Lucene创建索引和索引的基本检索(Lucene 之 Hello World)
Author: 百知教育 gaozhy
注:演示代码所使用jar包版本为 lucene-xxx-5.2.0.jar
一、lucene索引操作
1、创建索引代码
try {
// 1. 指定索引文件存储位置
Directory directory = FSDirectory.open(Paths.get("F:/lucene/index/example01"));
// 2. 创建分词器 标准分词器
StandardAnalyzer analyzer = new StandardAnalyzer();
// 3. 创建索引写入器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(OpenMode.CREATE_OR_APPEND); //索引不存在创建,索引存在追加
IndexWriter indexWriter = new IndexWriter(directory, config);
// 4. 创建索引文档
Document document = new Document();
document.add(new Field("id", "2", StringField.TYPE_STORED ));
document.add(new Field("name", "CoreJava实战",StringField.TYPE_STORED ));
document.add(new Field("content", "百知金牌讲师 胡鑫哲出品",TextField.TYPE_STORED));
// 5. 添加索引
indexWriter.addDocument(document);
// 6. 释放资源
indexWriter.commit();
indexWriter.close();
directory.close();
} catch (Exception e) {
e.printStackTrace();
}2、创建的索引文件

二、lucene索引的检索
1、索引检索代码
try{
// 1. 获取索引文件
Directory directory = FSDirectory.open(Paths.get("F:/lucene/index/example01"));
// 2. 读取索引文件
IndexReader indexReader = DirectoryReader.open(directory);
// 3. 创建索引检索器
IndexSearcher searcher = new IndexSearcher(indexReader);
// 4. 创建查询条件
QueryParser parser = new QueryParser("content",new StandardAnalyzer()); //第一个参数: 需要检索的域名 第二个参数: 分词器
Query query = parser.parse("百知"); //检索字符串
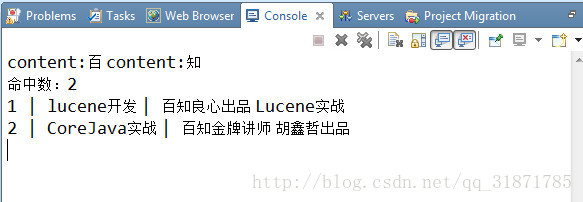
System.out.println(query.toString());
// 5. 调用检索器检索
TopDocs topDocs = searcher.search(query, 10); //第二个参数:返回结果 10条信息
System.out.println("命中数:"+topDocs.totalHits);
ScoreDoc[] docs = topDocs.scoreDocs;
// 6. 处理查询结果
for (ScoreDoc scoreDoc : docs) {
System.out.print(searcher.doc(scoreDoc.doc).get("id") + " | ");
System.out.print(searcher.doc(scoreDoc.doc).get("name") + " | ");
System.out.print(searcher.doc(scoreDoc.doc).get("content"));
System.out.println();
}
// 7. 释放资源
indexReader.close();
directory.close();
}catch(Exception e){
e.printStackTrace();
}2、检索结果
使用“百知”检索结果
原文出处:
高志遠, Lucene创建索引和索引的基本检索, https://blog.csdn.net/qq_31871785/article/details/70169743
Lucene创建索引和索引的基本检索(Lucene 之 Hello World)的更多相关文章
- lucene创建索引简单示例
利用空闲时间写了一个使用lucene创建索引简单示例, 1.使用maven创建的项目 2.需要用到的jar如下: 废话不多说,直接贴代码如下: 1.创建索引的类(HelloLucene): packa ...
- Lucene.net(4.8.0) 学习问题记录三: 索引的创建 IndexWriter 和索引速度的优化
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- lucene&solr学习——创建和查询索引(理论)
1.Lucene基础 (1) 简介 Lucene是apache下的一个开放源代码的全文检索引擎工具包.提供完整的查询引擎和索引引擎:部分文本分析引擎. Lucene的目的是为软件开发人员提供一个简单易 ...
- Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理
Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理 2017年01月04日 08:52:12 阅读数:18366 基于Lucene检索引擎我们开发了自己的全文检索系统,承担起后台PB ...
- SQLServer之创建辅助XML索引
创建辅助XML索引 使用 CREATE INDEX (Transact-SQL)Transact-SQL DDL 语句可创建辅助 XML 索引并且可指定所需的辅助 XML 索引的类型. 创建辅助 XM ...
- SQLServer之创建唯一聚集索引
创建唯一聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动 ...
- SQLServer之创建非聚集索引
开始之前 典型实现 可以通过下列方法实现非聚集索引: UNIQUE 约束 在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束. 如果不存在该表的聚集索引,则可以 ...
- mysql 索引及索引创建原则
是什么 索引用于快速的查询某些特殊列的某些行.如果没有索引, MySQL 必须从第一行开始,然后通过搜索整个表来查询有关的行.表越大,查询的成本越大.如果表有了索引的话,那么 MySQL 可以很快的确 ...
- (三)Lucene——Field域和索引的增删改
1. Field域 1.1 Field的属性 是否分词(Tokenized) 是:对该field存储的内容进行分词,分词的目的,就是为了索引. 比如:商品名称.商品描述.商品价格 否:不 ...
随机推荐
- php批量检查https证书有效期
function get_cert_info($domain){ $context = stream_context_create(['ssl' => [ 'capture_peer_cert' ...
- vue自定义指令VNode详解(转)
1.自定义指令钩子函数 Vue.directive('my-directive', {bind: function () {// 做绑定的准备工作// 比如添加事件监听器,或是其他只需要执行一次的复杂 ...
- Java 之 线程的生命周期(线程状态)
一.线程的生命周期 (1)新建状态 new 好了一个线程对象,此时和普通的 Java对象并没有区别. (2)就绪 就绪状态的线程是具备被CPU调用的能力和状态,也只有这个状态的线程才能被CPU调用.即 ...
- python可视化_matplotlib
对于Python数据可视化库,matplotlib 已经成为事实上的数据可视化方面最主要的库,此外还有很多其他库,例如vispy,bokeh, seaborn,pyga,folium 和 networ ...
- Linux命令groupadd
groupadd [选项] 组 创建一个新的组.Groupadd命令使用命令行中指定的值加上系统默认值创建新的组账户.新组将根据需要输入系统. (1).选项 -f,--force 如果指定的组已经存在 ...
- 整合Spring+Hibernate+Struts2的时候发现json数据一直无法传到页面,提示no-Session
执行了ajax,页面没有任何反应 怀疑json没有值,想查看json中的内容,使用了ObjectMapper: ObjectMapper om=new ObjectMapper(); System.o ...
- Odoo中的记录集
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10826218.html 一:record set 1:获取记录集 1)在@api.multi修饰器修饰的函数 ...
- PySpark DataFrame 添加自增 ID
PySpark DataFrame 添加自增 ID 本文原始地址:https://sitoi.cn/posts/62634.html 在用 Spark 处理数据的时候,经常需要给全量数据增加一列自增 ...
- Centos6.5基于GPT格式磁盘分区
1.查看分区 fdisk -l 2.设置分区类型未gpt格式. parted -s /dev/sdb mklabel gpt 3.基于ext3文件系统类型格式化. mkfs.ext3 /dev/sdb ...
- Java8的Stream API使用
前言 这次想介绍一下Java Stream的API使用,最近在做一个新的项目,然后终于可以从老项目的祖传代码坑里跳出来了.项目用公司自己的框架搭建完成后,我就想着把JDK版本也升级一下吧(之前的项目, ...