Spark累加器(Accumulator)
一、累加器简介
在Spark中如果想在Task计算的时候统计某些事件的数量,使用filter/reduce也可以,但是使用累加器是一种更方便的方式,累加器一个比较经典的应用场景是用来在Spark Streaming应用中记录某些事件的数量。
使用累加器时需要注意只有Driver能够取到累加器的值,Task端进行的是累加操作。
创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名,下面探讨如何在Spark Web UI上查看累加器的值。
示例代码:
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.api.java.function.ForeachFunction;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.LongAccumulator; import java.util.Collections;
import java.util.concurrent.TimeUnit; /**
* @author CC11001100
*/
public class SparkWebUIShowAccumulatorDemo { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
LongAccumulator fooCount = spark.sparkContext().longAccumulator("fooCount"); spark.createDataset(Collections.singletonList(), Encoders.INT())
.foreach((ForeachFunction<Integer>) fooCount::add); try {
TimeUnit.DAYS.sleep( * );
} catch (InterruptedException e) {
e.printStackTrace();
} } }
启动的时候注意观察控制台上输出的Spark Web UI的地址:

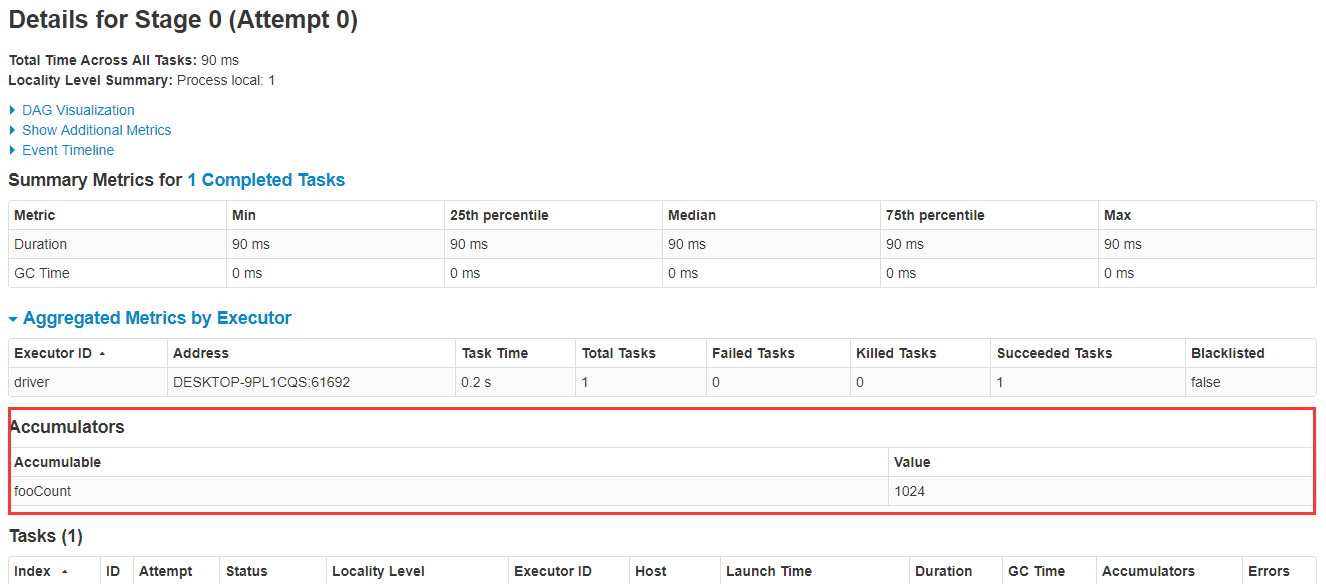
打开此链接,点进去Jobs-->Stage,可以看到fooCount累加器的值已经被累加到了1024:
二、Accumulator的简单使用
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.SparkContext;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.CollectionAccumulator;
import org.apache.spark.util.DoubleAccumulator;
import org.apache.spark.util.LongAccumulator; import java.util.Arrays; /**
* 累加器的基本使用
*
* @author CC11001100
*/
public class AccumulatorsSimpleUseDemo { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
SparkContext sc = spark.sparkContext(); // 内置的累加器有三种,LongAccumulator、DoubleAccumulator、CollectionAccumulator
// LongAccumulator: 数值型累加
LongAccumulator longAccumulator = sc.longAccumulator("long-account");
// DoubleAccumulator: 小数型累加
DoubleAccumulator doubleAccumulator = sc.doubleAccumulator("double-account");
// CollectionAccumulator:集合累加
CollectionAccumulator<Integer> collectionAccumulator = sc.collectionAccumulator("double-account"); Dataset<Integer> num1 = spark.createDataset(Arrays.asList(, , ), Encoders.INT());
Dataset<Integer> num2 = num1.map((MapFunction<Integer, Integer>) x -> {
longAccumulator.add(x);
doubleAccumulator.add(x);
collectionAccumulator.add(x);
return x;
}, Encoders.INT()).cache(); num2.count(); System.out.println("longAccumulator: " + longAccumulator.value());
System.out.println("doubleAccumulator: " + doubleAccumulator.value());
// 注意,集合中元素的顺序是无法保证的,多运行几次发现每次元素的顺序都可能会变化
System.out.println("collectionAccumulator: " + collectionAccumulator.value()); } }
三、自定义Accumulator
当内置的Accumulator无法满足要求时,可以继承AccumulatorV2实现自定义的累加器。
实现自定义累加器的步骤:
1. 继承AccumulatorV2,实现相关方法
2. 创建自定义Accumulator的实例,然后在SparkContext上注册它
假设要累加的数非常大,内置的LongAccumulator已经无法满足需求,下面是一个简单的例子用来累加BigInteger:
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.SparkContext;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.AccumulatorV2; import java.math.BigInteger;
import java.util.Arrays;
import java.util.List; /**
* 自定义累加器
*
* @author CC11001100
*/
public class CustomAccumulatorDemo { // 需要注意的是累加操作不能依赖顺序,比如类似于StringAccumulator这种则会得到错误的结果
public static class BigIntegerAccumulator extends AccumulatorV2<BigInteger, BigInteger> { private BigInteger num = BigInteger.ZERO; public BigIntegerAccumulator() {
} public BigIntegerAccumulator(BigInteger num) {
this.num = new BigInteger(num.toString());
} @Override
public boolean isZero() {
return num.compareTo(BigInteger.ZERO) == ;
} @Override
public AccumulatorV2<BigInteger, BigInteger> copy() {
return new BigIntegerAccumulator(num);
} @Override
public void reset() {
num = BigInteger.ZERO;
} @Override
public void add(BigInteger num) {
this.num = this.num.add(num);
} @Override
public void merge(AccumulatorV2<BigInteger, BigInteger> other) {
num = num.add(other.value());
} @Override
public BigInteger value() {
return num;
}
} public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
SparkContext sc = spark.sparkContext(); // 直接new自定义的累加器
BigIntegerAccumulator bigIntegerAccumulator = new BigIntegerAccumulator();
// 然后在SparkContext上注册一下
sc.register(bigIntegerAccumulator, "bigIntegerAccumulator"); List<BigInteger> numList = Arrays.asList(new BigInteger(""), new BigInteger(""), new BigInteger(""));
Dataset<BigInteger> num = spark.createDataset(numList, Encoders.kryo(BigInteger.class));
Dataset<BigInteger> num2 = num.map((MapFunction<BigInteger, BigInteger>) x -> {
bigIntegerAccumulator.add(x);
return x;
}, Encoders.kryo(BigInteger.class)); num2.count();
System.out.println("bigIntegerAccumulator: " + bigIntegerAccumulator.value()); } }
思考:内置的累加器LongAccumulator、DoubleAccumulator、CollectionAccumulator和我上面的自定义BigIntegerAccumulator,它们都有一个共同的特点,就是最终的结果不受累加数据顺序的影响(对于CollectionAccumulator来说,可以简单的将结果集看做是一个无序Set),看到网上有博主举例子StringAccumulator,这个就是一个错误的例子,就相当于开了一百个线程,每个线程随机sleep若干毫秒然后往StringBuffer中追加字符,最后追加出来的字符串是无法被预测的。总结一下就是累加器的最终结果应该不受累加顺序的影响,否则就要重新审视一下这个累加器的设计是否合理。
四、使用Accumulator的陷阱
来讨论一下使用累加器的一些陷阱,累加器的累加是在Task中进行的,而这些Task就是我们在Dataset上调用的一些算子操作,这些算子操作有Transform的,也有Action的,来探讨一下不同类型的算子对Accumulator有什么影响。
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.SparkContext;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.LongAccumulator; import java.util.Arrays; /**
* 累加器使用的陷阱
*
* @author CC11001100
*/
public class AccumulatorTrapDemo { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
SparkContext sc = spark.sparkContext();
LongAccumulator longAccumulator = sc.longAccumulator("long-account"); // ------------------------------- 在transform算子中的错误使用 ------------------------------------------- Dataset<Integer> num1 = spark.createDataset(Arrays.asList(, , ), Encoders.INT());
Dataset<Integer> nums2 = num1.map((MapFunction<Integer, Integer>) x -> {
longAccumulator.add();
return x;
}, Encoders.INT()); // 因为没有Action操作,nums.map并没有被执行,因此此时广播变量的值还是0
System.out.println("num2 1: " + longAccumulator.value()); // 0 // 调用一次action操作,num.map得到执行,广播变量被改变
nums2.count();
System.out.println("num2 2: " + longAccumulator.value()); // 3 // 又调用了一次Action操作,广播变量所在的map又被执行了一次,所以累加器又被累加了一遍,就悲剧了
nums2.count();
System.out.println("num2 3: " + longAccumulator.value()); // 6 // ------------------------------- 在transform算子中的正确使用 ------------------------------------------- // 累加器不应该被重复使用,或者在合适的时候进行cache断开与之前Dataset的血缘关系,因为cache了就不必重复计算了
longAccumulator.setValue();
Dataset<Integer> nums3 = num1.map((MapFunction<Integer, Integer>) x -> {
longAccumulator.add();
return x;
}, Encoders.INT()).cache(); // 注意这个地方进行了cache // 因为没有Action操作,nums.map并没有被执行,因此此时广播变量的值还是0
System.out.println("num3 1: " + longAccumulator.value()); // 0 // 调用一次action操作,广播变量被改变
nums3.count();
System.out.println("num3 2: " + longAccumulator.value()); // 3 // 又调用了一次Action操作,因为前一次调用count时num3已经被cache,num2.map不会被再执行一遍,所以这里的值还是3
nums3.count();
System.out.println("num3 3: " + longAccumulator.value()); // 3 // ------------------------------- 在action算子中的使用 -------------------------------------------
longAccumulator.setValue();
num1.foreach(x -> {
longAccumulator.add();
});
// 因为是Action操作,会被立即执行所以打印的结果是符合预期的
System.out.println("num4: " + longAccumulator.value()); // } }
五、Accumulator使用的奇淫技巧
累加器并不是只能用来实现加法,也可以用来实现减法,直接把要累加的数值改成负数就可以了:
package cc11001100.spark.sharedVariables.accumulators; import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.LongAccumulator; import java.util.Arrays; /**
* 使用累加器实现减法
*
* @author CC11001100
*/
public class AccumulatorSubtraction { public static void main(String[] args) { SparkSession spark = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Integer> nums = spark.createDataset(Arrays.asList(, , , , , , , ), Encoders.INT());
LongAccumulator longAccumulator = spark.sparkContext().longAccumulator("AccumulatorSubtraction"); nums.foreach(x -> {
if (x % == ) {
longAccumulator.add(-);
} else {
longAccumulator.add();
}
});
System.out.println("longAccumulator: " + longAccumulator.value()); // } }
Spark累加器(Accumulator)的更多相关文章
- Spark累加器(Accumulator)陷阱及解决办法
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变.累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数 ...
- Spark 累加器
由于spark是分布式的计算,所以使得每个task间不存在共享的变量,而为了实现共享变量spark实现了两种类型 - 累加器与广播变量, 对于其概念与理解可以参考:共享变量(广播变量和累加器).可能需 ...
- Spark累加器
spark累计器 因为task的执行是在多个Executor中执行,所以会出现计算总量的时候,每个Executor只会计算部分数据,不能全局计算. 累计器是可以实现在全局中进行累加计数. 注意: 累加 ...
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- 入门大数据---Spark累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- Spark中自定义累加器Accumulator
1. 自定义累加器 自定义累加器需要继承AccumulatorParam,实现addInPlace和zero方法. 例1:实现Long类型的累加器 object LongAccumulatorPara ...
- pyspark中使用累加器Accumulator统计指标
评价分类模型的性能时需要用到以下四个指标 最开始使用以下代码计算,发现代码需要跑近一个小时,而且这一个小时都花在这四行代码上 # evaluate model TP = labelAndPreds.f ...
- spark的accumulator值保存在哪里?
答案:保存在driver端.因此需要对收集的信息的规模要加以控制,不宜过大.避免 driver端的outofmemory问题!!!
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
随机推荐
- LFU(最近最不常用)实现(python)
from collections import defaultdict, OrderedDict class Node: __slots__ = 'key', 'val', 'cnt' def __i ...
- Dubbbo
什么是Dubbo Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,SOA服务治理方案.简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需要用的,只有 ...
- CSP-J总结&题解
总结: 这一次,最后一次,还是不行啊. 文件操作方面:没有FCLOSE,血的教训. 考场复盘: 首先一二题没什么好讲的,秒切.但是第三题由于一开始看出来是完全背包,但是好像又不是,去年又有摆渡车阴影, ...
- HiveQL 查询
一.select ...... from 语句 1.使用正则表达式来指定列 1)从表stocks中选择symbol列和列名以price作为前缀的列 select symbol,`price.*` f ...
- ELK实践
一.ElasticSearch+FileBeat+Kibana搭建平台 在C# 里面运行程序,输出日志(xxx.log 文本文件)到FileBeat配置的路径下面. 平台搭建,参考之前的随笔. Fil ...
- RookeyFrame 隐藏 首次加载菜单 的伸缩动画
一进入系统,然后点击菜单“系统管理”,会看到展开的“系统设置”菜单,又缩回去了,每次都会有(处女座看到就想改). 隐藏这个动画的JS:jquery.easyui.min.js,这个JS里面有个方法“_ ...
- 红黑树 ------ luogu P3369 【模板】普通平衡树(Treap/SBT)
二次联通门 : luogu P3369 [模板]普通平衡树(Treap/SBT) 近几天闲来无事...就把各种平衡树都写了一下... 下面是红黑树(Red Black Tree) 喜闻乐见拿到了luo ...
- AtCoder Grand Contest 017题解
传送门 \(A\) 直接转移就是了 typedef long long ll; const int N=55; ll f[N][2];int a[N],n,p; int main(){ scanf(& ...
- C# 清除sqlite密码
C# 清除sqlite密码 .创建空的sqlite数据库. //数据库名的后缀你可以直接指定,甚至没有后缀都可以 //方法一:创建一个空sqlite数据库,用IO的方式 FileStream fs = ...
- 针对Model类的代码修剪器
直接用Mybatis Generator生成的Model类大概是这样的 package com.spldeolin.demoapp.po; import java.util.Date; import ...