从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片
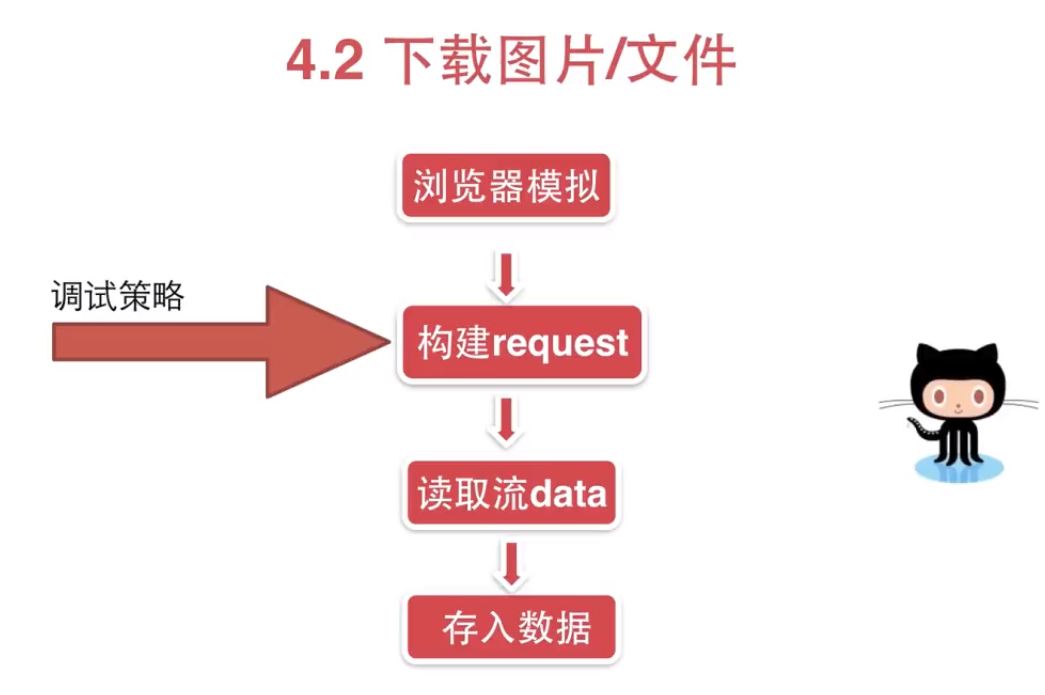
# coding=utf-8
import requests def download_imgage():
'''
demo: 下载图片
'''
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg"
response = requests.get(url,headers=headers, stream=True)
with open('demo.jpg', 'wb') as fd:
for chunk in response.iter_content(128):
fd.write(chunk) print response.content def download_image_improved():
# 伪造headers信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
# 限定url
url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg"
response = requests.get(url, headers=headers, stream=True)
# contextlib 管理上下文信息
from contextlib import closing
# 可以关闭文件流
with closing(requests.get(url, headers=headers, stream=True)) as response:
# 打开文件
with open('demo1.jpg', 'wb') as fd:
# 每128字节写入一次
for chunk in response.iter_content(128):
fd.write(chunk) if __name__ == '__main__':
# download_imgage()
download_image_improved()
从0开始学爬虫11之使用requests库下载图片的更多相关文章
- 从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证 此处我们使用github的token进行简单测试验证 # coding=utf-8 import requests BASE_URL = " ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 从0开始学爬虫2之json的介绍和使用
从0开始学爬虫2之json的介绍和使用 Json 一种轻量级的数据交换格式,通用,跨平台 键值对的集合,值的有序列表 类似于python中的dict Json中的键值如果是字符串一定要用双引号 jso ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
随机推荐
- java基础(8)---接口和lambda
一.接口 接口定义: 接口抽象方法定义: 二.接口实现类的定义.创建.调用 接口需要一个实现类. 接口实现类的定义: 接口实现类的创建和调用: 接口的好处: 不好的写法: 推荐的写法: 接口实 ...
- SpringBoot -基础学习笔记 - 01
SpringBoot个人笔记-szs 一.使用thymeleaf模板引擎来指定所需资源的位置 可以做到当项目名进行更改后,模板引擎也会进行更新相关的路径;如下图展示,会自动添加crud根目录! < ...
- 最快速的办法解决MySQL数据量增大之后翻页慢问题
MySQL最易碰到的性能问题就是数据量逐步增大之后的翻页速度变慢的额问题,而且越往后翻页速度越慢,如果用最快速的办法解决,以下就是解决办法,简单方便. 1.问题现状 现有MySQL数据表 event_ ...
- 错误:找不到或无法加载主类(myEclipse and IDEA)
一.myEclipse: 一个简单的main类启动时报无法加载主类的处理方法 1.找到Prolems--->Error--->右键Delete 2.点击项目,右键刷新 3.点击导航栏上的P ...
- oracle中日期相关的区间
and czrqb.lsrqb_rh_sj >= to_date('[?query_date_begin|2011-09-01?]A', 'yyyy-mm-dd') and czrqb.lsrq ...
- mysql 连接过多解决方案
方案1.登录mysql控制台:mysql -h192.168.20.199 -uroot -proot flush hosts 方案2.直接重启服务:service mysqld restart(暴力 ...
- 通过 ffmpeg 获取视频第一帧(指定时间)图片
最近做一个上传教学视频的方法,上传视频的同时需要上传视频缩略图,为了避免用户上传的缩略图与视频内容不符,经理要求直接从上传的视频中截图视频的某一帧作为缩略图,并给我推荐了FFMPEG.FFMPEG 功 ...
- mysql跨表删除多条记录
Mysql可以在一个sql语句中同时删除多表记录,也可以根据多个表之间的关系来删除某一个表中的记录. 假定我们有两张表:Product表和ProductPrice表.前者存在Product的基本信息, ...
- PPT扁平化设计总结
注:以下内容基本都来自知乎,由于已经不记得网址了,所以未能附上所有相关链接,抱歉. PPT扁平化设计原则一.亲密:意思相近的内容放在一起二.对齐:页面上的某两个元素之间总是围绕一条直线对齐三.对比:有 ...
- LightOJ-1275-Internet Service Providers(数学)
链接: https://vjudge.net/problem/LightOJ-1275 题意: A group of N Internet Service Provider companies (IS ...