分布式ID生成总结
1.数据库自增id
新建一个公共库,库里面新建一个序列表,主键id自增,每次请求增加数据都往这个表中插入数据,然后获取到id,然后使用即可。
优点:方便简单
缺点:单库生成自增id,高并发下,会有瓶颈
适用场景:
并发很低,几百/s,不会出现性能瓶颈
2.UUID
优点:本地生成,不基于任何第三方
缺点:
- 太长,作为数据库主键性能太差,不适合作为主键
- 不具有有序性,会导致B+树索引在写的时候有过多的随机写操作(连续的id可以产生部分顺序写)
- 写的时候不能产生有顺序的 append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显
适用场景:
随机生成文件名、编号,生成token等。
3.系统时间+拼接业务字段值
例如:当前时间戳 + 用户id + 业务含义编码,并发高的时候,会有重复,此时就不行了,不建议使用。
4.Redis
Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
- 依赖于redis,redis要是不稳定,会影响ID生成。
5.snowflake算法
twitter开源的分布式id生成算法,把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号,理论上最多支持1024台机器每秒生成4096000个序列号。
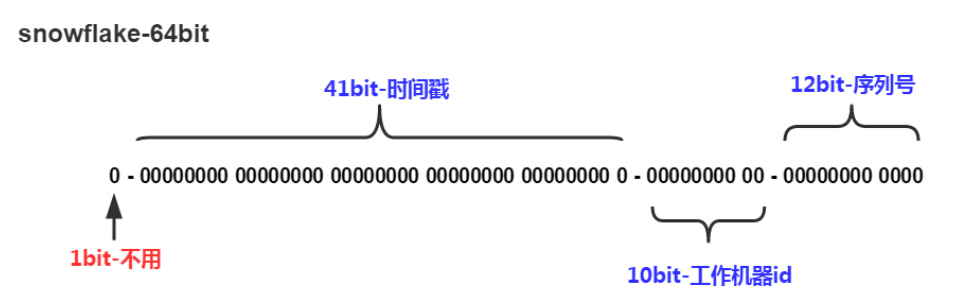
- 1 bit:不用
因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0 - 41 bit:表示的是时间戳,单位是ms
41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间 - 10 bit:记录工作机器id
代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器,但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。 - 12 bit:记录同一个毫秒内产生的不同id
12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
缺点:
依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序、ID重复
优点:
- 生成ID时不依赖于数据库,完全在内存生成,高性能高可用
- 容量大,每秒可生成几百万ID
- ID呈趋势递增,后续插入数据库的索引树的时候,性能较高
分布式ID生成总结的更多相关文章
- 一种基于Orleans的分布式Id生成方案
基于Orleans的分布式Id生成方案,因Orleans的单实例.单线程模型,让这种实现变的简单,贴出一种实现,欢迎大家提出意见 public interface ISequenceNoGenerat ...
- 细聊分布式ID生成方法
细聊分布式ID生成方法 https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=403837240&idx=1&sn=ae9 ...
- spring boot / cloud (十六) 分布式ID生成服务
spring boot / cloud (十六) 分布式ID生成服务 在几乎所有的分布式系统或者采用了分库/分表设计的系统中,几乎都会需要生成数据的唯一标识ID的需求, 常规做法,是使用数据库中的自动 ...
- Leaf——美团点评分布式ID生成系统 UUID & 类snowflake
Leaf——美团点评分布式ID生成系统 https://tech.meituan.com/MT_Leaf.html
- 分布式ID生成系统 UUID与雪花(snowflake)算法
Leaf——美团点评分布式ID生成系统 -https://tech.meituan.com/MT_Leaf.html 网游服务器中的GUID(唯一标识码)实现-基于snowflake算法-云栖社区-阿 ...
- Leaf:美团分布式ID生成服务开源
Leaf是美团基础研发平台推出的一个分布式ID生成服务,名字取自德国哲学家.数学家莱布尼茨的一句话:“There are no two identical leaves in the world.”L ...
- 分布式ID生成方法-趋势有序的全局唯一ID
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
- 【58沈剑架构系列】细聊分布式ID生成方法
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
- 分布式ID生成方案
系统唯一ID是设计一个系统的时候常常会遇到的问题,也常常为这个问题而纠结. 生成ID的方法有很多,适应不同的场景.需求以及性能要求.所以有些比较复杂的系统会有多个ID生成的策略. 0. 分布式ID要求 ...
- 160302、细聊分布式ID生成方法
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
随机推荐
- Java精通并发-Lock与synchronized关键字在底层的区别及实例分析
在上两次中已经将Lock这个接口的整个官方说明进行了阅读,这次来了解一下它的一个非常重要的实现类: 啥叫“可重入”呢?其实是指一个线程已经拿到了锁,然后该线程还能再次获取这把锁,接下来在了解它之前先用 ...
- python测试开发django-68.templates模板标签{% for %}
前言 有些标签类似这样: {% tag %} ,需要开始和结束标签 例如:{% tag %} ...标签 内容 ... {% endtag %},一般用于循环列表对象输出内容. for 标签 {% f ...
- git 学习记录—— git 中的仓库、文件状态、修改和提交操作等
最近开始学习使用版本控制工具 git .学习方式主要通过阅读 git 网站上的 Pro git 和动手实践,使用的系统为 Ubuntu16.04LTS,以及 Windows 8.1. 本文主要关注 ...
- Spring Cloud 组件 —— gateway
Spring Cloud 网关主要有三大模块:route.predicates.filters 其中 filter 最为关键,是功能增强的核心组件. 列举出一些功能组件: 5.6 CircuitBre ...
- Generative Adversarial Networks overview(2)
Libo1575899134@outlook.com Libo (原创文章,转发请注明作者) 本文章会先从Gan的简单应用示例讲起,从三个方面问题以及解决思路覆盖25篇GAN论文,第二个大部分会进一步 ...
- codeforces1267G
考虑我们在某个时刻,剩下的数有 $ i $ 个,这些数的和为 $ j $,那么我们期望要抽 $ n \over i $ 次才能取到一个新的物品,这个物品的期望权值为 $ j \over i $,我们花 ...
- Windows 10中的CSC.exe、CSC.rsp
(1)CSC.exe位置 [4.0的位于] C:\Windows\Microsoft.NET\Framework\v4.0.30319 [之后版本的位于] C:\Program Files (x86) ...
- haproxy 2.0 dataplaneapi rest api 试用
我们可以基于haproxy 提供的dataplaneapi 动态进行haproxy 配置的修改,增强haproxy的可编程能力,以下是一个简单 的测试,基于docker-compose运行 环境准备 ...
- 发布jar包到远端github仓库使用(将github仓库当作maven仓库)
今天把单点登陆的core模块搬到了github仓库 并且利用github仓库作为maven仓库 在项目中进行了引用 1. 起初看技术博客没有完全引入进来,调整了一下OK了 2. 还可以将其他模块或者工 ...
- Centos7 更改yum源与更新系统
[1] 首先备份 /etc/yum.repos.d/CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/Cen ...