句中的表名,FROM子句中写在最后的表将被最先处理(基础表先处理,driving table) ...
- git 删除本地分支,删除远程分支
本地分支 git branch -d 分支名 远程分支 git push origin --delete 分支名 查看所有分支 git branch -a
- Java打开GC日志
环境: JDK1.8 打开GC日志: -verbose:gc 这个只会显示总的GC堆的变化, 如下: [GC (Allocation Failure) 80832K->19298K(2278 ...