VAE论文学习
intractable棘手的,难处理的 posterior distributions后验分布 directed probabilistic有向概率
approximate inference近似推理 multivariate Gaussian多元高斯 diagonal对角 maximum likelihood极大似然
参考:https://blog.csdn.net/yao52119471/article/details/84893634
VAE论文所在讲的问题是:
我们现在就是想要训练一个模型P(x),并求出其参数Θ:
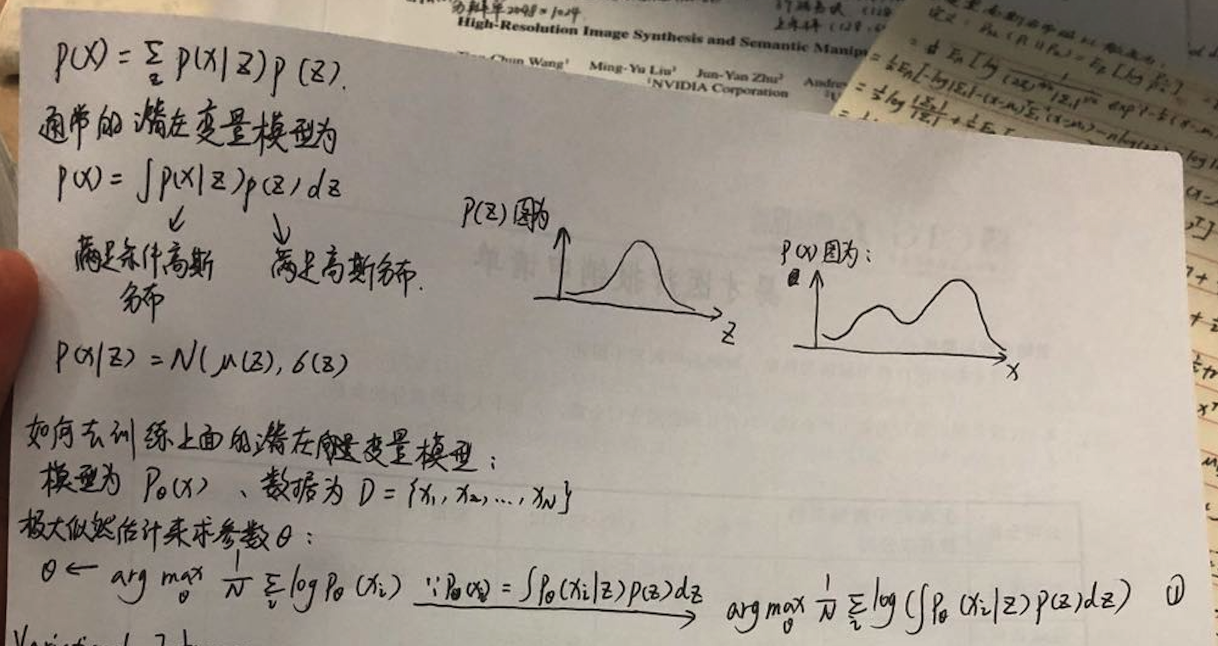
通过极大似然估计求其参数
Variational Inference
在论文中P(x)模型会被拆分成两部分,一部分由数据x生成潜在向量z,即pθ(z|X);一部分从z重新在重构数据x,即pθ(X|z)
实现过程则是希望能够使用一个qΦ(z|X)模型去近似pθ(z|X),然后作为模型的Encoder;后半部分pθ(X|z)则作为Decoder,Φ/θ表示参数,实现一种同时学习识别模型参数φ和参数θ的生成模型的方法,推导过程为:


现在问题就在于怎么进行求导,因为现在模型已经不是一个完整的P(x) = pθ(z|X) + pθ(X|z),现在变成了P(x) = qΦ(z|X) + pθ(X|z),那么如果对Φ求导就会变成一个问题,因此论文中就提出了一个reparameterization trick方法:

取样于一个标准正态分布来采样z,以此将qΦ(z|X) 和pθ(X|z)两个子模型通过z连接在了一起
最终的目标函数为:
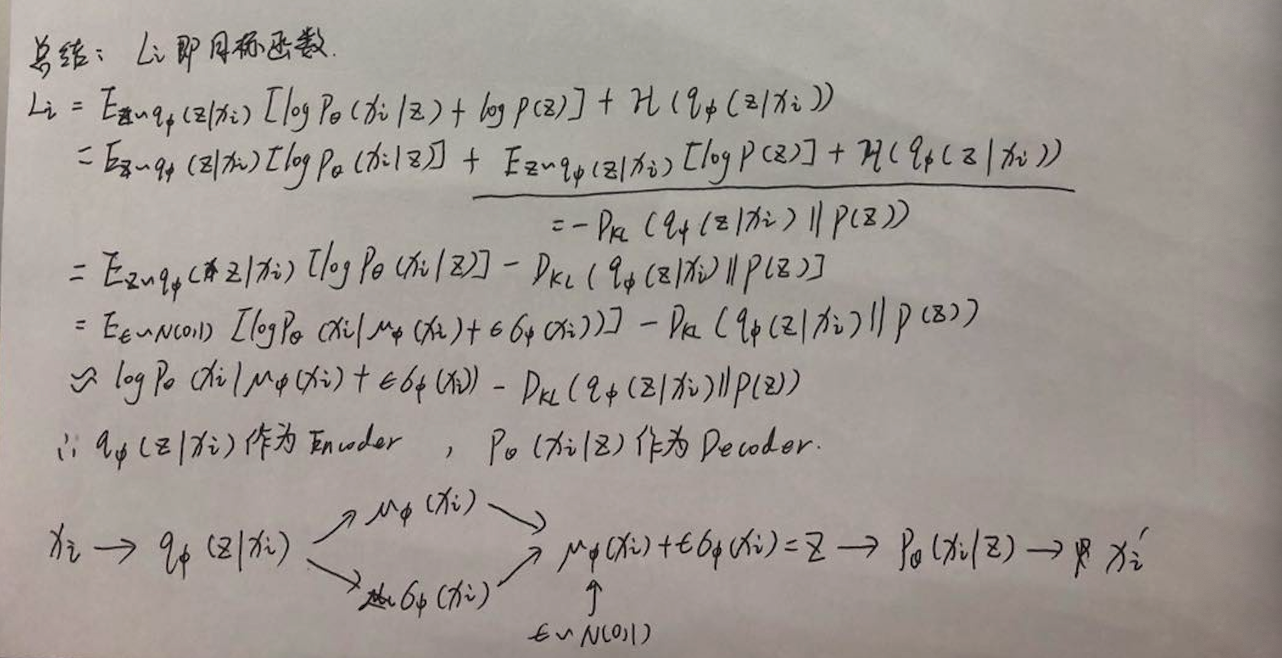
因此目标函数 = 输入和输出x求MSELoss - KL(qΦ(z|X) || pθ(z))
在论文上对式子最后的KL散度 -KL(qΦ(z|X) || pθ(z))的计算有简化为:

多维KL散度的推导可见:KL散度
假设pθ(z)服从标准正态分布,采样ε服从标准正态分布满足该假设

简单代码实现:
- import torch
- from torch.autograd import Variable
- import numpy as np
- import torch.nn.functional as F
- import torchvision
- from torchvision import transforms
- import torch.optim as optim
- from torch import nn
- import matplotlib.pyplot as plt
- class Encoder(torch.nn.Module):
- def __init__(self, D_in, H, D_out):
- super(Encoder, self).__init__()
- self.linear1 = torch.nn.Linear(D_in, H)
- self.linear2 = torch.nn.Linear(H, D_out)
- def forward(self, x):
- x = F.relu(self.linear1(x))
- return F.relu(self.linear2(x))
- class Decoder(torch.nn.Module):
- def __init__(self, D_in, H, D_out):
- super(Decoder, self).__init__()
- self.linear1 = torch.nn.Linear(D_in, H)
- self.linear2 = torch.nn.Linear(H, D_out)
- def forward(self, x):
- x = F.relu(self.linear1(x))
- return F.relu(self.linear2(x))
- class VAE(torch.nn.Module):
- latent_dim =
- def __init__(self, encoder, decoder):
- super(VAE, self).__init__()
- self.encoder = encoder
- self.decoder = decoder
- self._enc_mu = torch.nn.Linear(, )
- self._enc_log_sigma = torch.nn.Linear(, )
- def _sample_latent(self, h_enc):
- """
- Return the latent normal sample z ~ N(mu, sigma^)
- """
- mu = self._enc_mu(h_enc)
- log_sigma = self._enc_log_sigma(h_enc) #得到的值是loge(sigma)
- sigma = torch.exp(log_sigma) # = e^loge(sigma) = sigma
- #从均匀分布中取样
- std_z = torch.from_numpy(np.random.normal(, , size=sigma.size())).float()
- self.z_mean = mu
- self.z_sigma = sigma
- return mu + sigma * Variable(std_z, requires_grad=False) # Reparameterization trick
- def forward(self, state):
- h_enc = self.encoder(state)
- z = self._sample_latent(h_enc)
- return self.decoder(z)
- # 计算KL散度的公式
- def latent_loss(z_mean, z_stddev):
- mean_sq = z_mean * z_mean
- stddev_sq = z_stddev * z_stddev
- return 0.5 * torch.mean(mean_sq + stddev_sq - torch.log(stddev_sq) - )
- if __name__ == '__main__':
- input_dim = *
- batch_size =
- transform = transforms.Compose(
- [transforms.ToTensor()])
- mnist = torchvision.datasets.MNIST('./', download=True, transform=transform)
- dataloader = torch.utils.data.DataLoader(mnist, batch_size=batch_size,
- shuffle=True, num_workers=)
- print('Number of samples: ', len(mnist))
- encoder = Encoder(input_dim, , )
- decoder = Decoder(, , input_dim)
- vae = VAE(encoder, decoder)
- criterion = nn.MSELoss()
- optimizer = optim.Adam(vae.parameters(), lr=0.0001)
- l = None
- for epoch in range():
- for i, data in enumerate(dataloader, ):
- inputs, classes = data
- inputs, classes = Variable(inputs.resize_(batch_size, input_dim)), Variable(classes)
- optimizer.zero_grad()
- dec = vae(inputs)
- ll = latent_loss(vae.z_mean, vae.z_sigma)
- loss = criterion(dec, inputs) + ll
- loss.backward()
- optimizer.step()
- l = loss.data[]
- print(epoch, l)
- plt.imshow(vae(inputs).data[].numpy().reshape(, ), cmap='gray')
- plt.show(block=True)
VAE论文学习的更多相关文章
- Faster RCNN论文学习
Faster R-CNN在Fast R-CNN的基础上的改进就是不再使用选择性搜索方法来提取框,效率慢,而是使用RPN网络来取代选择性搜索方法,不仅提高了速度,精确度也更高了 Faster R-CNN ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,"预留"发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6f ...
- FactorVAE论文学习-1
Disentangling by Factorising 我们定义和解决了从变量的独立因素生成的数据的解耦表征的无监督学习问题.我们提出了FactorVAE方法,通过鼓励表征的分布因素化且在维度上独立 ...
- GoogleNet:inceptionV3论文学习
Rethinking the Inception Architecture for Computer Vision 论文地址:https://arxiv.org/abs/1512.00567 Abst ...
- IEEE Trans 2008 Gradient Pursuits论文学习
之前所学习的论文中求解稀疏解的时候一般采用的都是最小二乘方法进行计算,为了降低计算复杂度和减少内存,这篇论文梯度追踪,属于贪婪算法中一种.主要为三种:梯度(gradient).共轭梯度(conjuga ...
- Raft论文学习笔记
先附上论文链接 https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf 最近在自学MIT的6.824分布式课程,找到两个比较好的githu ...
- 论文学习-系统评估卷积神经网络各项超参数设计的影响-Systematic evaluation of CNN advances on the ImageNet
博客:blog.shinelee.me | 博客园 | CSDN 写在前面 论文状态:Published in CVIU Volume 161 Issue C, August 2017 论文地址:ht ...
随机推荐
- JDK源码那些事儿之LinkedTransferQueue
在JDK8的阻塞队列实现中还有两个未进行说明,今天继续对其中的一个阻塞队列LinkedTransferQueue进行源码分析,如果之前的队列分析已经让你对阻塞队列有了一定的了解,相信本文要讲解的Lin ...
- nginx+keepalived高可用 (主从+双主)
1.Nginx+keepalived 主从配置这种方案,使用一个vip地址,前端使用2台机器,一台做主,一台做备,但同时只有一台机器工作,另一台备份机器在主机器不出现故障的时候,永远处于浪费状态,对于 ...
- java中的String要点解析
String类使我们经常使用的一个类,经常用来表示字符串常量. 字符串一旦被创建赋值,就不能被改变,因为String 底层是数组实现的,且被定义成final类型.我们可以看String源码. /** ...
- String 堆内存和栈内存
java把内存划分为两种:一种是栈(stack)内存,一种是堆(heap)内存 在函数中定义的一些基本类型的变量和对象的引用变量都在栈内存中分配,当在一段代码块定义一个变量时,java就在栈中为这个变 ...
- laravel5.8 编译laravel mix
如果第一次无需执行(如果编译的时候出错再次执行才需要) 1:rm -rf node_modules 更改镜像为淘宝镜像 2:yarn config set registry https://regis ...
- Linux命令基础1-环境介绍
1.linux的简单历史 1)先有unix,后来有linux 2)linux操作系统是开源和免费的,里面的软件可能部分要收费 3)linux有不同发行版本,redhat,centos等. 4)1991 ...
- 什么是C/S和B/S架构?
C/S架构 C/S即:Client与Server ,中文意思:客户端与服务器端架构,这种架构也是从用户层面(也可以是物理层面)来划分的. 这里的客户端一般泛指客户端应用程序EXE,程序需要先安装后,才 ...
- dedecms搜索下拉
今天公司用dedecms做一个音乐站,要用到下拉标题搜索,我在本地做的一个测试结果 以下是代码部分(ps:二级栏目不用的可以删除代码,如果只调用某一个栏目或者2个栏目可以用typeid='1,2'):
- Centos7 docker pull速度特别慢
vim /etc/docker/daemon.json { "registry-mirrors" : ["https://docker.mirrors.ustc.edu. ...
- learning java Runtime类中的exec
var rt = Runtime.getRuntime(); // 类c语言当中的system()函数. rt.exec("notepad.exe");